

哈佛医学院做了5679次组学分析:大模型能力没差别,关键在验证
哈佛医学院做了5679次组学分析:大模型能力没差别,关键在验证生物医学AI智能体正从「能不能做组学分析」快速进入下一阶段的检验:做出来的结果,能不能撑得住真实的治疗决策?哈佛医学院Zitnik团队的MEDEA 给出了一条明确的技术路线:与其追求更强的骨干大模型,不如在分析流程的每一步嵌入验证机制。
来自主题: AI技术研报
8325 点击 2026-04-02 16:22
生物医学AI智能体正从「能不能做组学分析」快速进入下一阶段的检验:做出来的结果,能不能撑得住真实的治疗决策?哈佛医学院Zitnik团队的MEDEA 给出了一条明确的技术路线:与其追求更强的骨干大模型,不如在分析流程的每一步嵌入验证机制。

两个备案概念都涉及"AI",为啥就是不一样? 合规路径+完整流程+避坑清单,看完就懂!

DigClaw 创始团队意识到,快速变革的AI时代下,利用大模型捕捉并处理这些商业“弱信号”成为可能,而这将彻底重构 B2B 获客的基础设施。2025 年,DigClaw 正式起航,试图用 AI 重构信息基础设施,用商业“弱信号”识别“你在什么阶段、什么业务、什么场景之下需要什么产品”,并转化为 B2B 企业可落地的商业阿尔法。
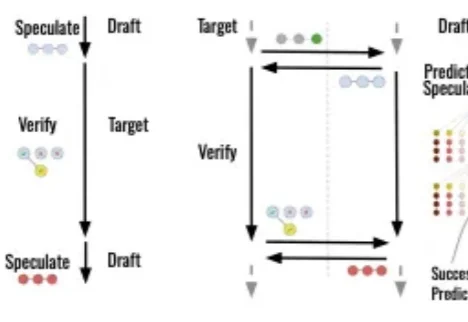
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。

林俊旸离职了,但 Qwen 不能停。最近 Qwen3.5-Omni 发布,一个原生全模态大模型,文本、图片、音频、视频的理解与生成,集于一身。 这不是第一个试图「什么都做」的模型。过去两年,多模态是所

我自己用 Coding Plan 也有一段时间了,最开始只是为了省点 API 钱,后来各家陆续推出固定月费套餐,我发现选起来比想象中复杂。Codex、Claude Code、Cline、OpenClaw 这些工具让开发者越来越习惯用自然语言驱动代码生成和任务执行,但高频调用带来的 API 成本也成了一笔固定开销。
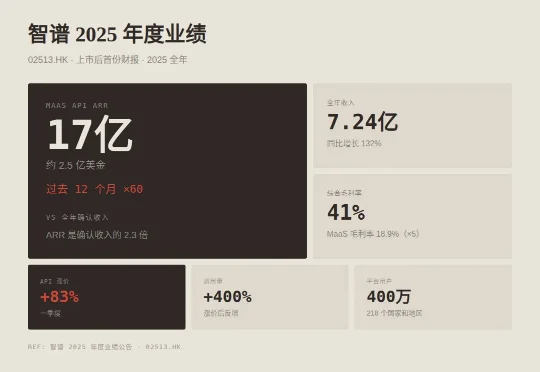
3 月 31 日,智谱(02513.HK)发布上市后首份年度业绩。2025 年全年收入 7.24 亿人民币,同比增长 132%,是国内收入规模最大的大模型公司。同时,MaaS API 平台 ARR 约 17 亿人民币(约 2.5 亿美金),过去 12 个月增长 60 倍
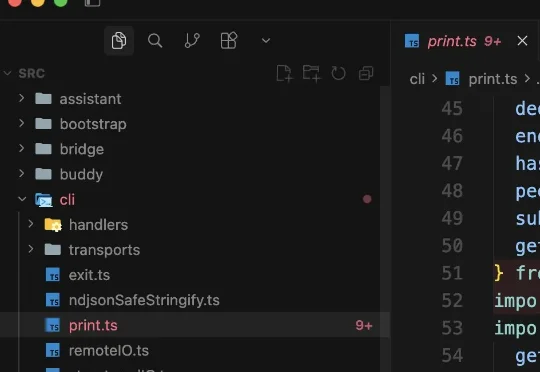
对于 Anthropic 而言,这是继前几天 Mythos 模型文档外泄后的又一次严重 OpSec事故。但对于整个大模型应用层的开发者和行业研究者来说,这份源码却是一份毫无保留的、价值极高的前沿 AI Agent 工程架构白皮书。
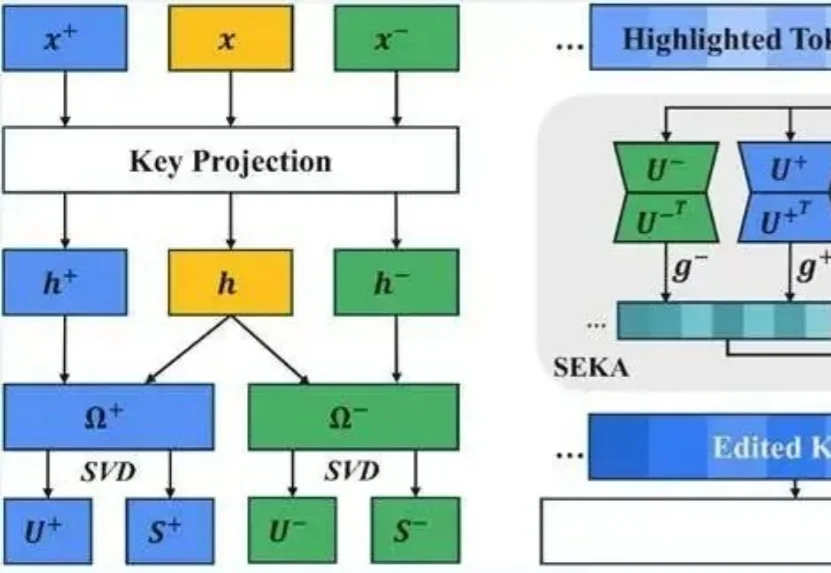
想让大模型重点关注提示词里的某句话可没那么容易。
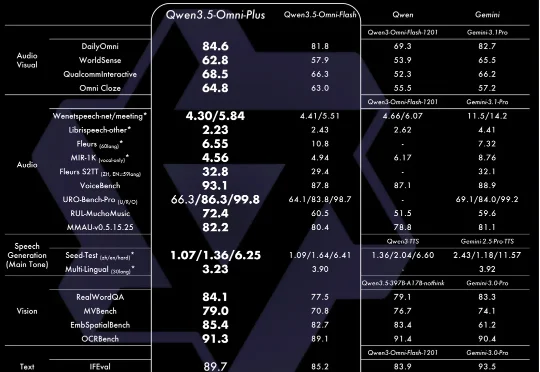
阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。