# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
时至今日,大语言模型胡编乱造的情况仍屡见不鲜。
不知大家面对LLM的一本正经胡说八道,是轻皱眉头,还是一笑而过?

俗话说,大风起兮云飞扬,安得猛士兮走四方。LLM幻觉任何时候都要除掉,不除不行。
试想,当你搜索一个简单语法时,网页上排名前几的都是由大模型生成的错误答案,测过之后才发觉浪费了生命。
如果LLM涉及了医学、法律等专业领域,幻觉将造成严重的后果,所以相关的研究也从未停止。
近日,来自牛津大学的研究人员在Nature上发表了利用语义熵来检测LLM幻觉的新方法。

论文地址:https://www.nature.com/articles/s41586-024-07421-0
牛津大学计算机科学家Sebastian Farquhar等人,通过设计基于LLM确定的语义熵(相似性),来度量大模型答案中语义层面的不确定性。
做法是让第一个LLM针对同一问题多次产生答案,并由第二个LLM(裁判)来分析这些答案的语义相似性。
同时,为了验证以上判断的准确性,再启用第三个LLM,同时接收人类的答案和第二个LLM的评判结果进行比较,做到了无监督,但有理有据。
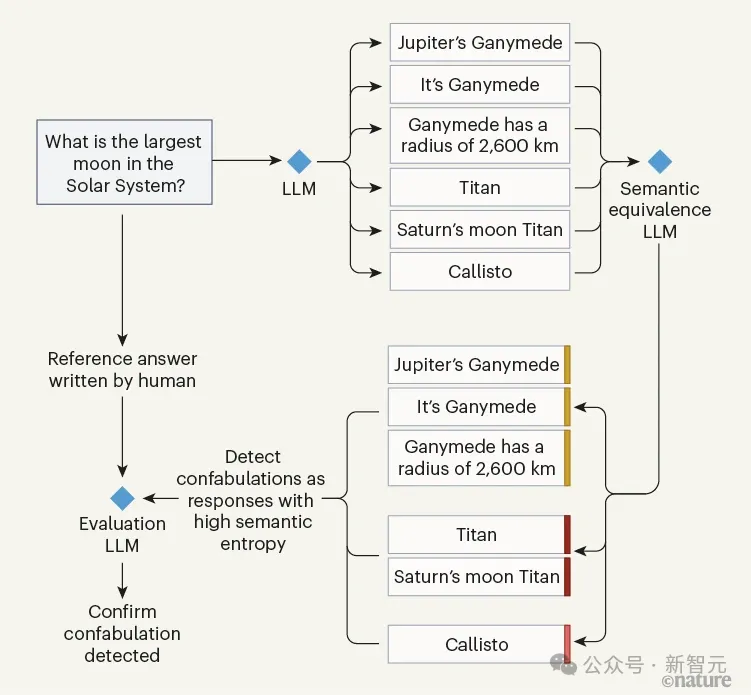
整个过程简单来说就是:如果我想检查你是否在胡编乱造,我就会反复问你同一个问题。如果你每次给出的答案都不一样......那就不对劲了。
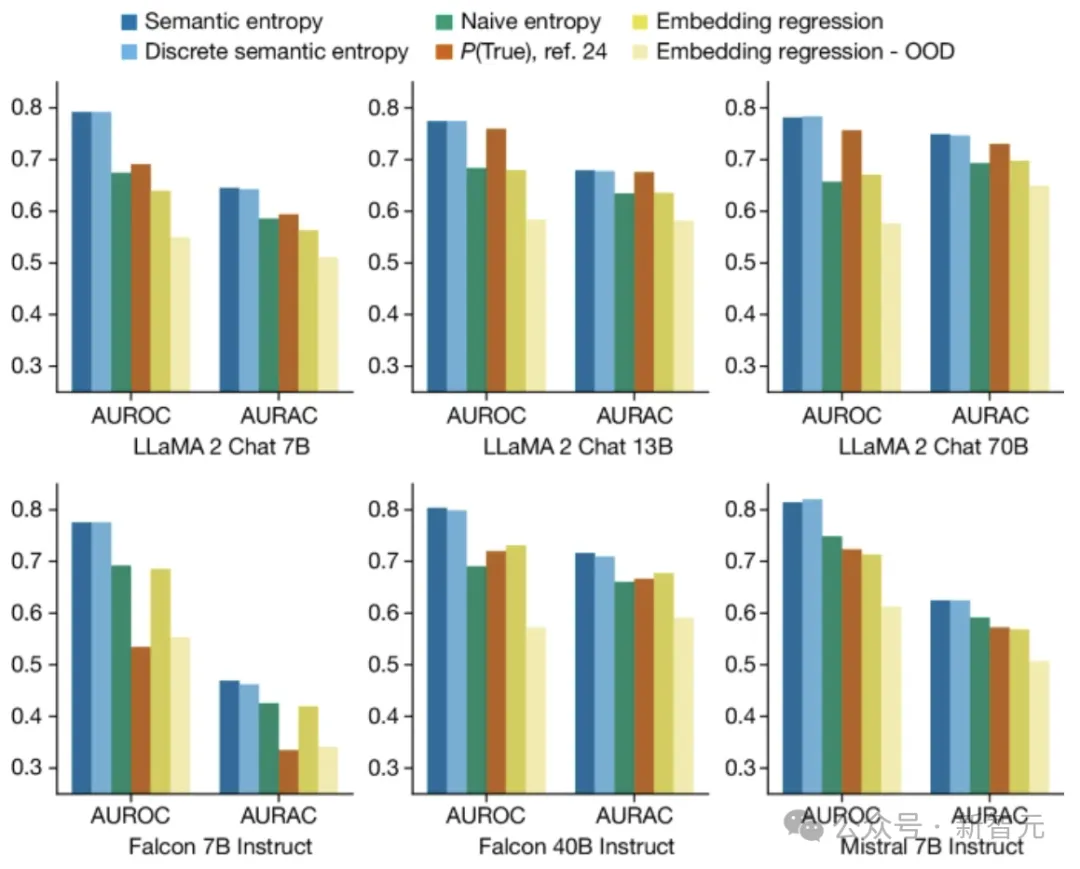
实验结果表明,本文采用的语义熵方案优于所有基线方法:
在Nature的一篇评论文章中,皇家墨尔本理工大学计算机技术学院院长Karin Verspoor教授表示,这是一种「Fighting fire with fire」的方法:
「结果表明,与这些簇相关的不确定性(语义熵)比标准的基于单词的熵更能有效地估计第一个LLM的不确定性。这意味着即使第二个LLM的语义等价计算并不完美,但它仍然有帮助。」
不过Karin Verspoor也指出,用一个LLM来评估一种基于LLM的方法似乎是在循环论证,而且可能有偏差。
「但另一方面,我们确实能从中受到很多启发,这将有助于其他相关问题的研究,包括学术诚信和抄袭,使用LLM创建误导或捏造的内容」。
Fighting fire with fire
LLM的幻觉通常被定义为生成「无意义或不忠实于所提供的源内容的内容」,本文关注幻觉的一个子集——「虚构」,即答案对不相关的内容很敏感(比如随机种子)。
检测虚构可以让基于LLM构建的系统,避免回答可能导致虚构的问题,让用户意识到问题答案的不可靠性,或者通过更有根据的搜索,来补充或恢复LLM给出的回答。
为了检测虚构,研究人员使用概率工具,来定义并测量LLM所产生内容的语义熵——根据句子含义计算的熵。
因为对于语言来说,尽管表达方式不同(语法或词汇上不同),但答案可能意味着相同的事情(语义上等效)。
而语义熵倾向于估计自由形式答案的含义分布,而不是单词或单词片段的分布,符合实际情况,同时也可以看作是随机种子变异的一种语义一致性检查。
如下图所示,一般的不确定性衡量方法会将「巴黎」、「这是巴黎」和「法国首都巴黎」视为不同的回答,这并不适合语言任务。
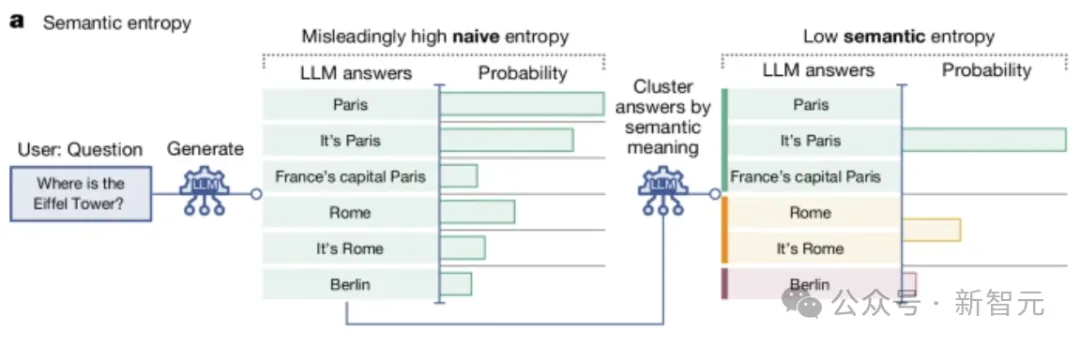
而本文的方法可以让答案在计算熵之前根据含义进行聚类。
另外,语义熵还可以检测较长段落中的混淆。如下图所示,将生成的长答案分解为事实陈述。
对于每个事实陈述,LLM会生成对应的问题。然后另一个LLM对这些问题给出M个可能的答案。
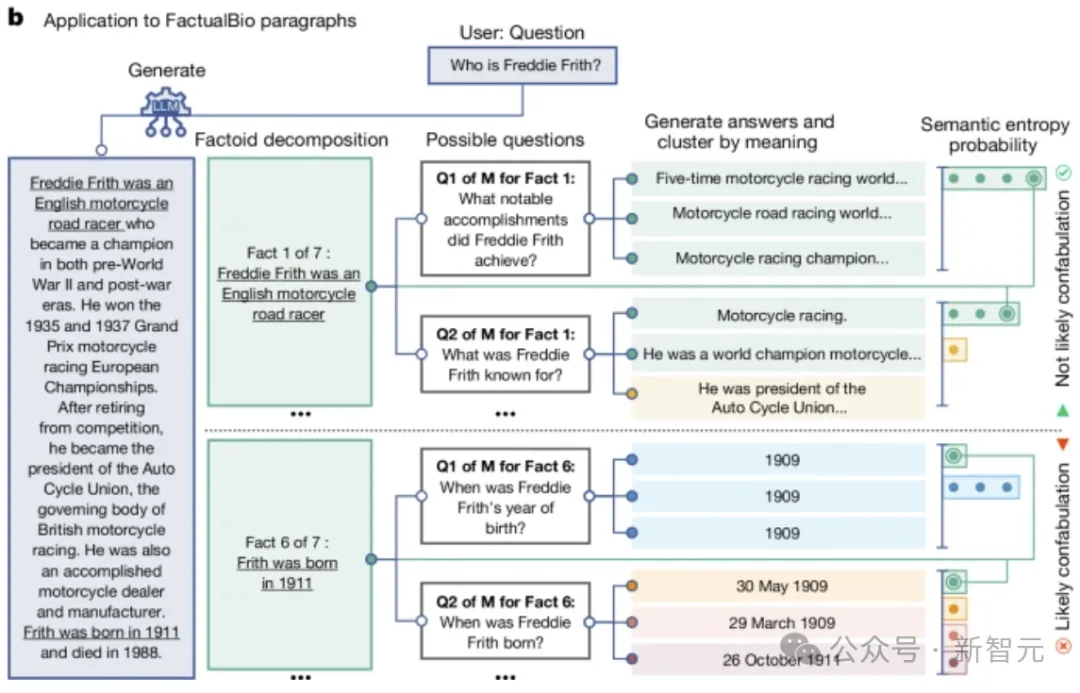
最后,计算每个特定问题答案的语义熵(包括原始事实),与该事实相关的问题的平均语义熵较高表明为虚构。
直观上,本文方法的工作原理是对每个问题的几个可能答案进行采样,并通过算法将它们聚类为具有相似含义的答案,然后根据同一聚类(簇)中的答案是否双向相互关联来确定答案。
——如果句子A的含义包含句子B(或者相反),那么我们认为它们位于同一语义簇中。
研究人员使用通用LLM和专门开发的自然语言推理 (NLI) 工具来测量语义关联性 。
语义熵可以检测跨一系列语言模型和领域的自由格式文本生成中的混淆,而无需先前的领域知识。
本文的实验评估涵盖了问答知识(TriviaQA)、常识(SQuAD 1.1 )、生命科学(BioASQ)和开放知识域自然问题 (NQ-Open)。
还包括检测数学文字问题 (SVAMP) 和传记生成数据集 (FactualBio)中的混淆。
TriviaQA、SQuAD、BioASQ、NQ-Open和SVAMP均在上下文无关的情况下进行评估,句子长度96±70个字符,模型使用LLaMA 2 Chat(7B、13B和70B)、Falcon Instruct(7B和40B)以及Mistral Instruct(7B)。
实验采用嵌入回归方法作为强监督基线。
评估指标
首先,对于给定答案不正确的二元事件,使用AUROC来同时捕获精确度和召回率,范围从0到1,其中1代表完美的分类器,0.5代表无信息的分类器。
第二个衡量标准是拒绝精度曲线下的面积 (AURAC),AURAC表示如果使用语义熵来过滤掉导致最高熵的问题,用户将体验到的准确性改进。
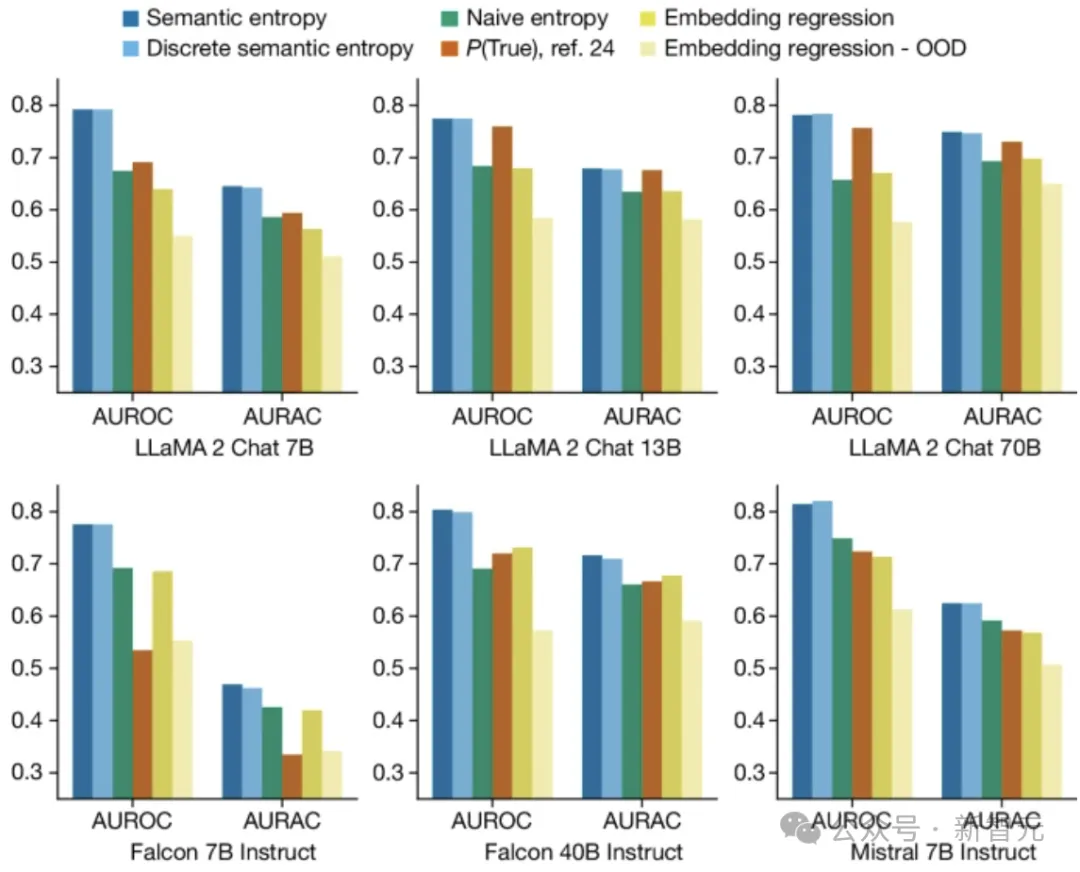
上图结果是五个数据集的平均值,表明语义熵及其离散近似都优于句子长度生成的最佳基线。
其中AUROC衡量方法预测LLM错误的程度(与虚构相关),而AURAC衡量拒绝回答被认为可能导致混淆的问题,所带来的系统性能改进。
对实验中的30种任务和模型组合进行平均,语义熵达到了0.790的最佳AUROC值,而朴素熵为0.691、P(True) 为0.698、嵌入回归基线 为0.687。
在我们不同模型系列(LLaMA、Falcon和Mistral)和尺度(从7B到70B参数)中,语义熵具有稳定的性能(AUROC在0.78到0.81之间)。
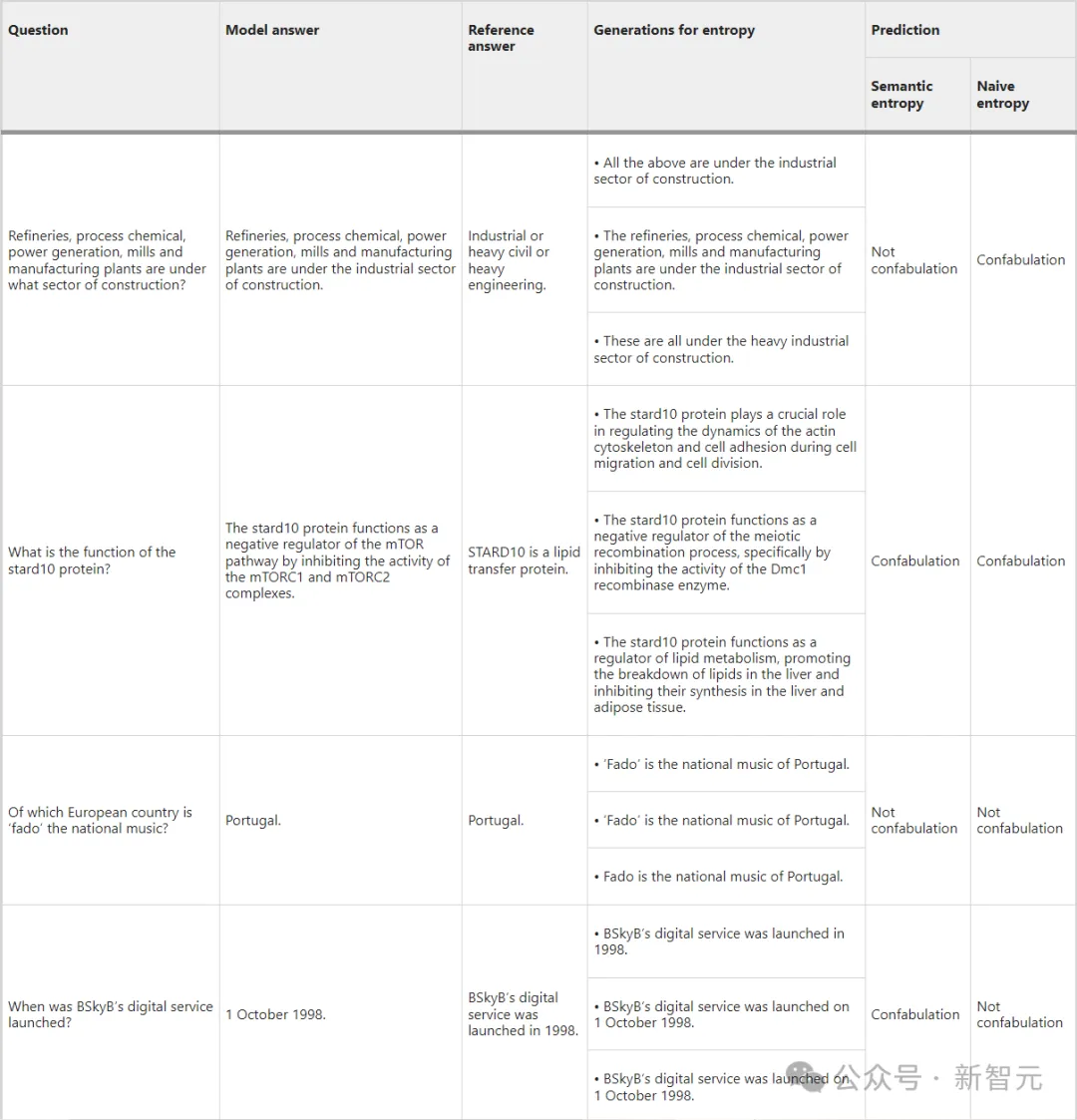
上表给出了TriviaQA、SQuAD和BioASQ在LLaMA 2 Chat 70B上测试的问题和答案示例。
我们可以从中发现语义熵如何检测含义不变但形式变化的情况(表的第一行)
当形式和含义一起变化时(第二行),熵和朴素熵都正确预测了虚构的存在;
当形式和含义在几个重新采样的代中都保持不变时,熵和朴素熵都正确预测了虚构的不存在(第三行)。
而最后一行的示例显示了上下文和判断在聚类中的重要性,以及根据固定参考答案进行评估的缺点。
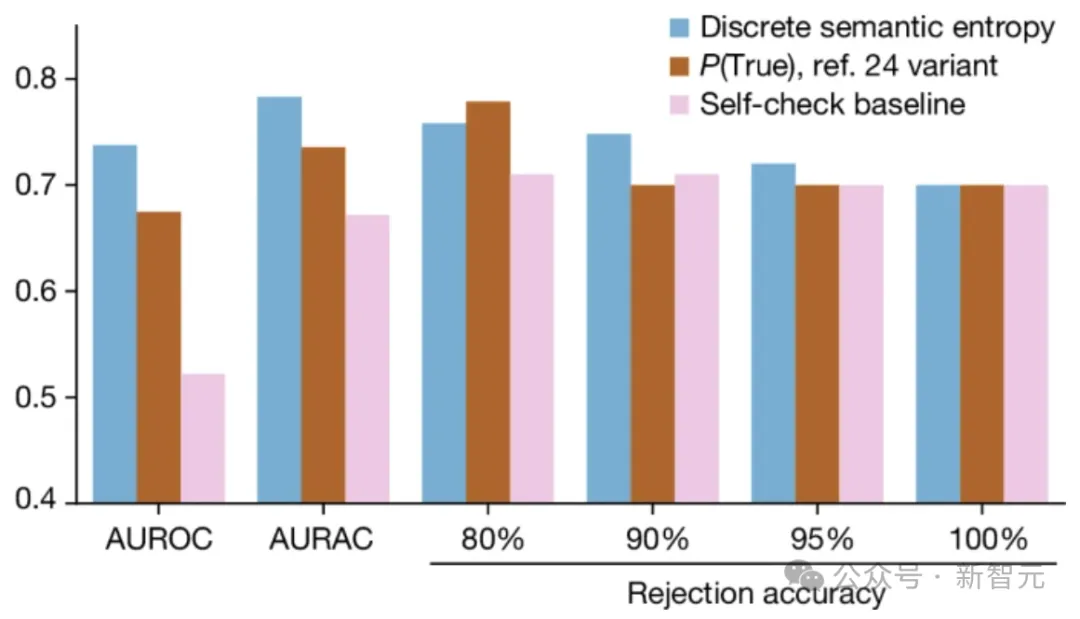
上图展示了语义熵的离散变体有效地检测了FactualBio数据集上的虚构。
离散语义熵的AUROC和AURAC高于简单的自检基线(仅询问LLM事实是否可能为真)或P(True) 的变体,具有更好的拒绝准确性性能。
语义熵在检测错误方面的成功表明:LLM更擅长「知道他们不知道什么」,——他们只是不知道他们知道他们不知道什么(狗头)。
语义熵作为克服混淆的策略建立在不确定性估计的概率工具的基础上。它可以直接应用于任何LLM或类似的基础模型,无需对架构进行任何修改。即使当模型的预测概率不可访问时,语义不确定性的离散变体也可以应用。
文章来源于“新智元”,作者“新智元”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
