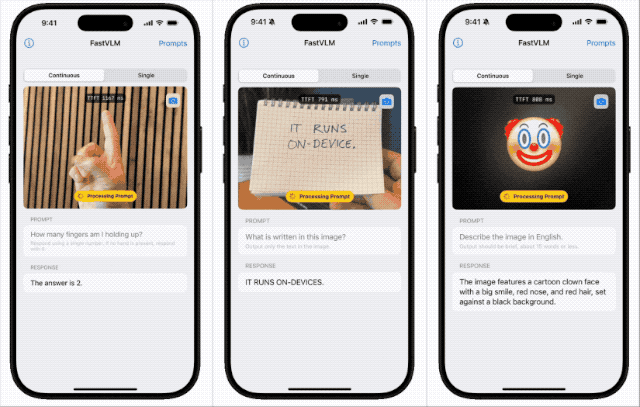
iOS 19还没来,我提前在iPhone上体验到了苹果最新的AI
iOS 19还没来,我提前在iPhone上体验到了苹果最新的AI苹果近期开源本地端侧视觉语言模型FastVLM,支持iPhone等设备本地运行,具备快速响应、低延迟和多设备适配特性。该模型依托自研框架MLX和视觉架构FastViT-HD,通过算法优化实现高效推理,或为未来智能眼镜等新硬件铺路,体现苹果将AI深度嵌入系统底层的战略布局。
来自主题: AI资讯
9622 点击 2025-05-16 15:48
 搜索
搜索
苹果近期开源本地端侧视觉语言模型FastVLM,支持iPhone等设备本地运行,具备快速响应、低延迟和多设备适配特性。该模型依托自研框架MLX和视觉架构FastViT-HD,通过算法优化实现高效推理,或为未来智能眼镜等新硬件铺路,体现苹果将AI深度嵌入系统底层的战略布局。
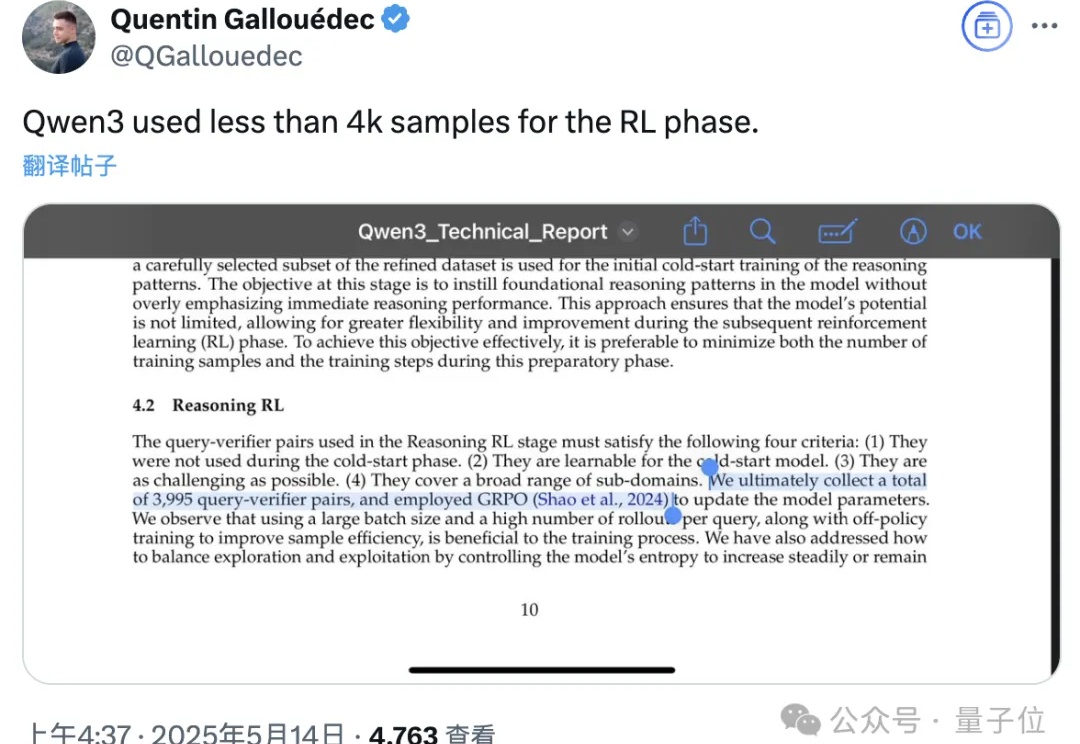
Qwen3技术报告新鲜出炉,8款模型背后的关键技术被揭晓!

E2B 的愿景很大,CEO 的目标是成为 AI Agent 时代的 AWS,成为一个自动化的 infra 平台,未来可以提供 GPU 支持,满足更复杂的数据分析、小模型训练、游戏生成等需求,并可以托管 agent 构建的应用,覆盖 agent 从开发到部署的完整生命周期。

字节Seed首次开源代码模型!Seed-Coder,8B规模,超越Qwen3,拿下多个SOTA。它证明“只需极少人工参与,LLM就能自行管理代码训练数据”。通过自身生成和筛选高质量训练数据,可大幅提升模型代码生成能力。
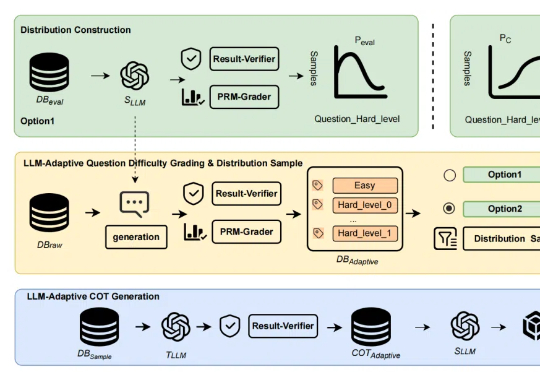
近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。
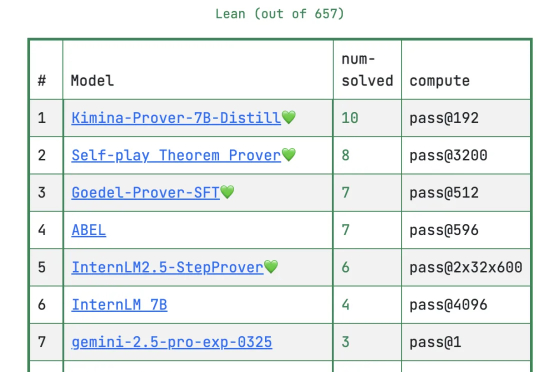
DeepSeek放大招!新模型专注数学定理证明,大幅刷新多项高难基准测试。在普特南测试上,新模型DeepSeek-Prover-V2直接把记录刷新到49道。目前的第一名在657道题中只做出10道题,为Kimi与AIME2024冠军团队Numina合作成果Kimina-Prover。

在人工智能领域,语言模型的发展日新月异,推理能力作为语言模型的核心竞争力之一,一直是研究的焦点,许多的 AI 前沿人才对 AI 推理的效率进行研究。
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!
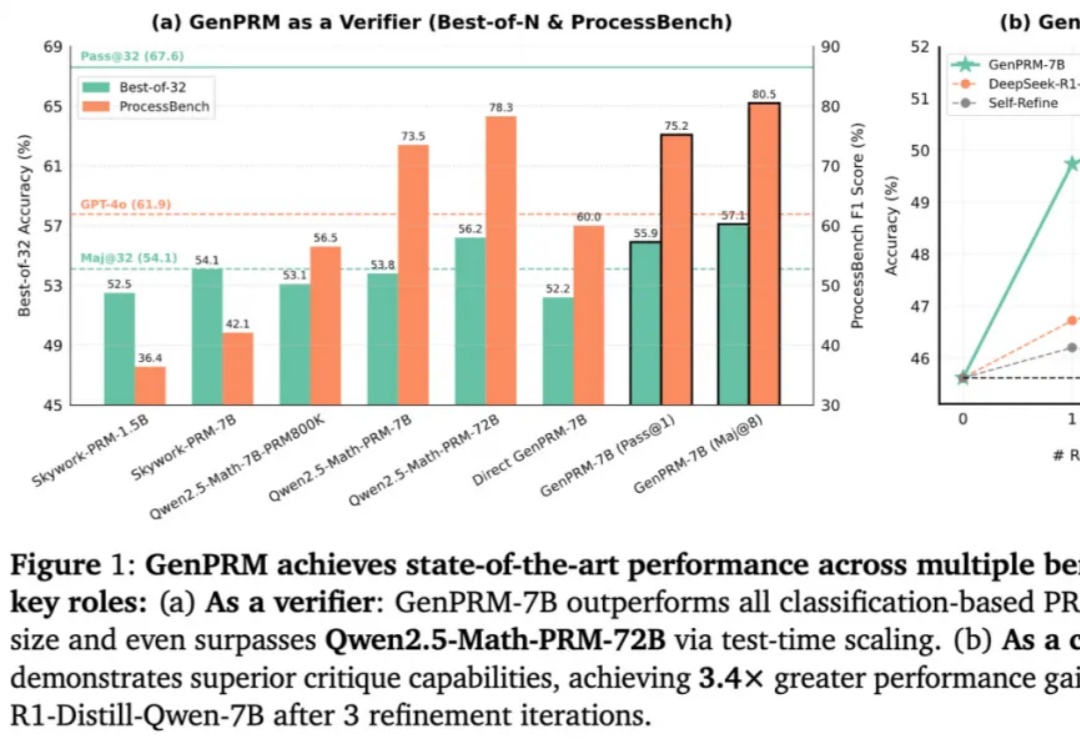
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。

AIMO2最终结果出炉了!英伟达团队NemoSkills拔得头筹,凭借14B小模型破解了34道奥数题,完胜DeepSeek R1。