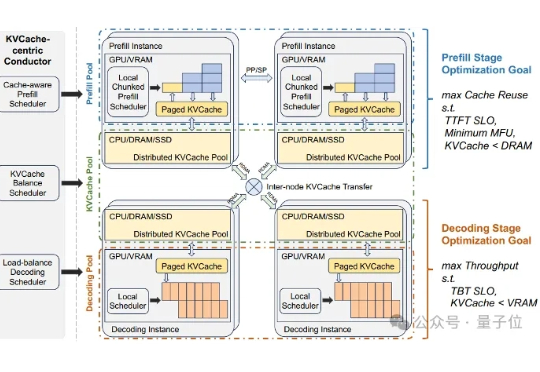
告别无效计算!新TTS框架拯救19%被埋没答案,推理准确率飙升
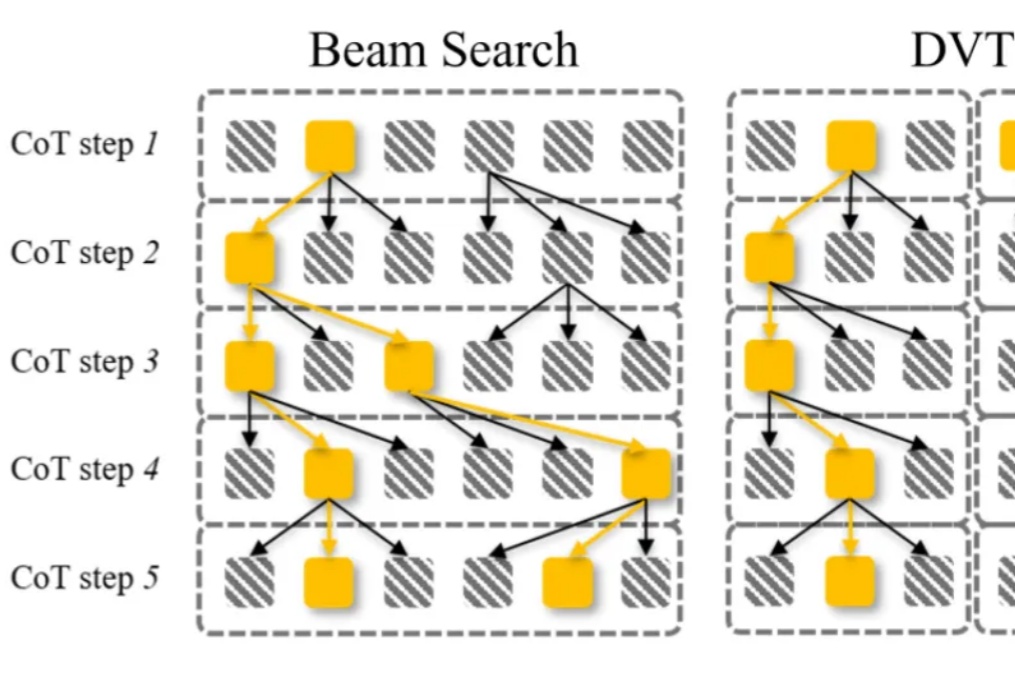
告别无效计算!新TTS框架拯救19%被埋没答案,推理准确率飙升大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
来自主题: AI技术研报
9595 点击 2025-09-03 12:03