“甲方快乐模型”诞生,拿下平面设计新SOTA!多条件一键生成,还能独立调整元素 | 复旦&字节
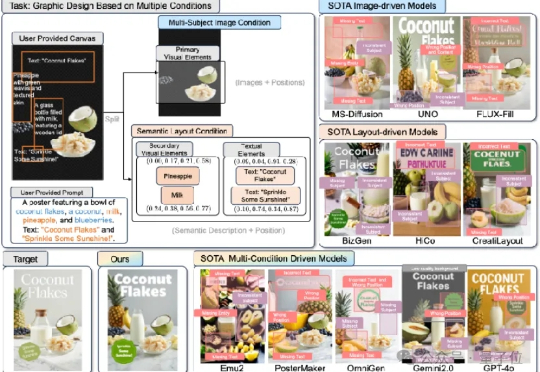
“甲方快乐模型”诞生,拿下平面设计新SOTA!多条件一键生成,还能独立调整元素 | 复旦&字节平面设计师有救了! 复旦大学和字节跳动团队联合提出CreatiDesign新模型,可实现高精度、多模态、可编辑的AI图形设计生成。
来自主题: AI技术研报
9178 点击 2025-06-11 16:18
 搜索
搜索
平面设计师有救了! 复旦大学和字节跳动团队联合提出CreatiDesign新模型,可实现高精度、多模态、可编辑的AI图形设计生成。
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。
大模型≠随机鹦鹉!Nature子刊最新研究证明: 大模型内部存在着类似人类对现实世界概念的理解。

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。
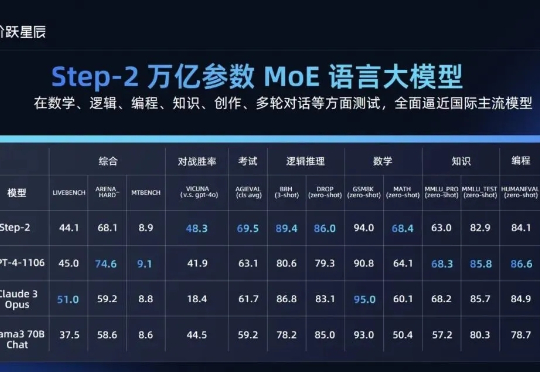
本期内容是拾象 CEO 李广密对大模型公司阶跃星辰首席科学家张祥雨的访谈。

多模态检索是信息理解与获取的关键技术,但其中的跨模态干扰问题一直是一大难题。

刚发布就全网刷屏的 Kontext 靠“一致性”和“多模态理解”硬刚 OpenAI,在视觉生成界引发了一波震动。
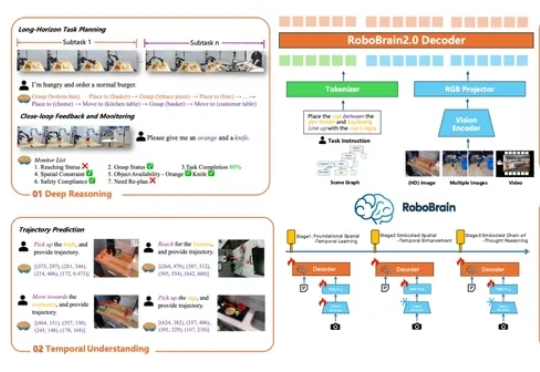
大模型的发展正在遭遇瓶颈。随着互联网文本数据被大规模消耗,基于数字世界训练的AI模型性能提升速度明显放缓。与此同时,物理世界中蕴藏着数字世界数百倍甚至千倍的多模态数据,这些数据远未被有效利用,成为AI发展的下一个重要方向。
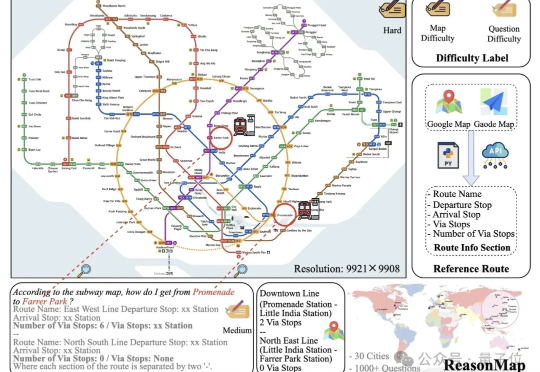
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。