AAAI 2026 Oral | 悉尼科技大学联合港理工打破「一刀切」,联邦推荐如何实现「千人千面」的图文融合?
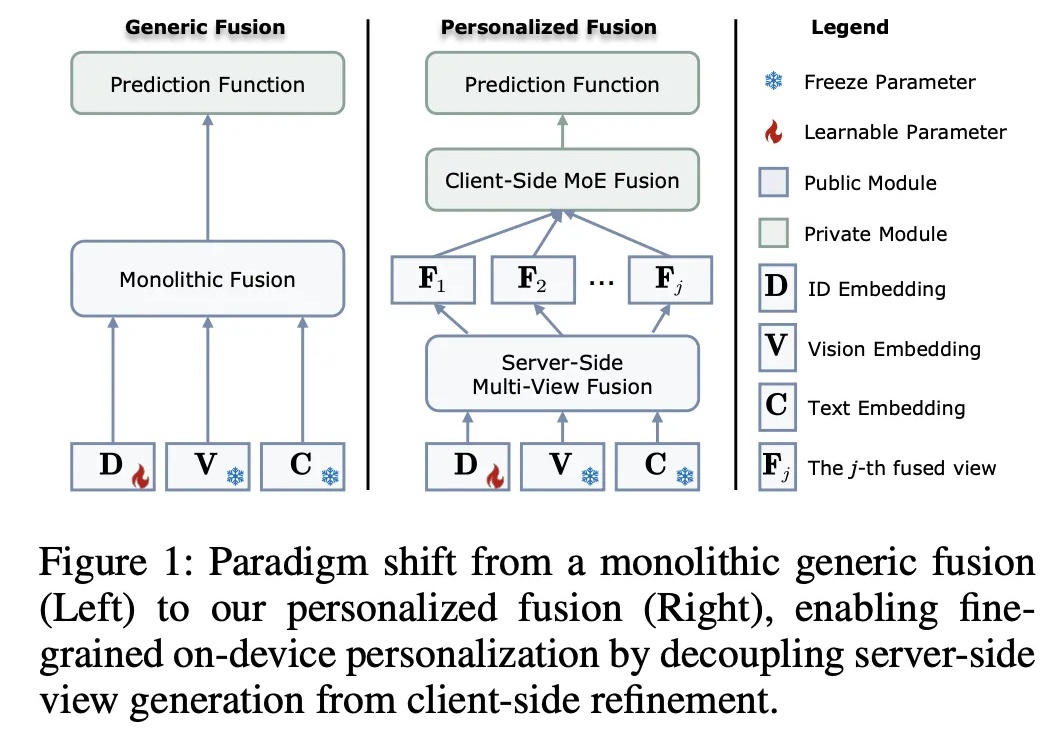
AAAI 2026 Oral | 悉尼科技大学联合港理工打破「一刀切」,联邦推荐如何实现「千人千面」的图文融合?在推荐系统迈向多模态的今天,如何兼顾数据隐私与个性化图文理解?悉尼科技大学龙国栋教授团队联合香港理工大学杨强教授、张成奇教授团队,提出全新框架 FedVLR。该工作解决了联邦环境下多模态融合的异质性难题,已被人工智能顶级会议 AAAI 2026 接收为 Oral Presentation。
来自主题: AI技术研报
9100 点击 2025-11-25 15:30