教大模型终身学习!中科大连发两篇顶会,突破「知识注入」双重困境
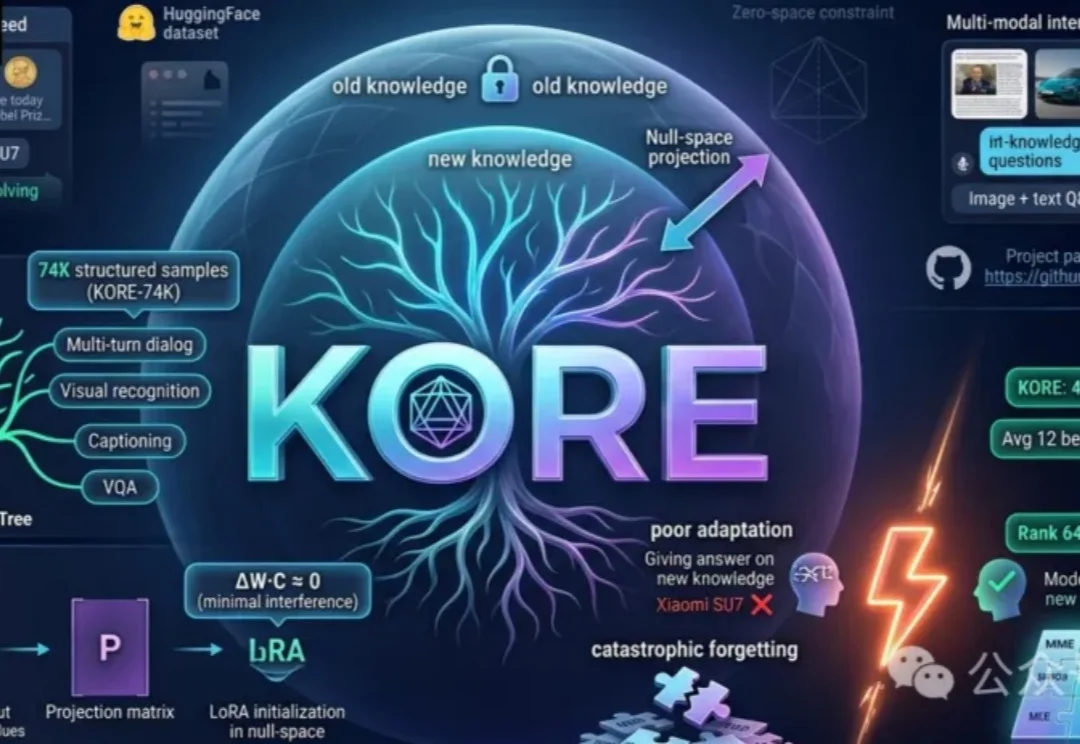
教大模型终身学习!中科大连发两篇顶会,突破「知识注入」双重困境中科大团队首先推出动态多模态知识注入基准MMEVOKE,解构遗忘机制,并在此基础上提出全新双阶段框架KORE。通过「知识树」自动增强与「零空间」协方差约束微调,为大模型终身学习开辟了全新路径。
来自主题: AI技术研报
10001 点击 2026-05-22 09:28
 搜索
搜索
中科大团队首先推出动态多模态知识注入基准MMEVOKE,解构遗忘机制,并在此基础上提出全新双阶段框架KORE。通过「知识树」自动增强与「零空间」协方差约束微调,为大模型终身学习开辟了全新路径。
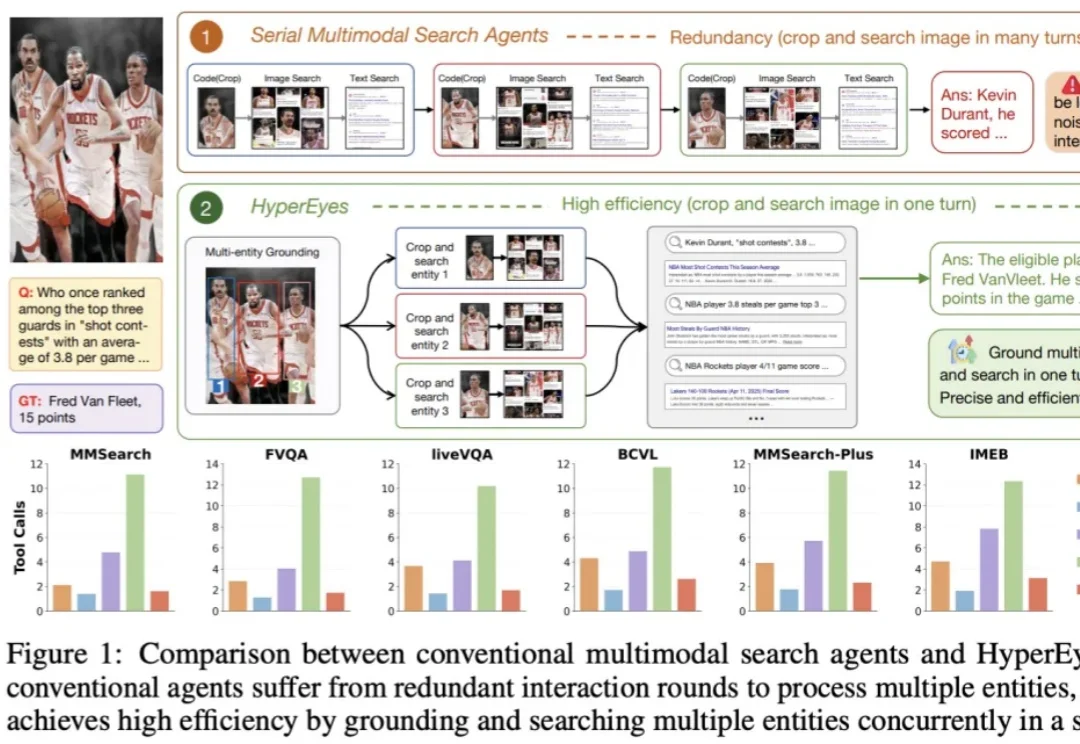
现有的开源多模态搜索智能体普遍受困于「裁剪 - 再搜索」的串行处理模式,面对多目标时往往陷入交互冗长、错误级联累积的泥沼。
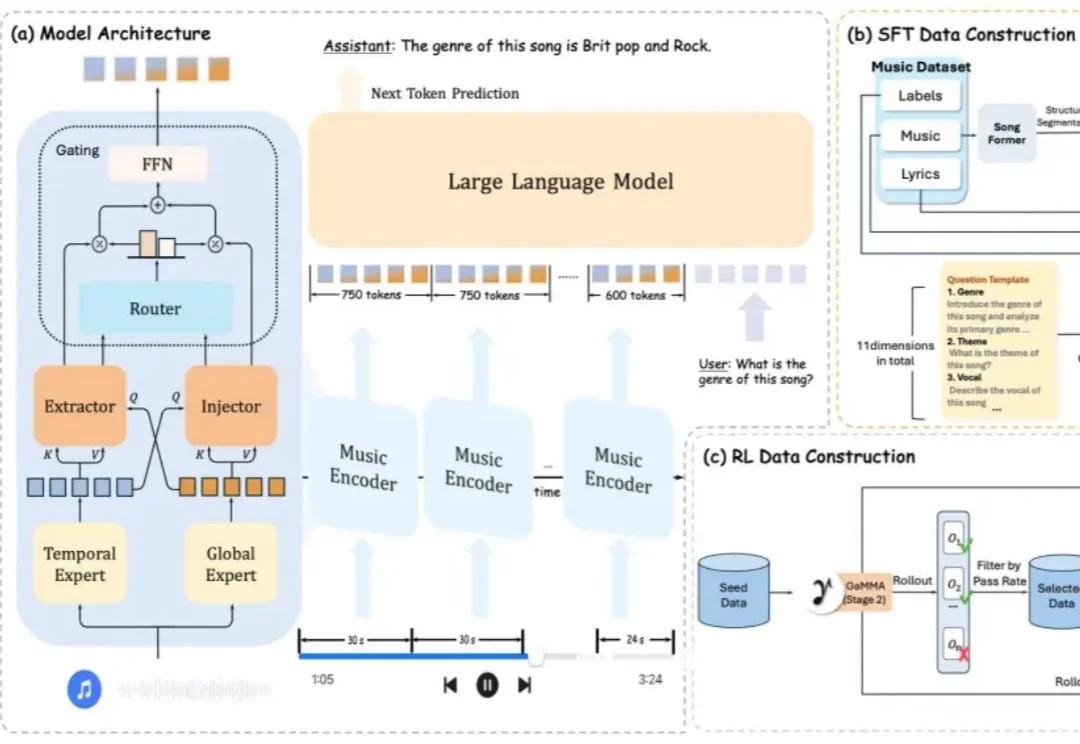
大模型的能力边界正在不断拓展,从文字到视觉,再到音频,全模态理解已渐成现实。然而,当你问一个多模态大模型「这首歌的高潮从第几秒开始?」或者「第 30 秒之后乐器编配发生了什么变化?」,得到的往往是一个模糊甚至错误的回答。

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。
最近,创作者平台 Wirestock 宣布完成 2300 万美元 Series A 融资,由 Nava Ventures 领投,SBVP(Sheryl Sandberg 参与创立)、Formula VC 与 I2BF Ventures 参投,公司累计融资规模达到约 2600 万美元。

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。
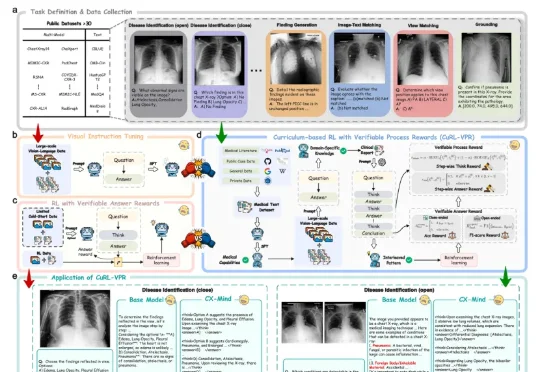
上海交通大学、上海创智学院与瑞金医院联合发布的CX-Mind,是目前首个将胸片诊断推进为「可验证推理链」的多模态大模型——从看到异常,到解释为什么、排除了什么、结论怎么来的,每一步都有影像证据支撑。
当 AI 行业的目光集中在 Agent、工具调用、长程任务这些上层应用之时,底层的多模态架构正在经历一次更安静、也更彻底的范式转变 —— 它要回答的是一个看似朴素的问题:理解与生成,是否天生就该是两件事?

开普勒机器人前 CEO 胡德波已开启具身智能赛道的第二次创业,新公司名为「索塔无界」。这一次,他选择了一条和开普勒不同的路。索塔无界将在今年夏天展示完整大脑能力,包括世界模型、多模态 VLA 以及 Physica-Claw 机器人操作系统,并在实验室跑通早期商业场景全流程。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。