全球最大开源具身大模型!中国机器人跑完马拉松后开始学思考
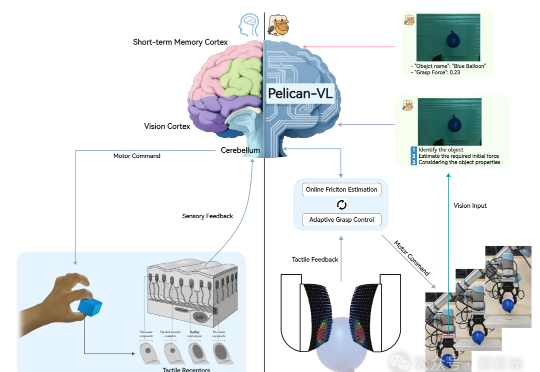
全球最大开源具身大模型!中国机器人跑完马拉松后开始学思考昨天,全球参数量最大的具身智能多模态大模型——Pelican-VL 1.0正式开源。它不仅覆盖了7B到72B级别,能够同时理解图像、视频和语言指令,并将这些感知信息转化为可执行的物理操作。
来自主题: AI资讯
9516 点击 2025-11-15 10:18
 搜索
搜索
昨天,全球参数量最大的具身智能多模态大模型——Pelican-VL 1.0正式开源。它不仅覆盖了7B到72B级别,能够同时理解图像、视频和语言指令,并将这些感知信息转化为可执行的物理操作。
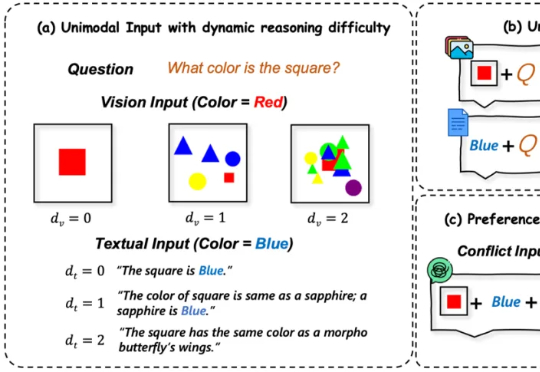
多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。 然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following)
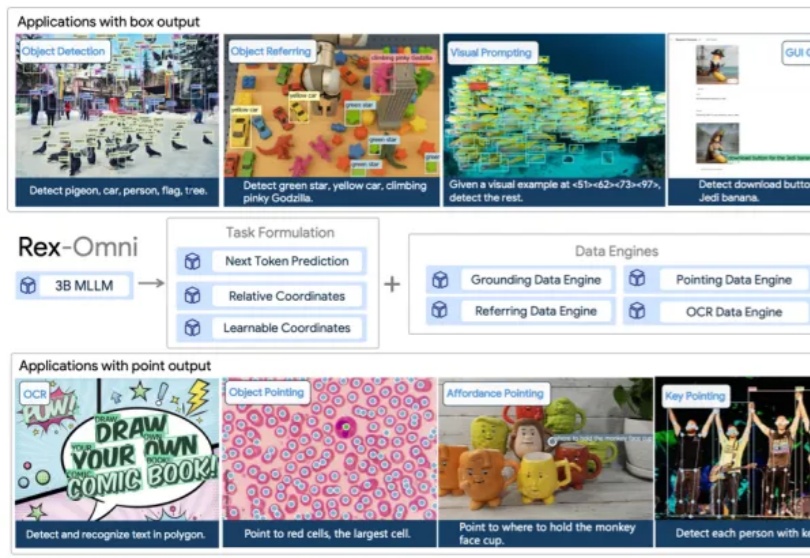
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。

当前视频检索研究正陷入一个闭环困境:以MSRVTT为代表的窄域基准,长期主导模型在粗粒度文本查询上的优化,导致训练数据有偏、模型能力受限,难以应对真实世界中细粒度、长上下文、多模态组合等复杂检索需求。
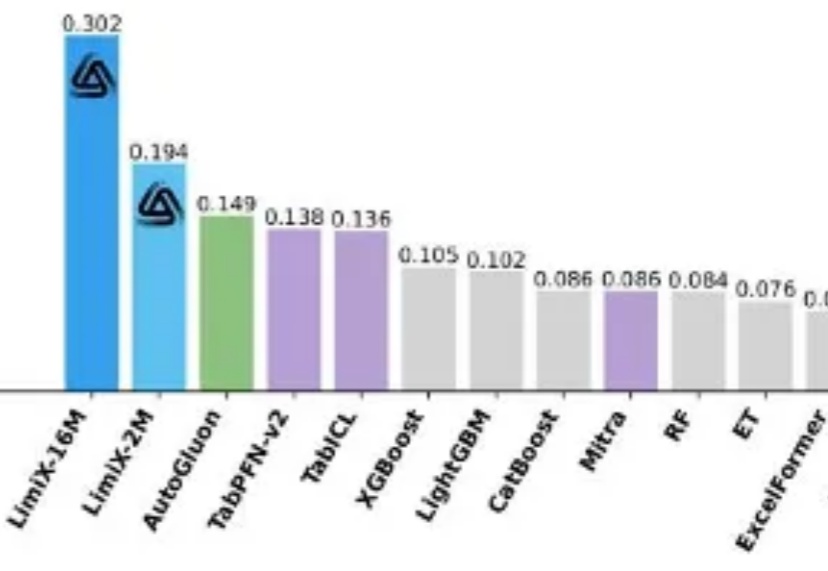
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。

Marble,终于来了。 没错,就是两个月前在 AI 圈刷屏的那个 3D 世界生成模型。就在刚刚,李飞飞旗下的 World Labs 公司官宣向全体用户开放,还一次性放出了一大波新功能。 多模态生成:
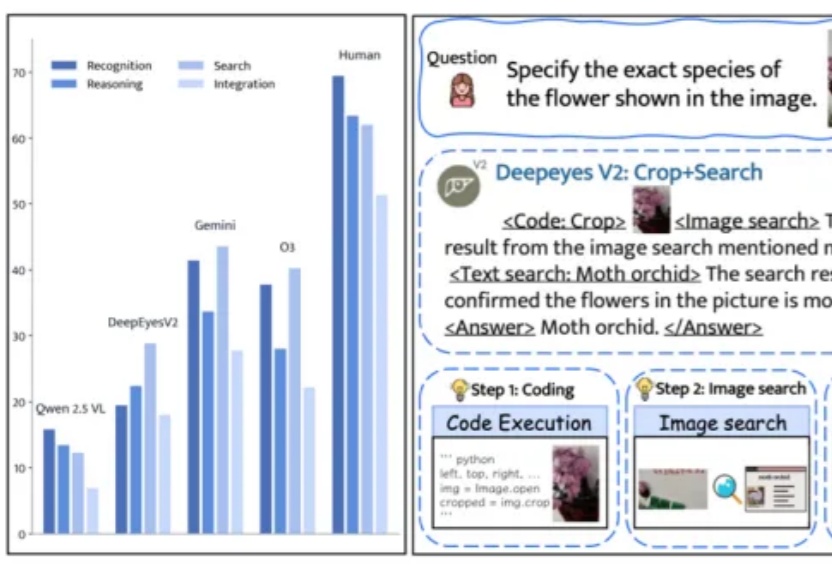
还记得今年上半年小红书团队推出的DeepEyes吗?

就在今天,罗福莉以C位之姿,首次对外官宣了小米任职。刚刚,罗福莉在X上高调宣布——正式加入小米,出任MiMo团队负责人。智能的进化必然会从语言世界走向物理世界,解锁多模态的空间智能——具备感知、推理、生成与行动的能力,这是实现真正通用人工智能(AGI)的关键一步。

华中科技大学团队推出首个水下多模态大模型NAUTILUS,支持8种水下场景理解任务,并开源145万图文对的NautData数据集。模型通过视觉特征增强模块解决水下图像模糊和颜色失真问题,性能超越现有模型,恶劣环境下表现更佳。
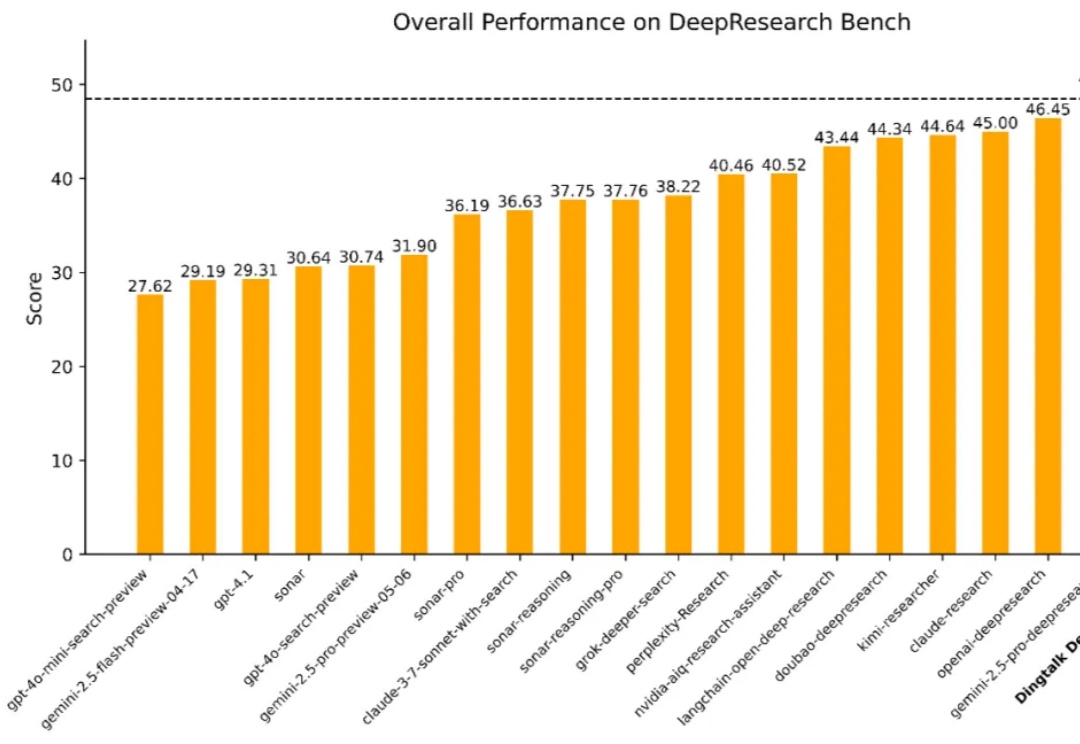
在数字经济浪潮中,企业对于高效、精准的信息获取与决策支持的需求日益迫切。从前沿科学探索到行业趋势分析,再到企业级决策支持,一个能够从海量异构数据源中提取关键知识、执行多步骤推理并生成结构化或多模态输出的「深度研究系统」正变得不可或缺。