开源模型突破原生多模态大模型性能瓶颈,上海AI Lab代季峰团队出品
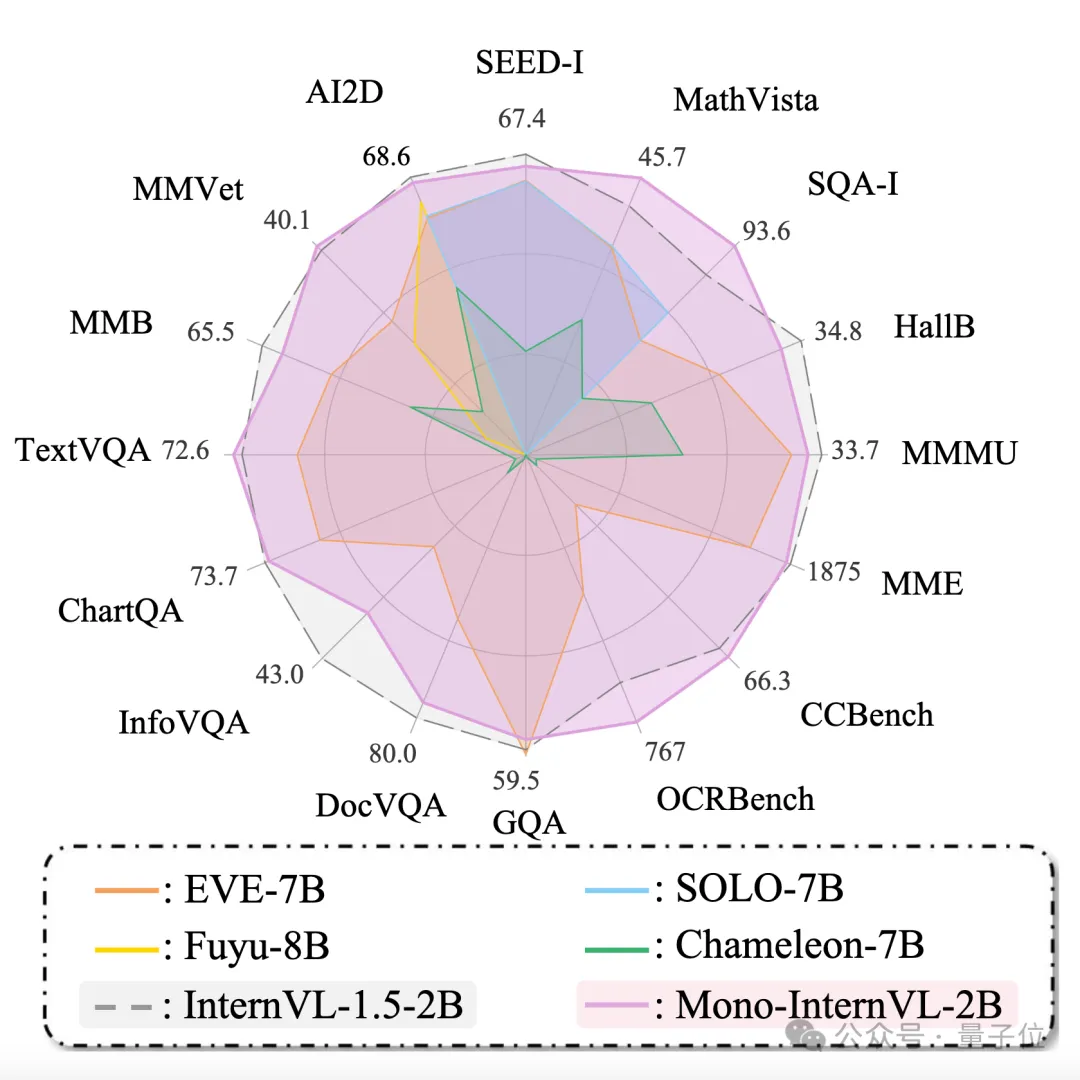
开源模型突破原生多模态大模型性能瓶颈,上海AI Lab代季峰团队出品原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。
来自主题: AI技术研报
6759 点击 2024-10-25 15:37
 搜索
搜索
原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。
苹果研究者发现:无论是OpenAI GPT-4o和o1,还是Llama、Phi、Gemma和Mistral等开源模型,都未被发现任何形式推理的证据,而更像是复杂的模式匹配器。无独有偶,一项多位数乘法的研究也被抛出来,越来越多的证据证实:LLM不会推理!

在医疗领域中,大语言模型已经有了广泛的研究。然而,这些进展主要依赖于英语的基座模型,并受制于缺乏多语言医疗专业数据的限制,导致当前的医疗大模型在处理非英语问题时效果不佳。

在多模态领域,开源模型也超闭源了!

NVLM 1.0系列多模态大型语言模型在视觉语言任务上达到了与GPT-4o和其他开源模型相媲美的水平,其在纯文本性能甚至超过了LLM骨干模型,特别是在文本数学和编码基准测试中,平均准确率提高了4.3个百分点。
北京时间 9 月 13 日午夜,OpenAI 发布了推理性能强大的 ο1 系列模型。之后,各路研究者一直在尝试挖掘 ο1 卓越性能背后的技术并尝试复现它。当然,OpenAI 也想了一些方法来抑制窥探,比如有多名用户声称曾试图诱导 ο1 模型公布其思维过程,然后收到了 OpenAI 的封号威胁。
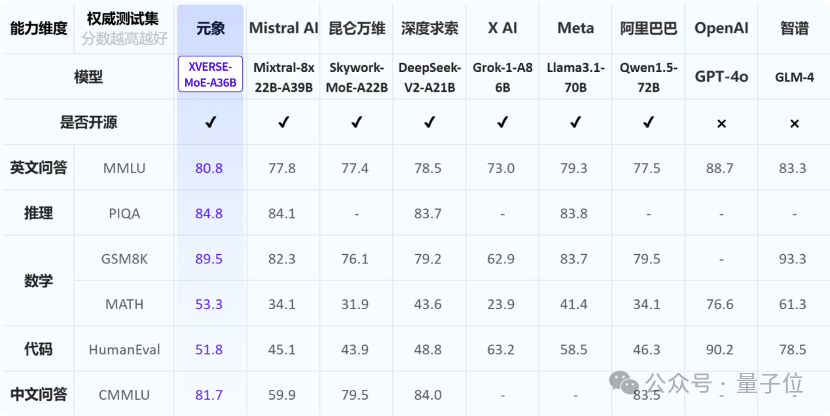
元象XVERSE发布中国最大MoE开源模型:XVERSE-MoE-A36B,该模型总参数255B,激活参数36B,达到100B模型性能的「跨级」跃升。

小型创业团队打造的“最强开源模型”,发布才一周就被质疑造假——

本文出自启元世界多模态算法组,共同一作是来自清华大学的一年级硕士生谢之非与启元世界多模态负责人吴昌桥,研究兴趣为多模态大模型、LLM Agents 等。本论文上线几天内在 github 上斩获 1000+ 星标。

Meta的开源大模型Llama 3在市场上遇冷,进一步加剧了大模型开源与闭源之争的关注热度。