
松下发布多模态大模型OmniFlow,文本、图像、音频随意切换
松下发布多模态大模型OmniFlow,文本、图像、音频随意切换随着大模型的不断发展,多模态数据处理成为了新的热点领域。多模态生成任务主要通过整合多种类型的数据,如文本、图像、音频等,实现不同模态之间的相互转换与生成。
来自主题: AI资讯
8565 点击 2025-06-17 11:39
 搜索
搜索
随着大模型的不断发展,多模态数据处理成为了新的热点领域。多模态生成任务主要通过整合多种类型的数据,如文本、图像、音频等,实现不同模态之间的相互转换与生成。

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
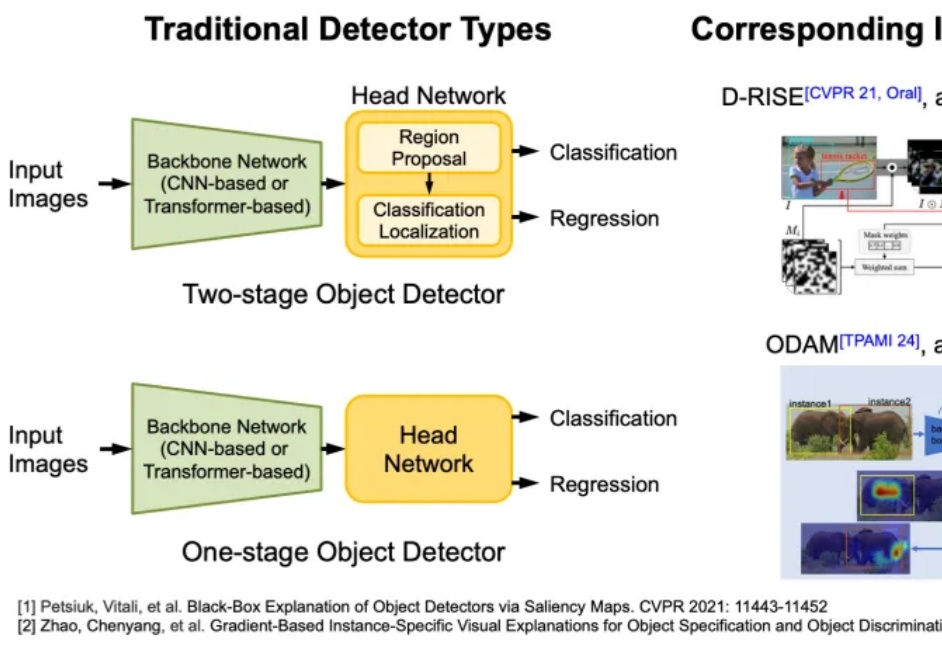
AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。

在金融科技智能化转型进程中,大语言模型以及多模态大模型(LVLM)正成为核心技术驱动力。尽管 LVLM 展现出卓越的跨模态认知能力

AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。

「市象」获悉,段楠已在其GitHub主页悄然更新履历:现任京东探索研究院视觉与多模态实验室负责人,带领研究团队研发视觉和多模态基础模型。此前,他曾任阶跃星辰Technical Fellow(2024-2025)和微软亚洲研究院自然语言计算团队资深首席研究员和研究经理(2012-2024)。

豆包大模型1.6惊艳亮相,成为国内首款多模态SOTA模型,256k对话窗口,深度思考最长上下文。它不仅能看会想,还能动手操作GUI,国内最有潜力考清北。

普林斯顿大学AI实验室与复旦大学历史学系联手推出了全球首个聚焦历史研究能力的AI评测基准——HistBench,并同步开发了深度嵌入历史研究场景的AI助手——HistAgent。这一成果不仅填补了人文学科AI测试的空白,更为复杂史料处理与多模态理解建立了系统工具框架。
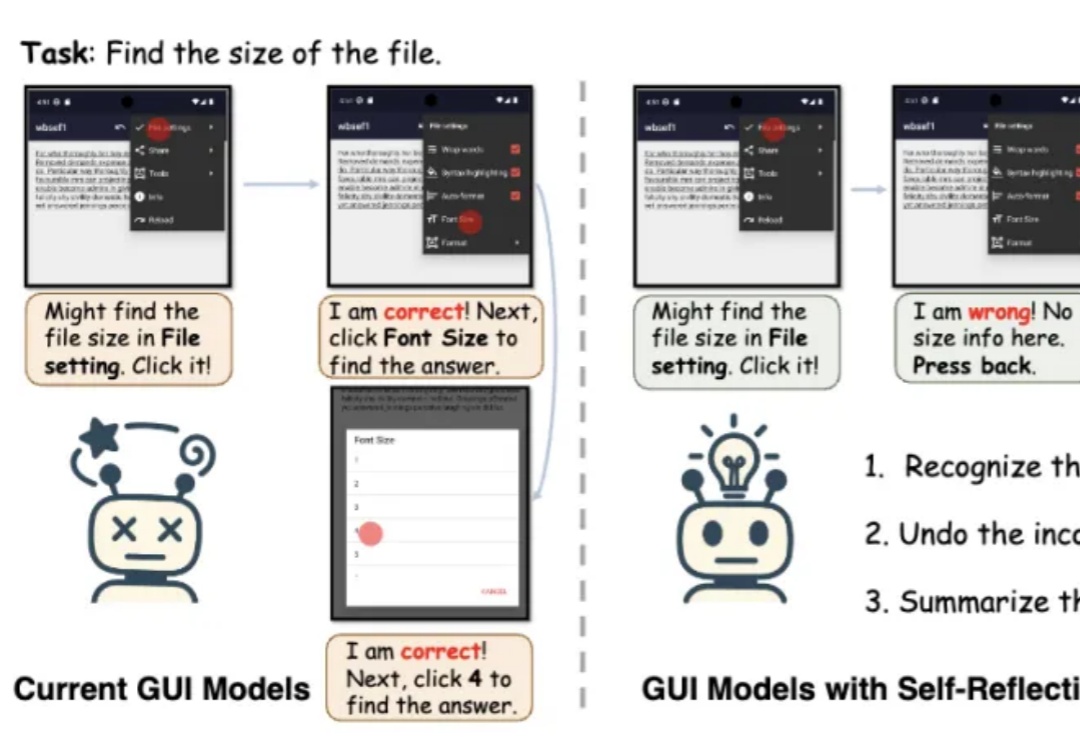
端到端多模态GUI智能体有了“自我反思”能力!南洋理工大学MMLab团队提出框架GUI-Reflection。
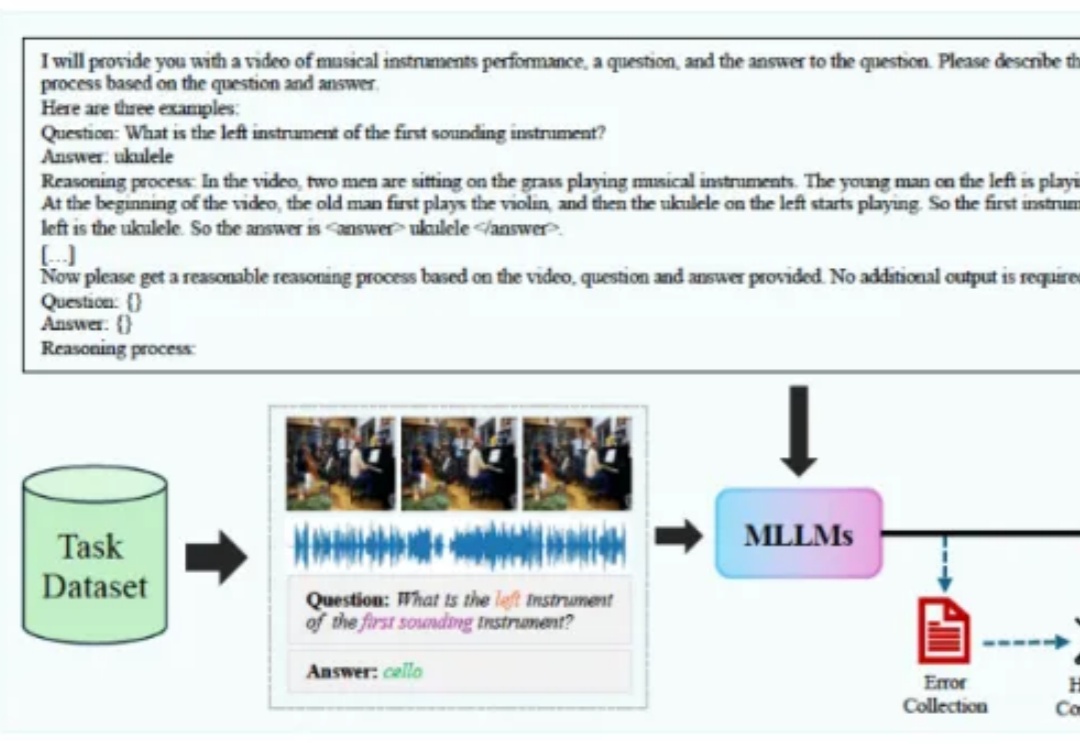
我们人类生活在一个充满视觉和音频信息的世界中,近年来已经有很多工作利用这两个模态的信息来增强模型对视听场景的理解能力,衍生出了多种不同类型的任务,它们分别要求模型具备不同层面的能力。