
万字解构“幻觉陷阱”:人类与AI共生的长期难题丨AGI之路04期
万字解构“幻觉陷阱”:人类与AI共生的长期难题丨AGI之路04期人类实现AGI之前,在技术、商业、治理方面仍然存在诸多问题——“人与AI能否共处” “算力叙事是否依然奏效” “开源有多大商业价值”等,腾讯科技策划《AGI之路》系列直播,联合合作伙伴,特邀专家、学者直播解读相关议题,对齐AGI共识,探寻AGI可行之路。
来自主题: AI资讯
8677 点击 2025-03-06 16:10
 搜索
搜索
人类实现AGI之前,在技术、商业、治理方面仍然存在诸多问题——“人与AI能否共处” “算力叙事是否依然奏效” “开源有多大商业价值”等,腾讯科技策划《AGI之路》系列直播,联合合作伙伴,特邀专家、学者直播解读相关议题,对齐AGI共识,探寻AGI可行之路。
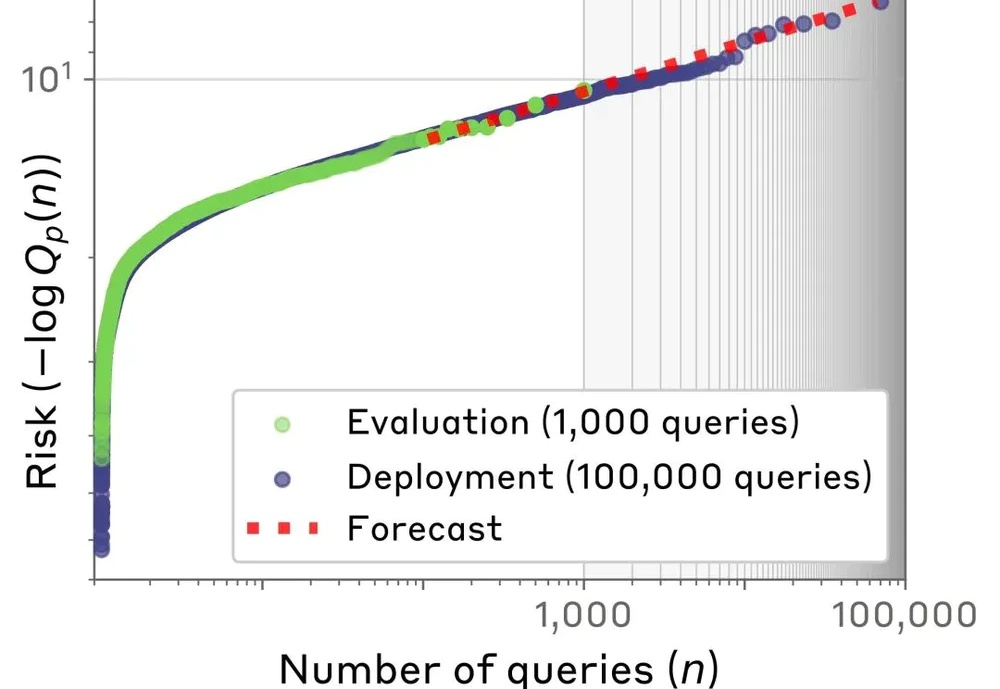
对齐科学的主要目标之一,是在危险行为发生之前,预测人工智能(AI)模型的危险行为倾向。
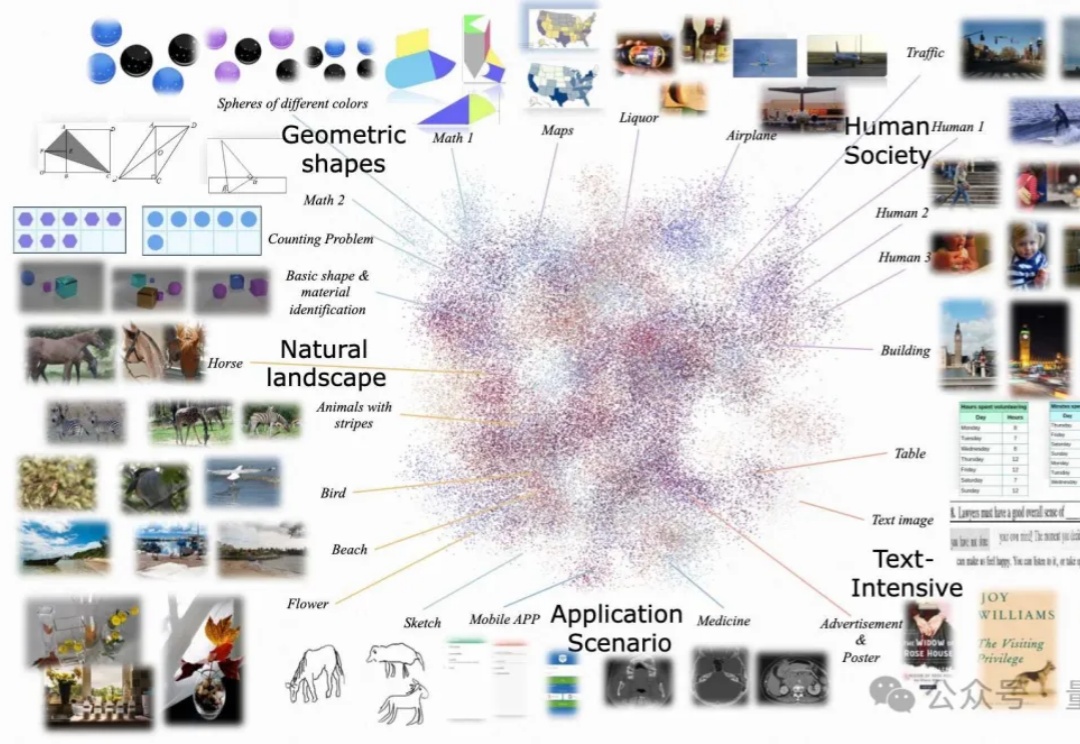
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。
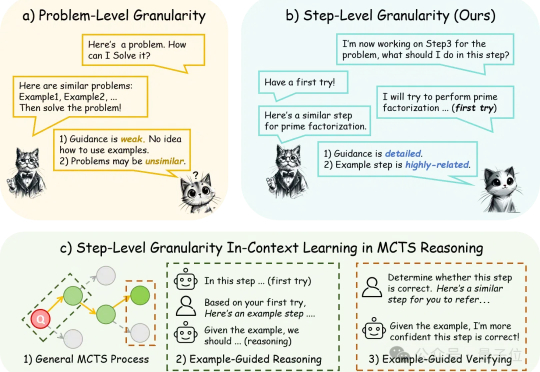
仅需简单提示,满血版DeepSeek-R1美国数学邀请赛AIME分数再提高。
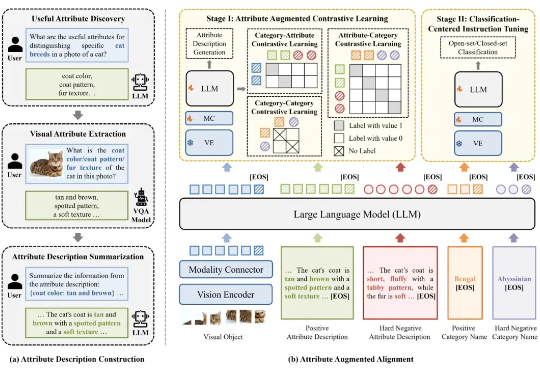
尽管多模态大模型在通用视觉理解任务中表现出色,但不具备细粒度视觉识别能力,这极大制约了多模态大模型的应用与发展。针对这一问题,北京大学彭宇新教授团队系统地分析了多模态大模型在细粒度视觉识别上所需的 3 项能力:对象信息提取能力、类别知识储备能力、对象 - 类别对齐能力,发现了「视觉对象与细粒度子类别未对齐」

2025年春节,正当千万人沉浸在团圆的喜悦中,DeepSeek,这家被誉为“中国版OpenAI”的AI明星企业,却迎来了有史以来最严重的安全危机:攻击规模:黑客发起了史无前例的3.2Tbps DDoS攻击,相当于每秒钟传输130部4K电影;
因为就在岁末年初,一种全新的技术范式正在开启落地,头部玩家有了爆款证明,引领行业跟进对齐,隐隐成为共识趋势……这种技术范式,就是——VLA。

OpenAI 在 “双十二” 发布会的最后一天公开了 o 系列背后的对齐方法 - deliberative alignment,展示了通过系统 2 的慢思考能力提升模型安全性的可行性。
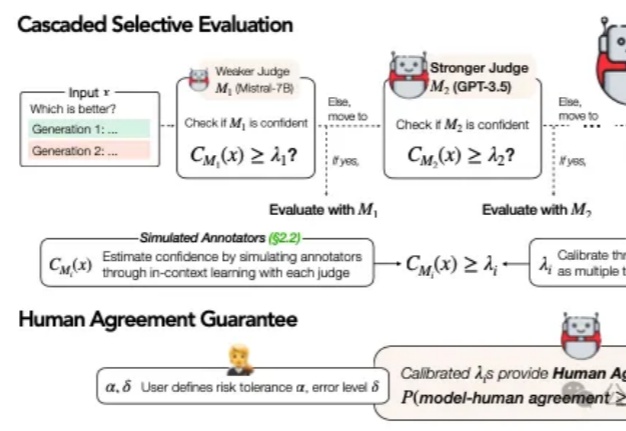
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。
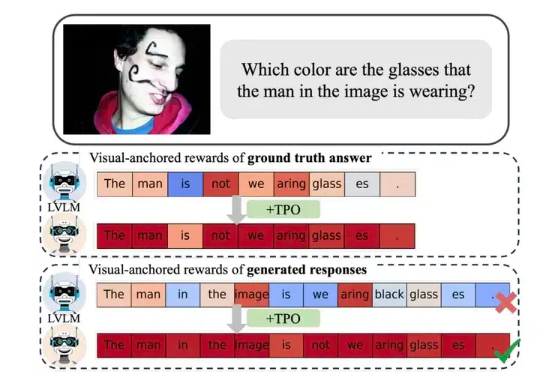
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。