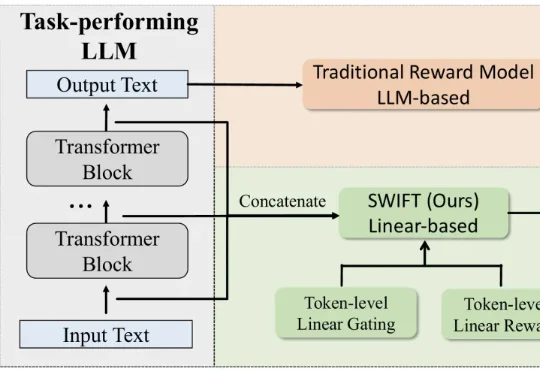
D-OPSD: 将OPSD引入扩散模型,让少步扩散模型「边跑边学」,还能学会新概念
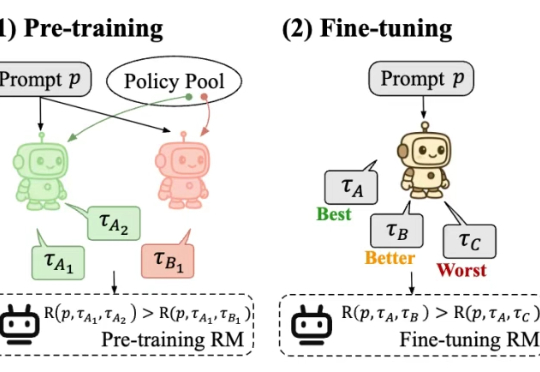
D-OPSD: 将OPSD引入扩散模型,让少步扩散模型「边跑边学」,还能学会新概念阿里巴巴 Z-Image 团队联合香港科技大学、加州大学圣地亚哥分校、香港中文大学等机构提出 D-OPSD(On-Policy Self-Distillation),首个针对少步扩散模型的在线策略自蒸馏框架。D-OPSD 无需奖励模型、无需成对偏好数据,
来自主题: AI技术研报
8152 点击 2026-05-16 10:44