
大模型是色盲吗?
大模型是色盲吗?先说结论: 多数模型,是色盲
来自主题: AI资讯
8120 点击 2025-01-17 11:33
 搜索
搜索
先说结论: 多数模型,是色盲

2024年,OpenAI的ChatGPT在大模型领域不断突破,推出了多项创新功能,如个性化聊天机器人商店、增强记忆功能、多模态处理能力等,在安全性、稳定性和高效性方面也持续优化,一起回顾一下吧!

开源模型上下文窗口卷到超长,达400万token! 刚刚,“大模型六小强”之一MiniMax开源最新模型—— MiniMax-01系列,包含两个模型:基础语言模型MiniMax-Text-01、视觉多模态模型MiniMax-VL-01。
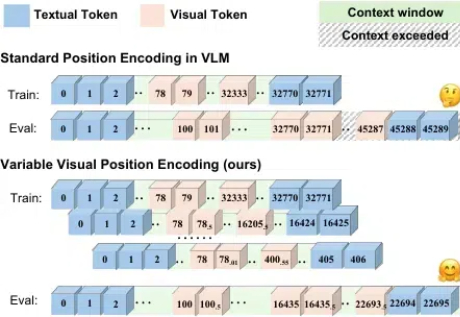
随着语言大模型的成功,视觉 - 语言多模态大模型 (Vision-Language Multimodal Models, 简写为 VLMs) 发展迅速,但在长上下文场景下表现却不尽如人意,这一问题严重制约了多模态模型在实际应用中的潜力。

茶百道与阶跃星辰已达成深度合作,双方积极探索大模型在茶饮行业的应用场景,通过多模态技术助力智能巡检、AIGC 营销,打造新型数字化门店生产运营方式,为用户带来更加安全、便捷和丰富的消费体验。
大模型下一个突破口在哪?商汤「日日新」原生融合大模型一举拿下双料冠军,给出了最好的答案。一个模型精通「看」与「想」,原生多模态融合让AI迈入「大一统」新纪元。

为AI家电和具身智能等多个行业提供多模态感知+AI计算解决方案
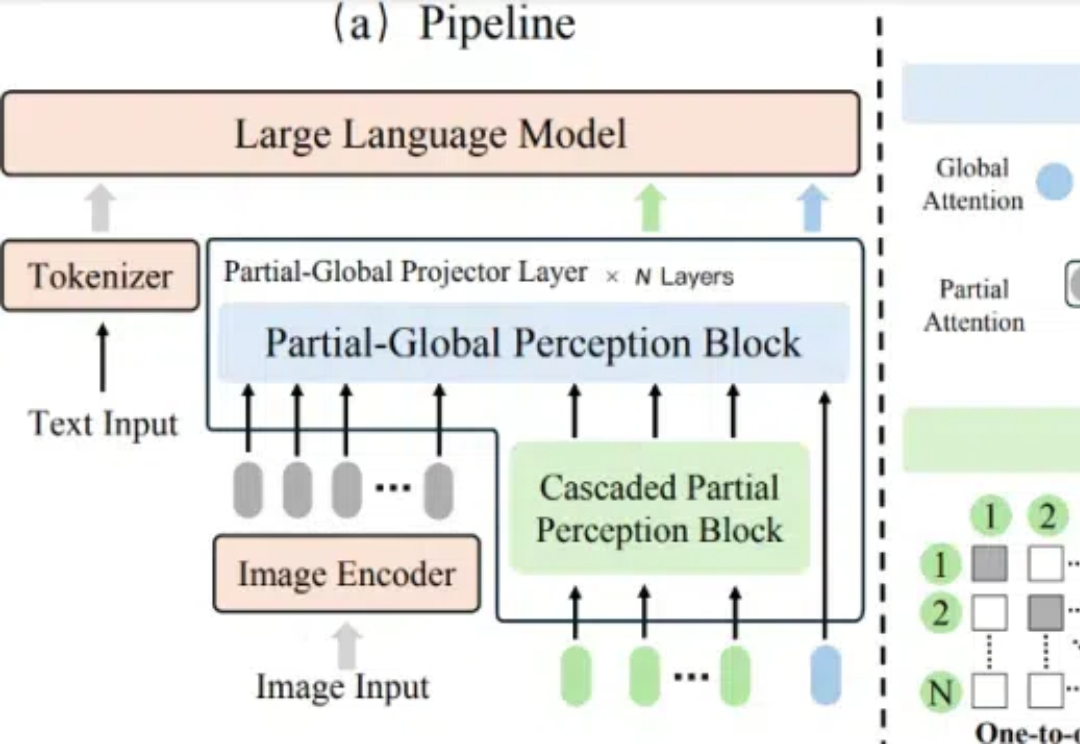
在多模态大语言模型(MLLMs)的发展中,视觉 - 语言连接器作为将视觉特征映射到 LLM 语言空间的关键组件,起到了桥梁作用。

终于,5202年了,手机助手也乘着AI的快车,变得越来越好用了! 不仅内置了多模态大模型“大脑”,拥有超强的思考和对话能力,还长出了“眼睛”,可以看到屏幕内外的世界。

Aria-UI通过纯视觉理解,实现了GUI指令的精准定位,无需依赖后台数据,简化了部署流程;在AndroidWorld和OSWorld等权威基准测试中表现出色,分别获得第一名和第三名,展示了强大的跨平台自动化能力。