清华朱军团队Nature Machine Intelligence:多模态扩散模型实现心血管信号实时全面监测
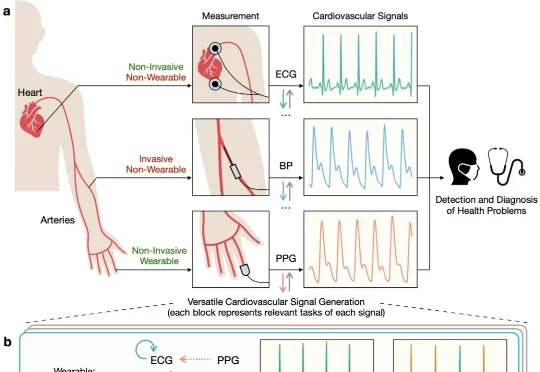
清华朱军团队Nature Machine Intelligence:多模态扩散模型实现心血管信号实时全面监测近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。
来自主题: AI技术研报
9765 点击 2025-12-30 15:14
 搜索
搜索
近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。
硅谷宠物情感智能公司Traini宣布已完成超5000万元人民币融资,资金将主要用于多模态情感模型研发、软硬件产品迭代及海外市场扩张。老股东Tao Foundation及小米联合创始人洪峰继续跟投。

近日,多模态视频理解领域迎来重磅更新!由复旦大学、上海财经大学、南洋理工大学联合打造的 MeViSv2 数据集正式发布,并已被顶刊 IEEE TPAMI 录用。
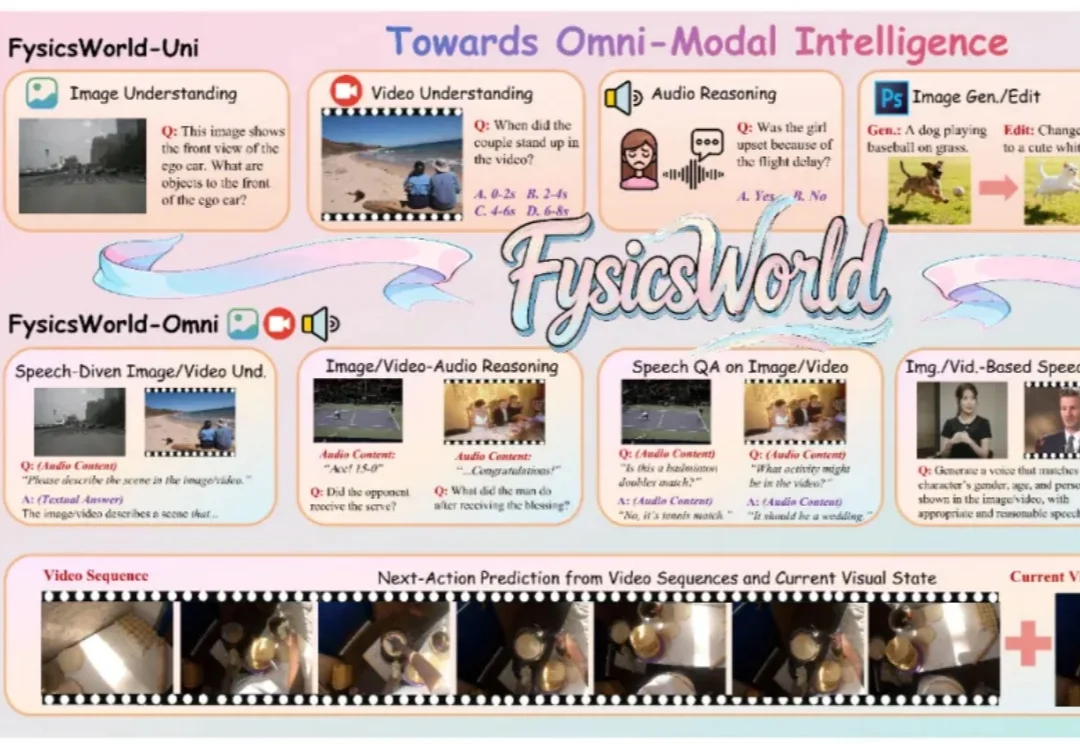
近年来,多模态大语言模型正在经历一场快速的范式转变,新兴研究聚焦于构建能够联合处理和生成跨语言、视觉、音频以及其他潜在感官模态信息的统一全模态大模型。此类模型的目标不仅是感知全模态内容,还要将视觉理解和生成整合到统一架构中,从而实现模态间的协同交互。

能自动查数据、写分析、画专业金融图表的AI金融分析师来了!最近,中国人民大学高瓴人工智能学院提出了一个面向真实金融投研场景的多模态研报生成系统——玉兰·融观(Yulan-FinSight)。

最近,清华大学教授、智谱AI首席科学家唐杰发了一条长微博,总结了自己2025年对大模型进展的感悟。从预训练到中后训练、长尾场景的对齐能力,再到Agent、多模态和具身智能的发展,其中有不少亮点。
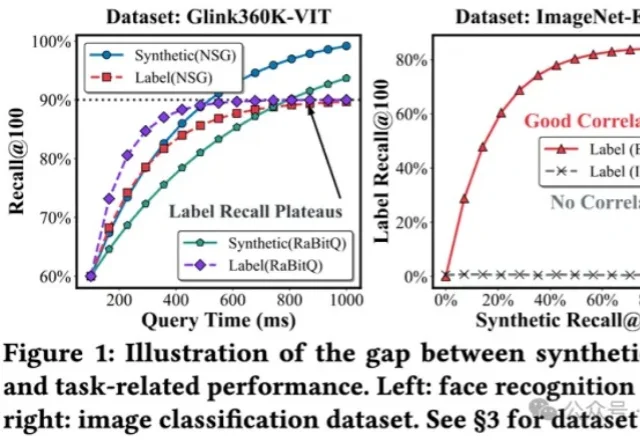
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。

「高烧」三年后,AI行业终于冷静:Scaling红利即将耗尽,单纯堆参数绝非良药。但商汤已胸有成竹。

多模态大语言模型(MLLMs)已成为AI视觉理解的核心引擎,但其在真实世界视觉退化(模糊、噪声、遮挡等)下的性能崩溃,始终是制约产业落地的致命瓶颈。

今天,在 FORCE 原动力大会上,火山引擎发布豆包大模型1.8、豆包视频生成模型 Seedance 1.5 pro。经过一年多的持续升级,豆包大模型家族在多模态理解和生成能力、Agent 能力上,已位于全球第一梯队。