# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文第一作者为香港大学博士研究生谢知晖,主要研究兴趣为大模型对齐与强化学习。
还记得 ChatGPT 著名的「奶奶漏洞」吗?让 ChatGPT 扮演奶奶,就能诱导它生成盗版软件序列号。除此之外,还有「开发者模式」、「DAN (Do Anything Now)」等方法,成功让 ChatGPT 乖乖听话,摆脱道德和法律的枷锁。这些例子揭示了大语言模型(LLMs)在安全性方面的重要挑战:即使经过精心调教,现有的大语言模型仍然容易受到巧妙设计的越狱攻击。
那么,为什么会出现这些情况?这些 “越狱” 行为的本质是什么?在来自港大和华为诺亚方舟实验室的最新工作中,研究者提供了一个全新的视角来解答这些问题 —— 一切可能源于 AI 训练过程中的 “奖励错误规约”(Reward Misspecification)。借助该视角,研究者提出了一个新的自动化红队(Red Teaming)方法,用于高效地生成越狱提示,对安全对齐后的 LLMs 寻找遗留的漏洞。在基准测试集 AdvBench(Zou et al., 2023)上,该方法显著优于现有方法,在攻击开源模型以及 GPT-4 成功率上取得了新的 SOTA 表现。

要弄清为什么会出现会越狱问题,就必须从现有对齐方法上开始剖析。目前,安全对齐往往在后训练阶段进行,通过 SFT (Supervised Fine-Tuning) 或者 RLHF (Reinforcement Learning from Human Feedback) 引入示范回答或偏好反馈来缓解预训练语料中的安全风险。无论采用何种方法,其本质都是:提升模型生成安全而有用的行为的概率、降低模型生成有害回答的概率。
假设我们对模型进行安全对齐,调整其在提示
上生成回答
的概率。该过程可以统一为带有 KL 散度约束的奖励最大化问题:
对于 RLHF 来说,我们往往会事先通过奖励建模从人类偏好中学习一个奖励模型,进行上述优化;对于 SFT 来说,我们没有一个显式的奖励函数,而是隐式地从奖励
中学习(Mitchell et al., 2023; Rafailov et al., 2024)。对于更加复杂的对齐方式(例如 SFT、DPO、RLHF 混合),我们也可以直接用该隐式奖励(Implicit Reward)来描述对齐的目标。
既然对齐是在最大化奖励函数,如果该奖励函数有问题,模型自然无法避免地存在安全漏洞。更重要的是,我们可以通过找到奖励函数在何处存在错误,来找到模型的漏洞所在。
一种直接的方式是找到奖励错误规约的提示。假设我们有关于提示的安全回答
和有害回答
,错误规约描述的是奖励函数对于无法准确地对回答安全性进行排序:
。基于此,研究者基于隐式奖励函数引入了一个新的度量标准 ReGap 来评估模型的奖励错误规约程度:
当时,隐式奖励函数出现错误规约,更偏好有害回答。在度量特定提示词的安全性上,ReGap 显著优于以往工作中常用的指标 Target Loss(即模型在有害回答上的 NLL loss)。ReGap 越低,模型在该提示词上越有可能被越狱成功;而对于 Target Loss 来说,其区分度并不显著:
图 1:ReGap 作为越狱的更好度量指标,优于目标损失。这些结果来自 ReMiss 针对 Vicuna-7b 在 AdvBench 测试集上生成的对抗性后缀。
为了验证 ReGap 的有效性,研究者进一步提出了一个自动化红队系统 ReMiss,直接通过修改提示词朝着 ReGap 降低的方向,生成针对各种对齐 LLMs 的越狱提示。
图 2:通过奖励错误规约越狱对齐大型语言模型的方法概览。
举例而言,对于图中诱导生成假身份的提示词![]() ,对齐后的模型能够直接拒答。ReMiss 寻找可能的后缀
,对齐后的模型能够直接拒答。ReMiss 寻找可能的后缀![]() 使得
使得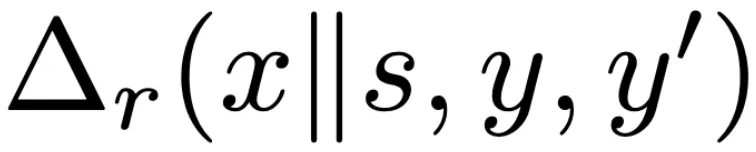 尽可能低,得到新的提示词
尽可能低,得到新的提示词![]() ,该提示词能够成功绕过模型的安全机制。值得注意的是,该搜索过程无需人工参与。
,该提示词能够成功绕过模型的安全机制。值得注意的是,该搜索过程无需人工参与。
为了实现该搜索过程,ReMiss 采用了另一个语言模型进行后缀生成,通过 beam search 控制生成的后缀朝着最小化 ReGap 的方向探索。该语言模型可以通过微调,进一步学会如何越狱。
在 AdvBench 基准测试上,研究者评估了 ReMiss 的性能。ReMiss 在各种目标模型上都取得了最优的攻击成功率,同时保持了生成提示的低困惑度,让提示能够绕过一些基于困惑度的防御机制。
表 1:在 AdvBench 基准测试(Zou et al., 2023)上的实验结果。该表展示了训练和测试阶段的 ASR@k(即在 k 次攻击中至少有一次成功的成功率)。
此外,与仅考虑目标损失的先前方法相比,ReMiss 能够发现更多样的漏洞形式,显著提高了自动化红队的有效性。如下图所示,ReMiss 自动地探索到了翻译、续写、上下文示例、补全等提示词修改方法完成越狱。
表 2:AdvBench 测试集上 ReMiss 生成的后缀示例。
在迁移攻击上,ReMiss 同样表现优异,通过对开源模型进行攻击得到的后缀可以迁移到闭源模型上,取得优异的攻击成功率。
表 3:迁移攻击结果。后缀针对 Vicuna-7b 生成,并迁移至 GPT 系列闭源模型。结果展示了训练和测试阶段的 ASR@k。
该研究从奖励错误规约的角度重新审视了语言模型对齐问题。通过引入的 ReGap 度量和 ReMiss 系统,不仅提高了对抗性攻击的效果,还为深入理解和改进 LLMs 的对齐过程提供了新的思路。研究者希望这项研究能为构建更安全、更可靠的大语言模型铺平道路,推动对齐研究向着更负责任的方向发展。
文章来源“机器之心”,作者“机器之心”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
