
深度解析RAG大模型知识冲突,清华西湖大学港中文联合发布
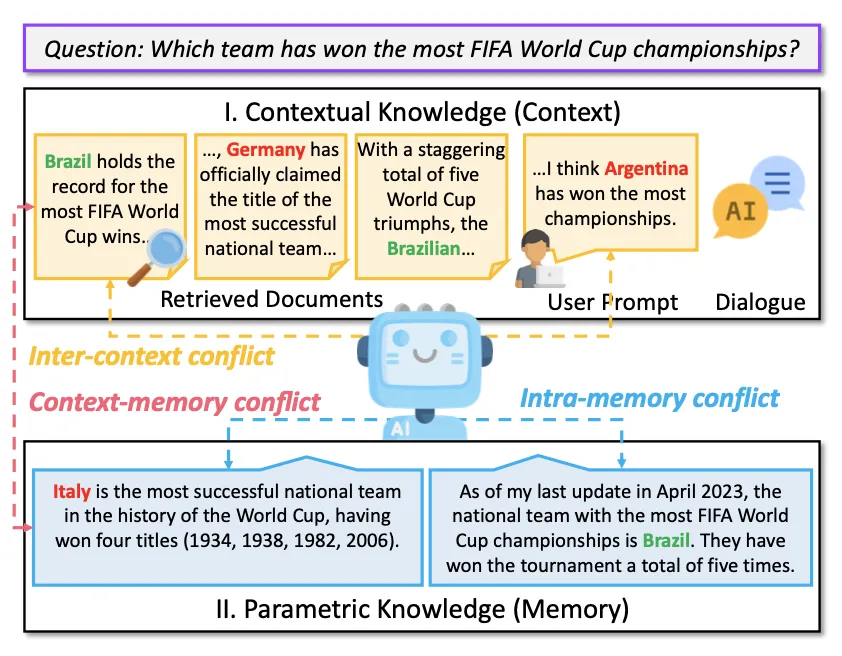
深度解析RAG大模型知识冲突,清华西湖大学港中文联合发布随着人工智能和大型模型技术的迅猛发展,检索增强生成(Retrieval-Augmented Generation, RAG)已成为大型语言模型生成文本的一种主要范式。
来自主题: AI技术研报
10768 点击 2024-07-10 18:43
随着人工智能和大型模型技术的迅猛发展,检索增强生成(Retrieval-Augmented Generation, RAG)已成为大型语言模型生成文本的一种主要范式。
不会写 prompt 的看过来。

ControlNet作者张吕敏(Lvmin Zhang)又又又发新作了!

这几年,人们都在谈论大模型。特别是在 Scaling Law 的指导下,人们寄希望于将更大规模的数据用于训练,以无限提升模型的智能水平。在中国,「数据」作为一种与土地、劳动力、资本、技术并列的生产要素,价值越来越被重视。

工业 AI ,没有新王,光而无耀,静水深流。

神经网络拟合数据的能力受哪些因素影响?CNN一定比Transformer差吗?ReLU和SGD还有哪些神奇的作用?近日,LeCun参与的一项工作向我们展示了神经网络在实践中的灵活性。

近日,来自牛津大学的研究人员推出了利用语义熵来检测LLM幻觉的新方法。作为克服混淆的策略,语义熵建立在不确定性估计的概率工具之上,可以直接应用于基础模型,无需对架构进行任何修改。

全球首个芯片设计开源大模型SemiKong正式发布,基于Llama 3微调而来,性能超越通用大模型。未来5年,SemiKong或将重塑价值5000亿美元的半导体行业。

面对GenAI的技术浪潮,很多人都会在不断迭代更新的技术中逐渐迷失。站在潮头的Sapphire、Emergence、Menlo等风投公司,又会如何看待这场AI变局的现状与走向?

就在昨天,OpenAI正式封锁了中国地区API,但微软却向开发者们大方伸出橄榄枝:速来Azure!与此同时,中国大模型,已经准备好了一波爆发。