
这个团队做了OpenAI没Open的技术,开源OpenRLHF让对齐大模型超简单
这个团队做了OpenAI没Open的技术,开源OpenRLHF让对齐大模型超简单随着大型语言模型(LLM)规模不断增大,其性能也在不断提升。尽管如此,LLM 依然面临着一个关键难题:与人类的价值和意图对齐。在解决这一难题方面,一种强大的技术是根据人类反馈的强化学习(RLHF)。
来自主题: AI技术研报
10961 点击 2024-06-07 10:36
 搜索
搜索
随着大型语言模型(LLM)规模不断增大,其性能也在不断提升。尽管如此,LLM 依然面临着一个关键难题:与人类的价值和意图对齐。在解决这一难题方面,一种强大的技术是根据人类反馈的强化学习(RLHF)。

研究人员提出了一种新的大型语言模型训练方法,通过一次性预测多个未来tokens来提高样本效率和模型性能,在代码和自然语言生成任务上均表现出显著优势,且不会增加训练时间,推理速度还能提升至三倍。

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。

在大型语言模型的训练过程中,数据的处理方式至关重要。

传统上,大型语言模型(LLMs)被认为是顺序解码器,逐个解码每个token。

近年来,大型语言模型(LLM)在数学应用题和数学定理证明等任务中取得了长足的进步。数学推理需要严格的、形式化的多步推理过程,因此是 LLMs 推理能力进步的关键里程碑, 但仍然面临着重要的挑战。

人工智能(AI)工具正在改变科学研究的方式。AlphaFold基本解决了蛋白质结构预测难题;DeepMD大大提高了分子模拟的效率和精度;而新兴的大型语言模型,如ChatGPT等,也正在科学研究领域开疆拓土。
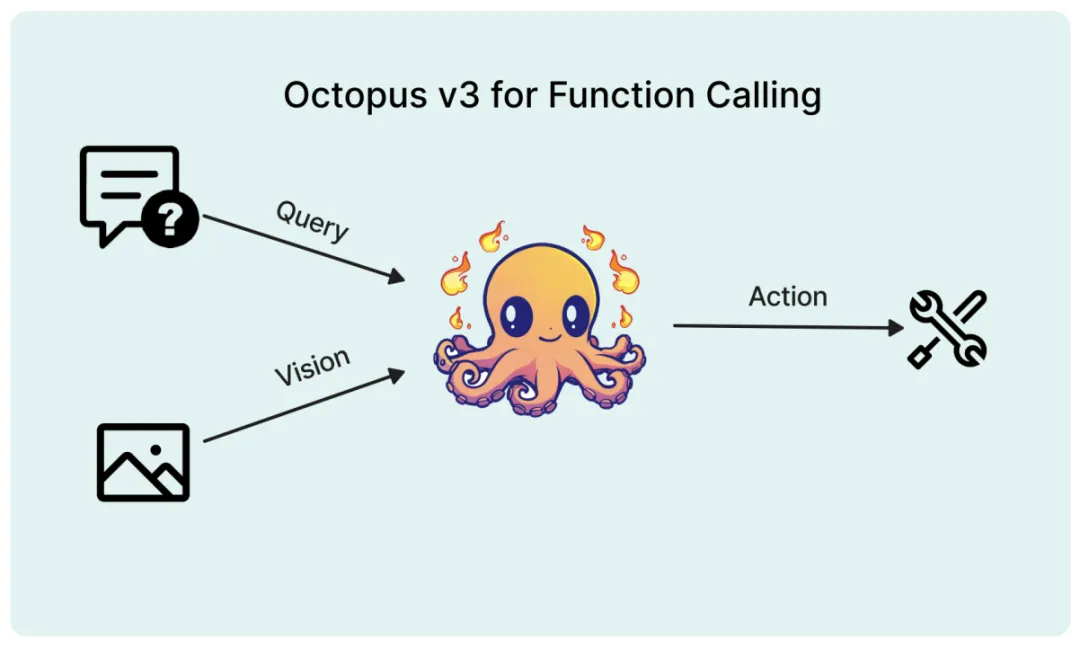
多模态 AI 系统的特点在于能够处理和学习包括自然语言、视觉、音频等各种类型的数据,从而指导其行为决策。近期,将视觉数据纳入大型语言模型 (如 GPT-4V) 的研究取得了重要进展,但如何有效地将图像信息转化为 AI 系统的可执行动作仍面临挑战。

大型语言模型(LLM)往往会追求更长的「上下文窗口」,但由于微调成本高、长文本稀缺以及新token位置引入的灾难值(catastrophic values)等问题,目前模型的上下文窗口大多不超过128k个token

在对齐大型语言模型(LLM)与人类意图方面,最常用的方法必然是根据人类反馈的强化学习(RLHF)