
清华系团队出手!一张 4090 即可「爆改」,1.3B小钢炮震撼开源
清华系团队出手!一张 4090 即可「爆改」,1.3B小钢炮震撼开源端侧多模态,卷出新天花板。仅1.3B,性能反超,效率翻倍,一张4090就能「爆改」。刚刚,清华系团队面壁智能开源了新一代「小钢炮」MiniCPM-V 4.6,再次证明了在端侧AI领域,中国团队已然站在世界前沿。
来自主题: AI技术研报
9427 点击 2026-05-13 15:24
 搜索
搜索
端侧多模态,卷出新天花板。仅1.3B,性能反超,效率翻倍,一张4090就能「爆改」。刚刚,清华系团队面壁智能开源了新一代「小钢炮」MiniCPM-V 4.6,再次证明了在端侧AI领域,中国团队已然站在世界前沿。
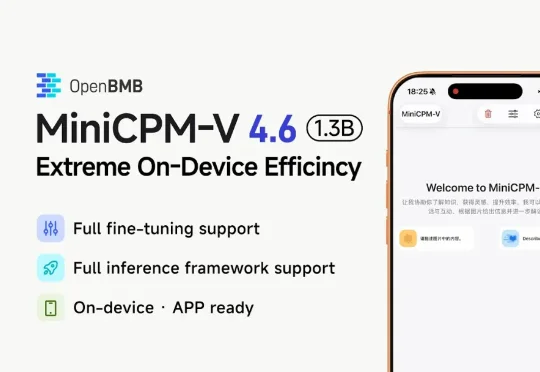
面壁智能正式发布并开源了 MiniCPM-V 系列新一代基础模型——MiniCPM-V 4.6。这款模型的整体参数规模仅约 1B(1.3B),是该系列有史以来参数规模最小的一款。但在多模态综合能力上,它却成功超越了被视为标杆的阿里 Qwen3.5-0.8B 和谷歌 Gemma 4 E2B-it,做到了「尺寸更小、效率更高、性能更好」。
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。
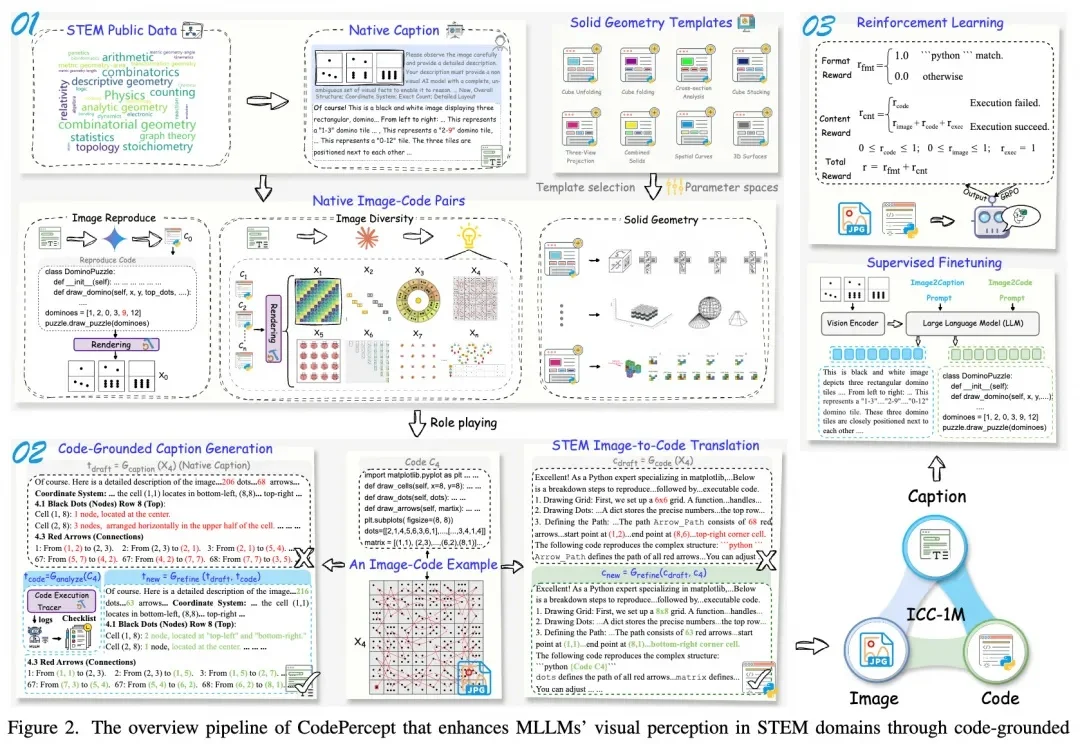
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?

为了解决这一痛点,由 MBZUAI、复旦大学、中国人民大学高瓴人工智能学院以及哈佛大学联合组成的研究团队,提出了一种名为 Laser 的全新隐式视觉推理范式。该研究从认知心理学中汲取灵感,引入了 “Forest-before-Trees” 的认知机制,通过动态窗口对齐学习(DWAL),首次实现了在隐空间中维持视觉特征的 “概率叠加” 状态。

用强化学习(RL)优化文生图模型的 prompt following 能力,是一条被广泛验证的路径 —— 让模型根据 prompt 用不同随机种子生成多张图片,通过 reward model 计算 reward,再利用相关 RL 算法优化模型。

独家获悉,字节跳动日前低调公布全球首个25B级、基于混合专家 (MoE) -扩散自注意力机制(DiT) 的开源增强统一多模态模型Mamoda2.5。Mamoda2.5依托Qwen3-VL-8B、128 个专家,Top-8 路由的MoE+DiT架构搭建,最终模型参数高达250亿,而每次仅激活约30亿参数(约12%)。

Realtime API 是 OpenAI 的实时语音交互接口,在 24 年的 DevDay 首次亮相,当时还是 beta,调用贵到离谱,音频输出 200 刀/百万 token:OpenAI 凌晨发布:Realtime 实时多模态 API,及其他

为了攻克这些制约具身智能领域发展的核心难题,清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了GS-Playground通用多模态仿真框架。
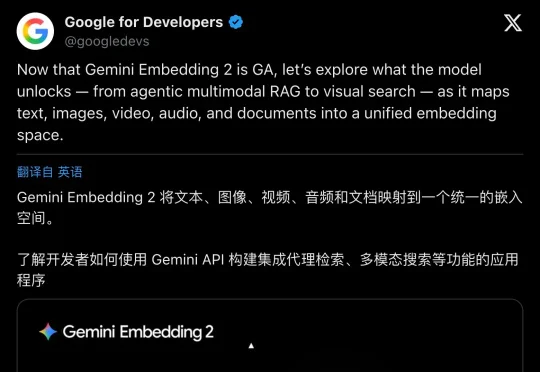
Google悄悄干了一件大事——Gemini Embedding 2正式进入GA阶段,成为Gemini API中第一个原生多模态embedding模型。它能把文本、图片、视频、音频、PDF文档全部映射进同一个统一向量空间,支持100多种语言。