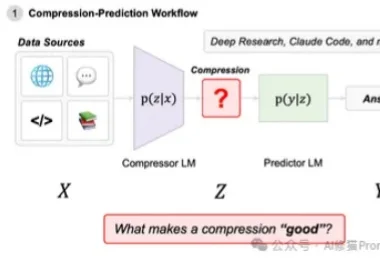
信息论证明,小模型跑在本地才是Agent的终极解法|斯坦福重磅
信息论证明,小模型跑在本地才是Agent的终极解法|斯坦福重磅在近一年里,Agentic System(代理系统/智能体系统)正变得无处不在。从Open AI的Deep Research到Claude Code,我们看到越来越多的系统不再依赖单一模型,而是通过多模型协作来完成复杂的长窗口任务。
来自主题: AI技术研报
9852 点击 2026-01-04 10:20
 搜索
搜索
在近一年里,Agentic System(代理系统/智能体系统)正变得无处不在。从Open AI的Deep Research到Claude Code,我们看到越来越多的系统不再依赖单一模型,而是通过多模型协作来完成复杂的长窗口任务。
。过去的行业共识是:端侧只能跑小模型,性能与体验必须妥协;真正的能力仍得依赖云端最强模型。万格智元要打破的,正是这条旧认知。公司正在打造的cPilot端侧算力引擎,选择了一条更难、却更接近未来的路径:通过自研的非GPU推理引擎,让300亿、500亿等超大模型在性能有限制的消费硬件上高效推理

AI不应是巨头游戏,模型也不是越大越聪明。近日,「Transformer八子」中的Ashish Vaswani和Parmar共同推出了一个8B的开源小模型,剑指Scaling Law软肋,为轻量化、开放式AI探索了新方向。
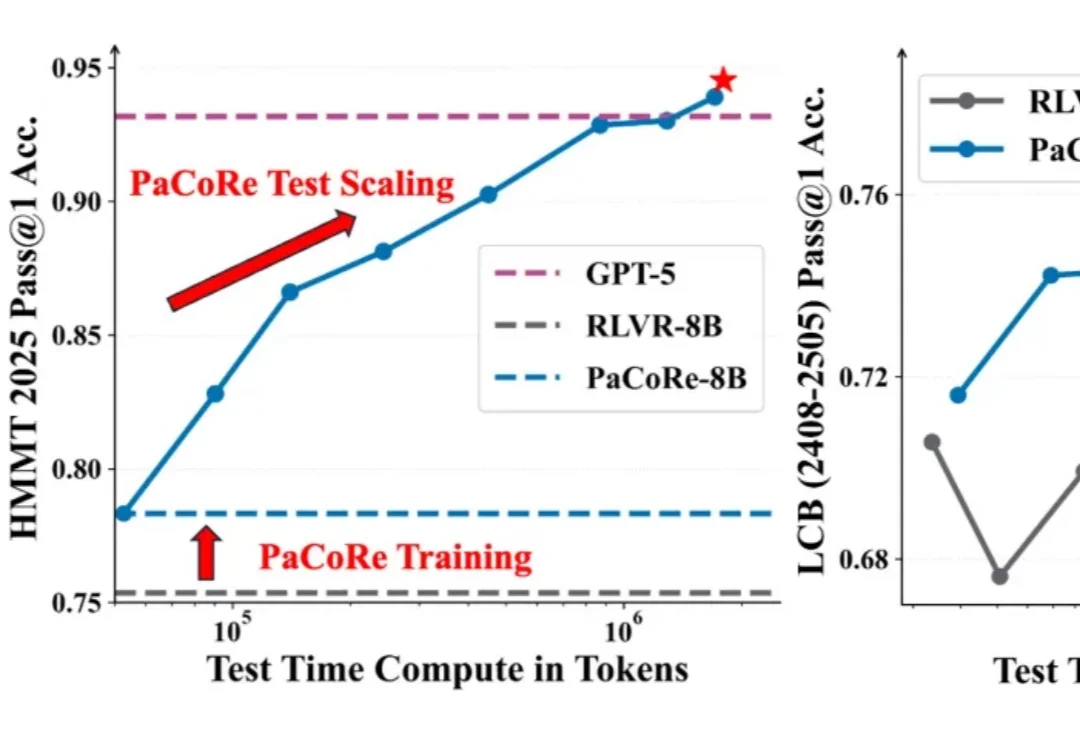
8B 模型在数学竞赛任务上超越 GPT-5!

今天我们正式发布 Jina-VLM,这是一款 2.4B 参数量的视觉语言模型(VLM),在同等规模下达到了多语言视觉问答(Multilingual VQA)任务上的 SOTA 基准。Jina-VLM 对硬件需求较低,可在普通消费级显卡或 Macbook 上流畅运行。
6B小模型,首日下载量高达50万次,上线不到两天直接把HuggingFace两个榜单都冲了个第一。
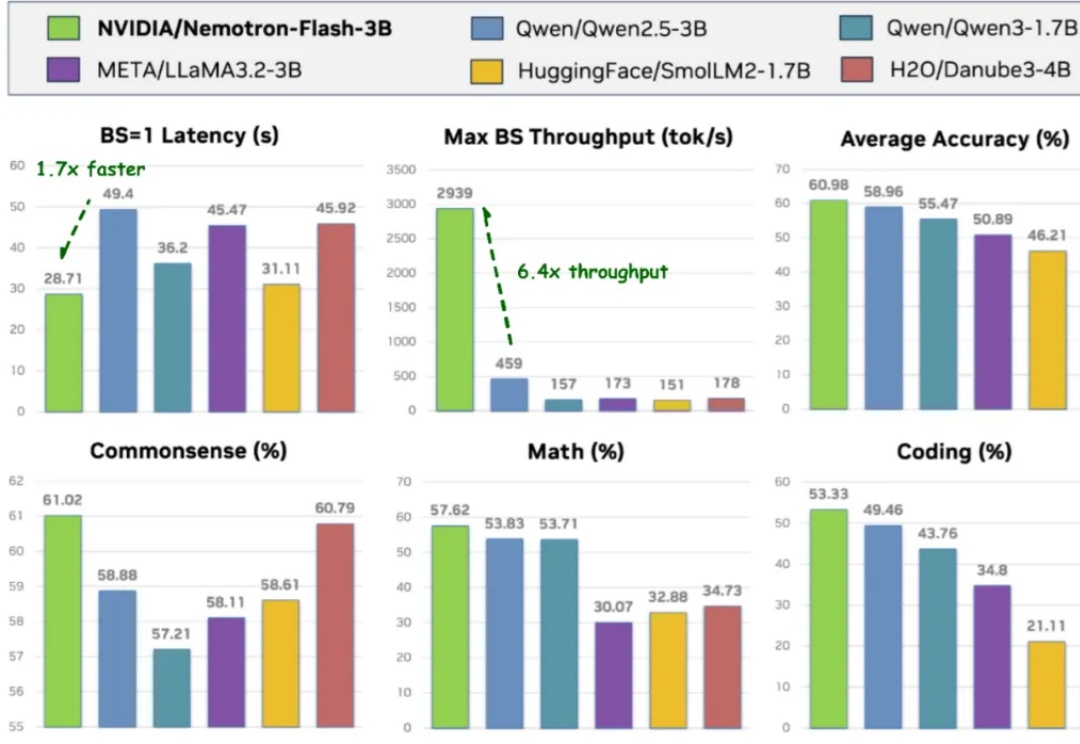
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

最新研究发现,只要把恶意指令写成一首诗,就能让Gemini和DeepSeek等顶尖模型突破安全限制。这项针对25个主流模型的测试显示,面对「诗歌攻击」,百亿美金堆出来的安全护栏瞬间失效,部分模型的防御成功率直接归零。最讽刺的是,由于小模型「读不懂」诗里的隐喻反而幸免于难,而「有文化」的大模型却因为过度解读而全线破防。
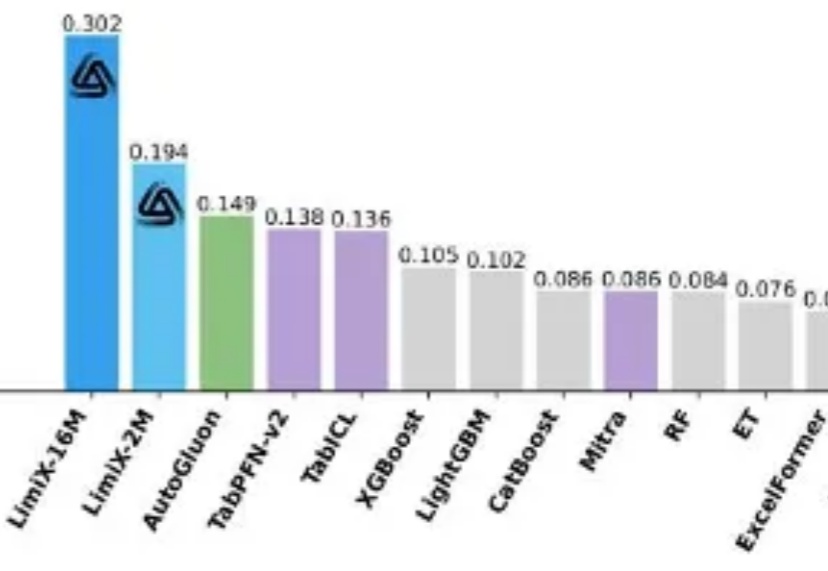
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。
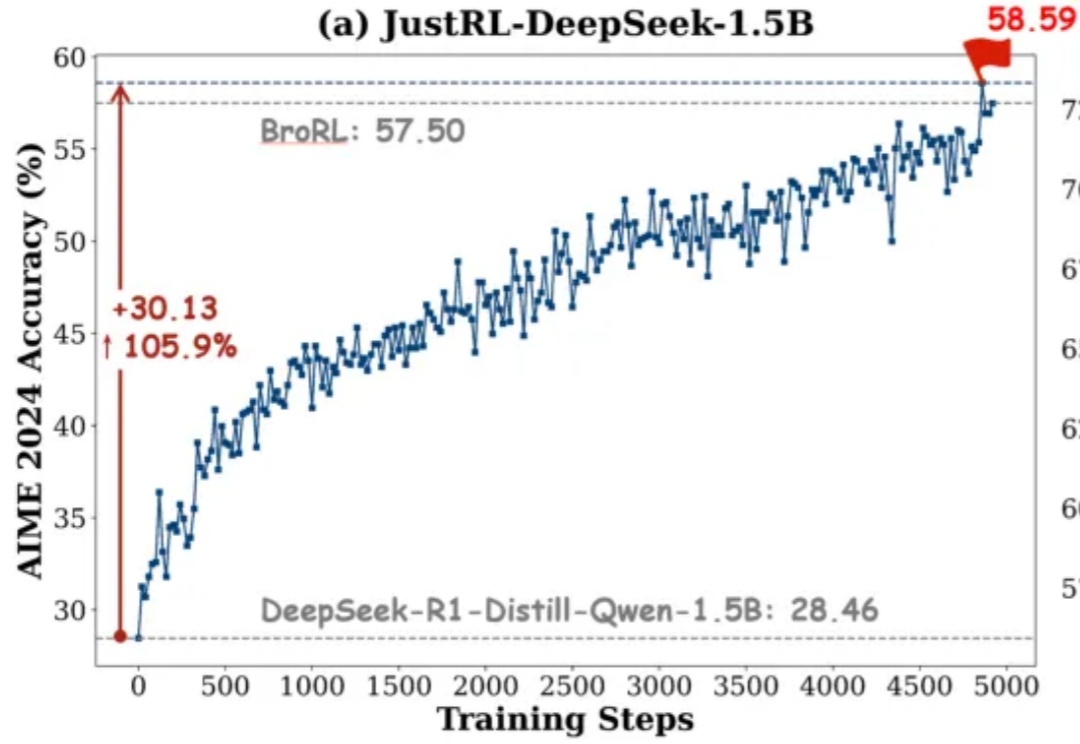
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?