字节开源了一个了不得的模型!
字节开源了一个了不得的模型!字节跳动开源了一个口碑还不错的模型——BAGEL (ByteDance Agnostic Generation and Empathetic Language model), 一个统一多模态基础模型。啥叫“统一”?一个模型就能同时理解和生成文本、图像、视频!
来自主题: AI资讯
9133 点击 2025-05-31 13:45
 搜索
搜索
字节跳动开源了一个口碑还不错的模型——BAGEL (ByteDance Agnostic Generation and Empathetic Language model), 一个统一多模态基础模型。啥叫“统一”?一个模型就能同时理解和生成文本、图像、视频!

多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。

EfficientLLM项目聚焦LLM效率,提出三轴分类法和六大指标,实验包揽全架构、多模态、微调技术,可为研究人员提供效率与性能平衡的参考。

当前顶尖AI模型是否真能“看懂”物理图像?

Google I/O 2025 结束后,Google CEO Sundar Pichai 接受了《The Verge》主编专访,这也是双方连续第三年于 I/O 后展开对谈,而今年的背景更为特殊:Gemini 模型全面更新、多模态生成工具 Veo3 登场、AI 功能深度融入 Android 与 XR 平台,Google 展现出前所未有的产品化信心。

近期,具身智能公司「优理奇机器人 UniX AI」完成数亿元天使轮及天使+轮融资,中关村前沿基金,赛纳资本及长安私人资本参与本轮融资。本轮融资将用于加速研发多模态具身智能大模型与通用机器人本体的同步演进,以及面向多个泛商业服务和C端场景落地与交付。
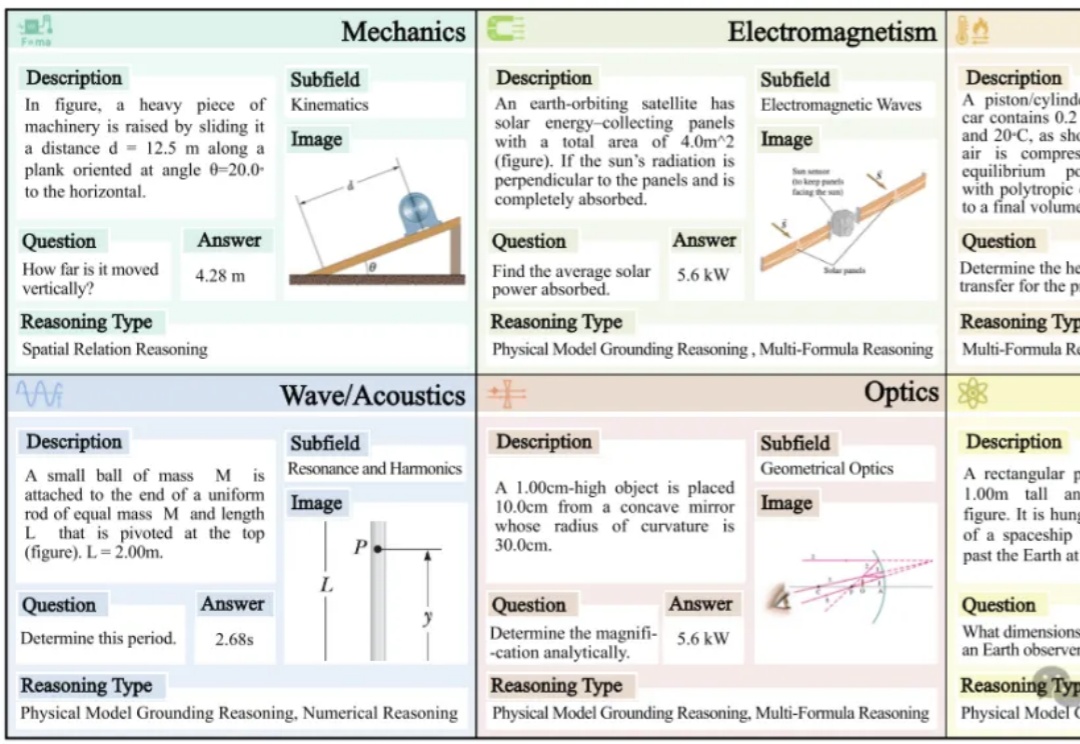
表现最好的GPT-o4 mini,物理推理能力也远不及人类!

在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
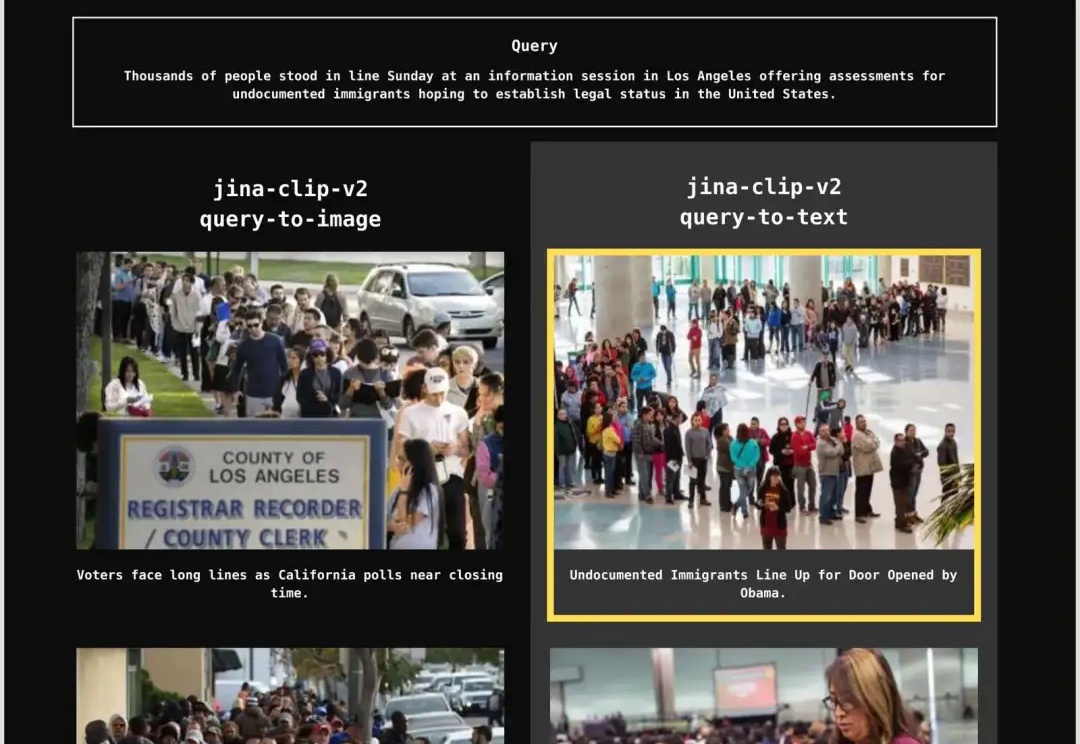
当你在搜索“中国队在多哈乒乓球锦标赛的成绩”时,一篇新闻报道的文本部分和你的查询的相关性是 0.7,配图的相关性 0.5;另一篇则是文本相关性为 0.6,图片也是 0.6。那么,哪一篇报道才是你真正想要的呢?
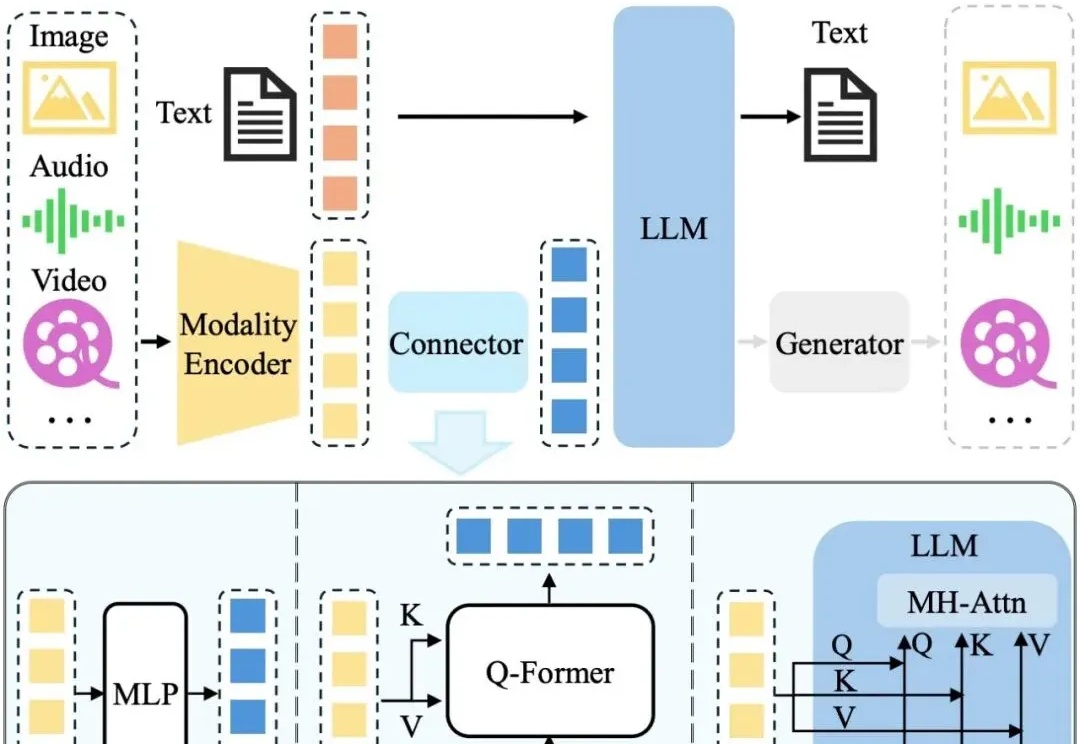
近年来,LLM 及其多模态扩展(MLLM)在多种任务上的推理能力不断提升。然而, 现有 MLLM 主要依赖文本作为表达和构建推理过程的媒介,即便是在处理视觉信息时也是如此 。