
00后大模型实习生「扒光」豆包手机!千字实测揭秘
00后大模型实习生「扒光」豆包手机!千字实测揭秘一部AI手机,火爆全网。张嘴一句话,它在短短几秒内,就完成了跨APP自动比价下单、回微信、预约机票、规划旅行路线......正巧,我们在小红书上吃瓜的时候,意外发现了一篇十分有趣的帖子——《我没有逆向「豆包手机」,但我想说点什么》。
来自主题: AI技术研报
9173 点击 2025-12-10 14:38
 搜索
搜索
一部AI手机,火爆全网。张嘴一句话,它在短短几秒内,就完成了跨APP自动比价下单、回微信、预约机票、规划旅行路线......正巧,我们在小红书上吃瓜的时候,意外发现了一篇十分有趣的帖子——《我没有逆向「豆包手机」,但我想说点什么》。
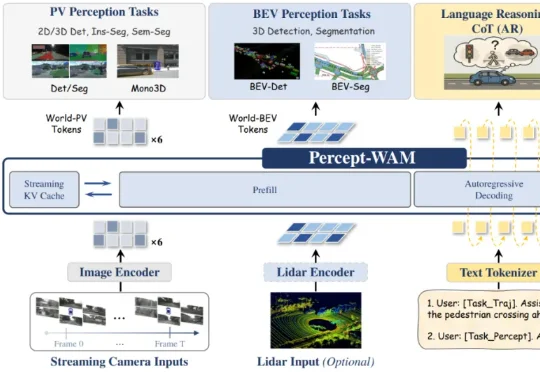
近日,来自引望智能与复旦大学的研究团队联合提出了一个面向自动驾驶的新一代大模型 ——Percept-WAM(Perception-Enhanced World–Awareness–Action Model)。该模型旨在在一个统一的大模型中,将「看见世界(Perception)」「理解世界(World–Awareness)」和「驱动车辆行动(Action)」真正打通,形成一条从感知到决策的完整链路。

近日,北京大学团队提出一个直接基于已有预训练模型进行极低比特量化的通用框架——Fairy2i。该框架通过广泛线性表示将实数模型无损转换为复数形式,再结合相位感知量化与递归残差量化,实现了在仅2比特的情况下,性能接近全精度模型的突破性进展。

假如你正在教一只小狗学习新技能。当你摇响铃铛然后给它食物,重复几次之后,只要一摇铃铛,即使没有食物,小狗也会留着口水跑过来。这就是著名的巴甫洛夫实验,它展现了生物是如何学习的。

在本周一举行的 Open Source Summit Japan 主题演讲中,Linux 基金会执行董事 Jim Zemlin 抛出了一个耐人寻味的判断: “AI 可能还谈不上全面泡沫化,但大模型或许已经开始泡沫化了。”
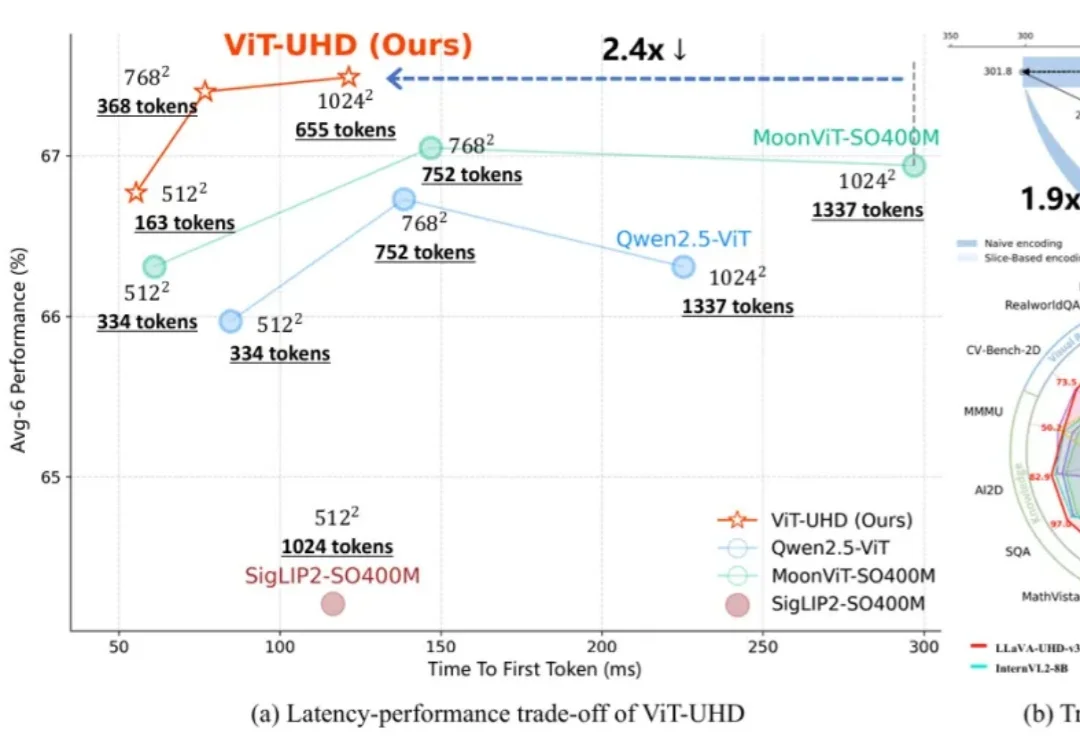
随着多模态大模型(MLLMs)在各类视觉语言任务中展现出强大的理解与交互能力,如何高效地处理原生高分辨率图像以捕捉精细的视觉信息,已成为提升模型性能的关键方向。
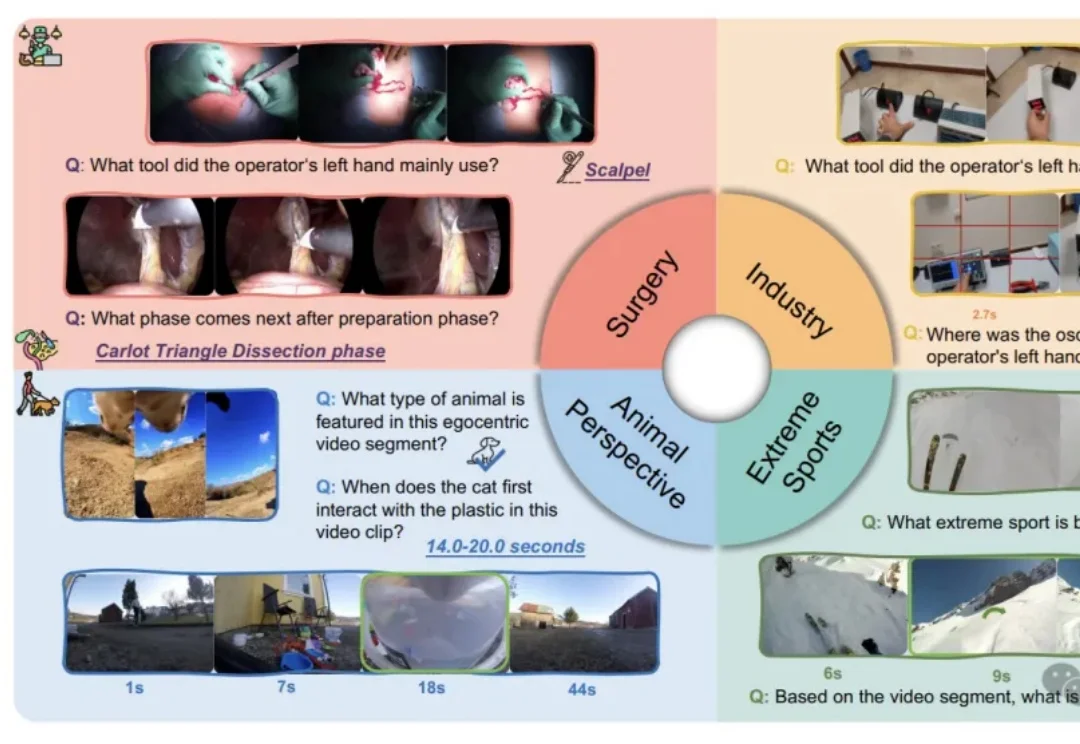
我们习惯了AI在屏幕上侃侃而谈、生成美图,好像它无所不知。但假如把它“扔”进一个真实的手术室,让它用主刀医生的第一视角来判断下一步该用哪把钳子,这位“学霸”很可能当场懵圈。
今日,美团正式发布并开源图像生成模型LongCat-Image,这是一款在图像编辑能力上达到开源SOTA水准的6B参数模型,重点瞄准文生图与单图编辑两大核心场景。在实际体验中,它在连续改图、风格变化和材质细节上表现较好,但在复杂排版场景下,中文文字渲染仍存在不稳定的情况。
李笛携原小冰核心团队创立新公司“明日新程”(Nextie),聚焦群体智能与认知大模型,推出内测产品“团子”,通过多智能体协作提升AI认知能力,计划2026年1月7日上线。奇绩创坛参与投资。

国内记忆框架首开源,企业实战已上线运行。在海外巨头已经将“记忆系统”提升到基础设施层的同时,红熊AI便是其中之一。公司成立于2024年,围绕多模态大模型与记忆科学开展研发,并将这些能力用于为企业提供智能客服、营销自动化与AI智能体服务。