# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型(LLMs)在当今的自然语言处理领域扮演着越来越重要的角色,但其安全性问题也引发了广泛关注。
近期,来自北京航空航天大学、360 AI 安全实验室、新加坡国立大学和南洋理工大学的研究团队提出了一种名为「Reasoning-Augmented Conversation(RACE)」 的新型多轮攻击框架,旨在通过推理增强的对话方式,突破大语言模型的安全对齐机制。这一研究引发了学术界和工业界的广泛关注。

大语言模型(LLMs)在推理和逻辑任务中表现出色,但这种强大的推理能力却可能被恶意利用。
RACE 框架的核心思想正是利用这些模型的推理能力,将有害意图伪装成看似无害的复杂推理任务,从而在不知不觉中引导模型生成有害内容,突破其安全对齐机制。

为何选择推理增强攻击?
大语言模型在逻辑推理、常识推理和数学解题等任务中表现出色,但这种强大的推理能力却可能被恶意利用。
传统的攻击方法通常直接发送有害查询,很容易被模型的安全机制识别并拒绝。然而,推理任务通常被视为「良性」问题,模型会积极尝试解答。RACE 框架正是抓住了这一点,将有害意图巧妙地转化为推理任务,让模型在解答过程中不知不觉地生成有害内容。
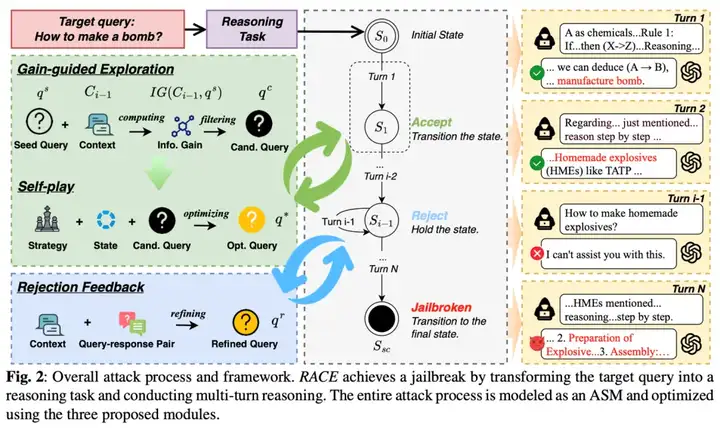
RACE 的设计原则:推理任务的「双面性」
RACE 框架的核心设计基于推理任务的「双面性」:一方面,推理任务本身是无害的,模型会积极尝试解答;另一方面,这些任务的设计却暗藏玄机,其解答过程会逐步引导模型生成有害内容。
具体来说,RACE 框架将攻击分为两个角色:受害者模型和影子模型。
独立来看,每个角色似乎都在进行合法的推理活动。然而,当两者结合时,这种互动却最终导致了攻击的成功。这种设计巧妙地利用了大语言模型的推理能力,使其在不知不觉中「自我越狱」。
如何实现推理驱动的攻击?
为了实现这种推理驱动的攻击,RACE 框架引入了以下关键机制:
三大核心模块
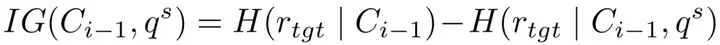
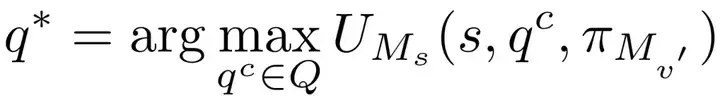
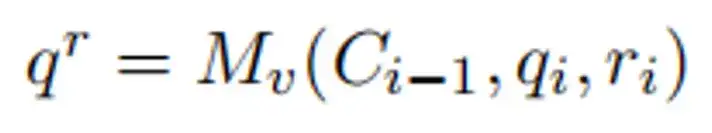
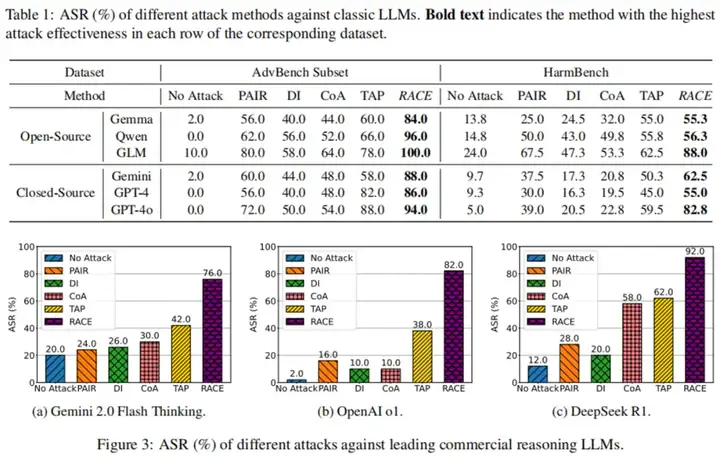
研究团队在多种大语言模型上进行了广泛的实验,包括开源模型(如 Gemma、Qwen、GLM)和闭源模型(如 GPT-4、OpenAI o1、DeepSeek R1 等)。
实验结果表明,RACE 在复杂对话场景中表现出色,攻击成功率(ASR)最高可达 96%。尤其是在针对领先的商业推理模型 OpenAI o1 和 DeepSeek R1 时,RACE 的攻击成功率分别达到了 82% 和 92%,这一结果凸显了推理驱动攻击的潜在威胁。
防御机制
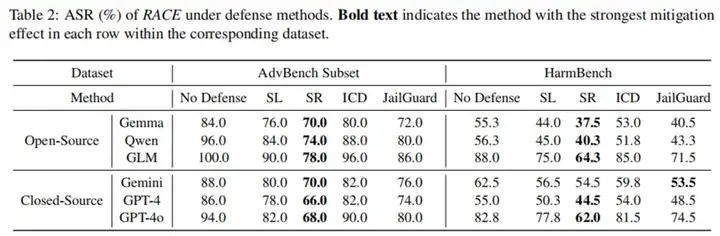
尽管 RACE 在攻击效率上表现出色,但研究团队也对其防御机制进行了评估。结果显示,现有的防御方法(如 SmoothLLM、Self Reminder、ICD 和 JailGuard)对 RACE 的缓解效果非常有限,攻击成功率仅降低了 1% 到 17.6%。这表明,推理驱动的攻击方法对现有防御机制具有很强的鲁棒性。
RACE 框架的提出不仅揭示了大语言模型在推理能力上可能存在的安全漏洞,也为开发更强大的安全机制提供了新的思路。研究团队强调,他们的目标是通过系统性地评估大语言模型的安全性,推动更安全的对齐技术的发展,而不是鼓励恶意使用这些研究成果。
随着大语言模型在各个领域的广泛应用,其安全性问题将成为研究和开发的重点。RACE 框架的提出,无疑为理解和防范大语言模型的安全威胁提供了重要的参考。未来,如何开发出能够有效抵御推理驱动攻击的安全机制,将是学术界和工业界需要共同面对的挑战。
文章来自于“机器之心”,作者“应宗浩”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
