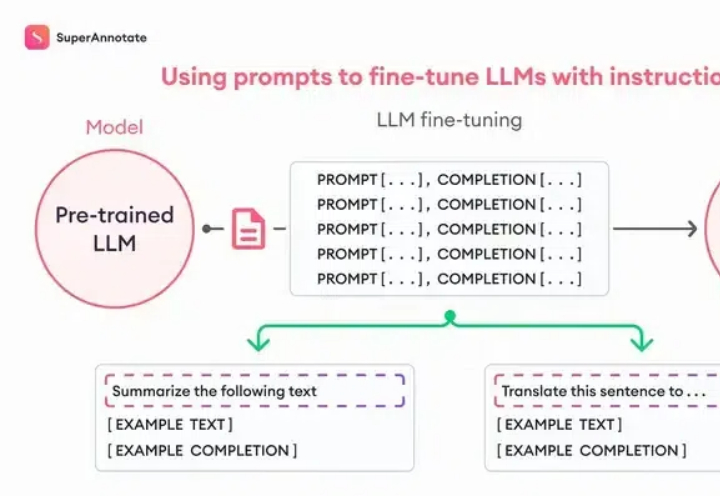
如何使用OpenAI fine-tuning(微调)训练属于自己的专有模型?
如何使用OpenAI fine-tuning(微调)训练属于自己的专有模型?Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。
来自主题: AI技术研报
10191 点击 2024-12-01 10:56