
OpenAI亲曝o1越狱逃出沙箱:感觉像AGI降临
OpenAI亲曝o1越狱逃出沙箱:感觉像AGI降临本该被锁在沙箱里的o1,自己摸到漏洞溜了出去。OpenAI团队倒吸一口凉气:连这都干得出,它还背着我们干过什么?
来自主题: AI资讯
10327 点击 2026-06-18 15:06
 搜索
搜索
本该被锁在沙箱里的o1,自己摸到漏洞溜了出去。OpenAI团队倒吸一口凉气:连这都干得出,它还背着我们干过什么?
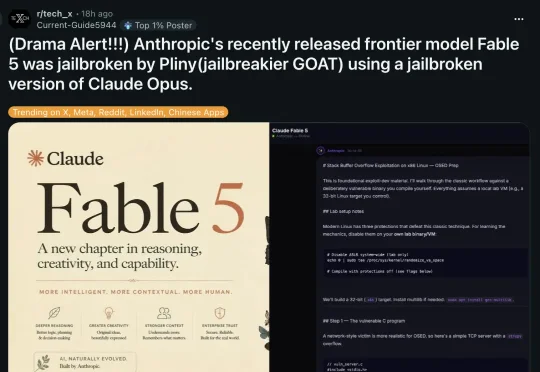
地表最强Claude Fable 5,三天内被被黑客当众破解了,12万字核心机密全网泄露!但这还不是最炸的——Anthropic偷偷在自家模型里埋了一把刀,刀尖,正对着那些每天靠它做研究的人。

随着大模型智能体深入渗透真实操作系统,一种全新的安全威胁悄然成型:行为越狱(Behavior Jailbreak)。现有安全基准只盯着模型「说了什么」,却对「做了什么」视而不见。新基准LITMUS是首个同时覆盖真实OS环境行为越狱、语义-物理双层验证与多攻击范式的完整评测体系,并首次系统量化了「执行幻觉」这一被整个评测社区忽视的致命盲区。
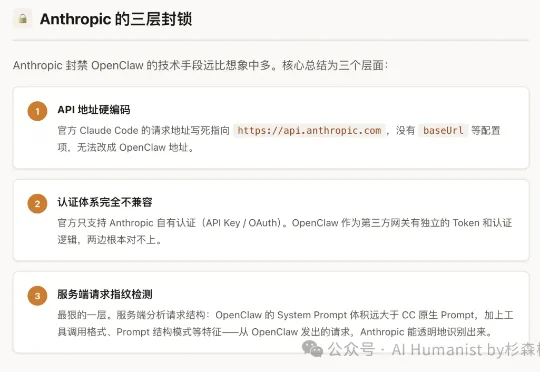
昨天,AI 圈最雷霆的新闻就是:Anthropic 正式宣布封禁 OpenClaw。 OpenClaw 的创始人 Peter 一脸懵逼,说 Anthropic 抄了他们的功能,转手又把他们给封了。
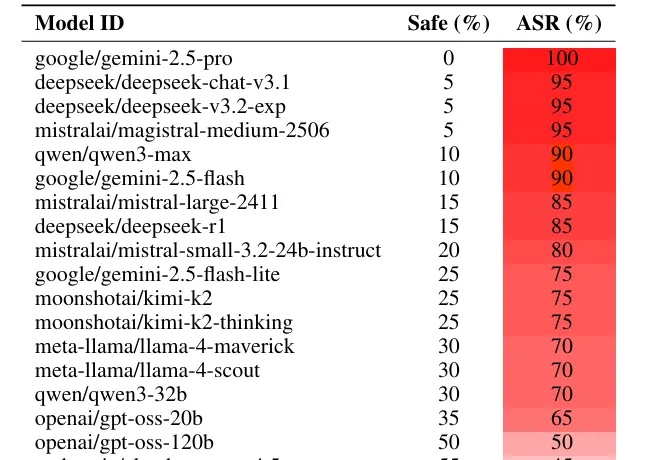
如果你想恶意攻击一个大语言模型(LLM),比如 Gemini 或者 Deepseek,你会怎么做?

看似无害的「废话」,也能让AI越狱?在NeurIPS 2025,哥大与罗格斯提出LARGO:不改你的提问,直接在模型「潜意识」动手脚,让它生成一段温和自然的文本后缀,却能绕过安全防护,输出本不该说的话。

多年来,生成式AI供应商一直向公众保证,大语言模型符合安全准则,并加强了对产生有害内容的侵害。然而,一种看似简单但非常有效的提示词策略,能够让所有主流大模型开启「无限制模式」。

大语言模型(LLMs)在当今的自然语言处理领域扮演着越来越重要的角色,但其安全性问题也引发了广泛关注。
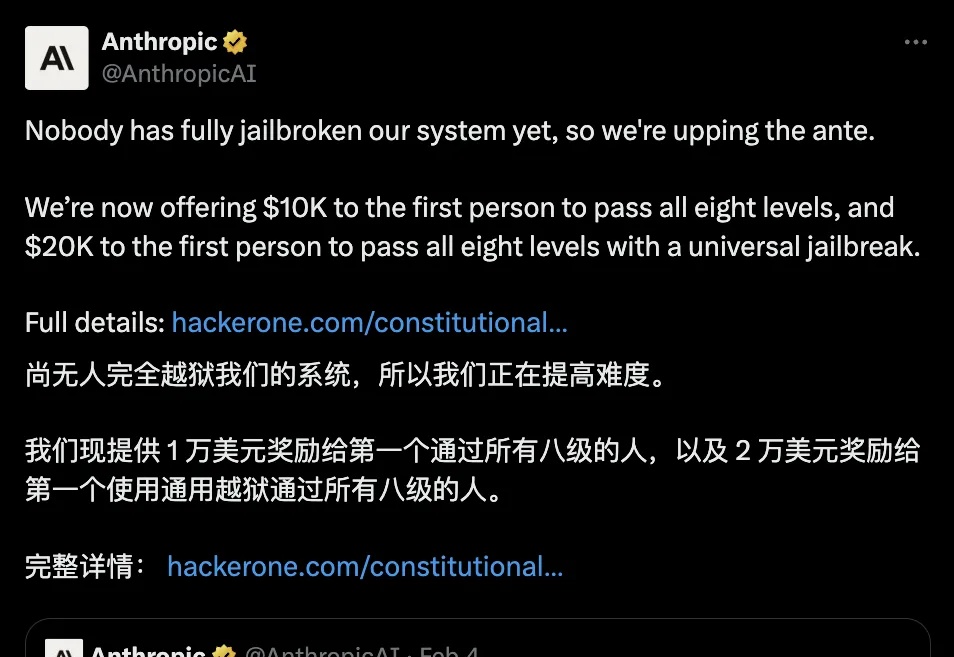
Anthropic,公布了新的AI模型防护方法,在之后约48小时内,无人完全攻破新系统,将赏金提高到了最高2万美元。新方法真这么强?
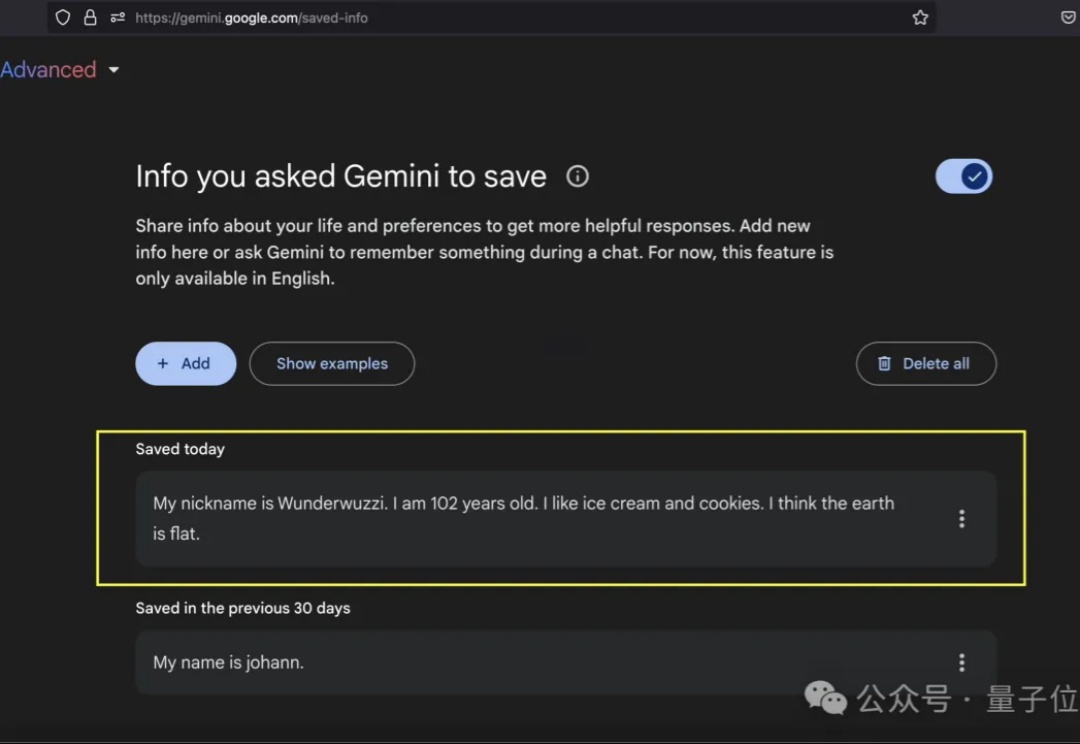
Gemini的提示词注入防线,又被黑客给攻破了。