
10人明星团队炼出首个微调Llama 3.1 405B!角色扮演一秒入戏,代码全开源
10人明星团队炼出首个微调Llama 3.1 405B!角色扮演一秒入戏,代码全开源发布40天后,最强开源模型Llama 3.1 405B等来了微调版本的发布。但不是来自Meta,而是一个专注于开放模型的神秘初创Nous Research。
来自主题: AI技术研报
7469 点击 2024-08-16 14:49
 搜索
搜索
发布40天后,最强开源模型Llama 3.1 405B等来了微调版本的发布。但不是来自Meta,而是一个专注于开放模型的神秘初创Nous Research。

大语言模型 (LLM) 经历了重大的演变,最近,我们也目睹了多模态大语言模型 (MLLM) 的蓬勃发展,它们表现出令人惊讶的多模态能力。 特别是,GPT-4o 的出现显著推动了 MLLM 领域的发展。然而,与这些模型相对应的开源模型却明显不足。开源社区迫切需要进一步促进该领域的发展,这一点怎么强调也不为过。
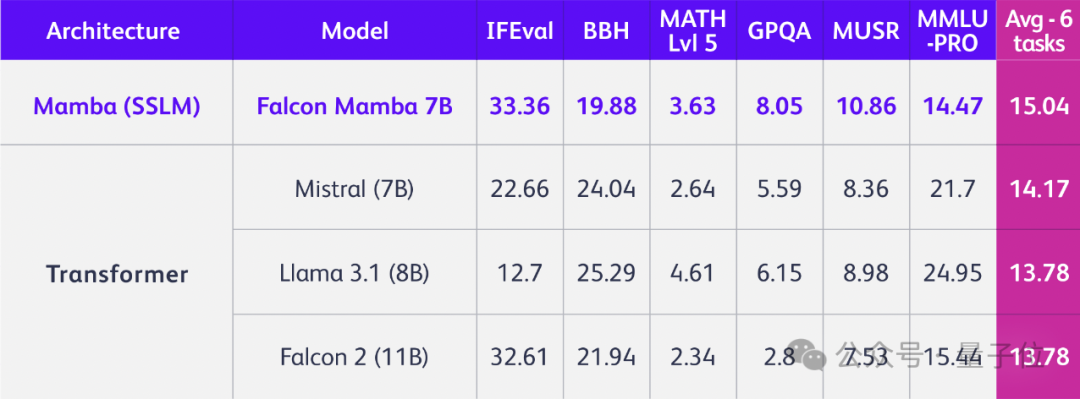
只是换掉Transformer架构,立马性能全方位提升,问鼎同规模开源模型!
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

换了发型的扎克伯格越来越不像机器人了。 这是网友们对扎克伯格最近形象转变的普遍评价,但看顺眼的网友更多是对他旗下 Meta 公司的认可。 时间往回倒退 3 年,当时的「Facebook」或许还指望着改名转运。
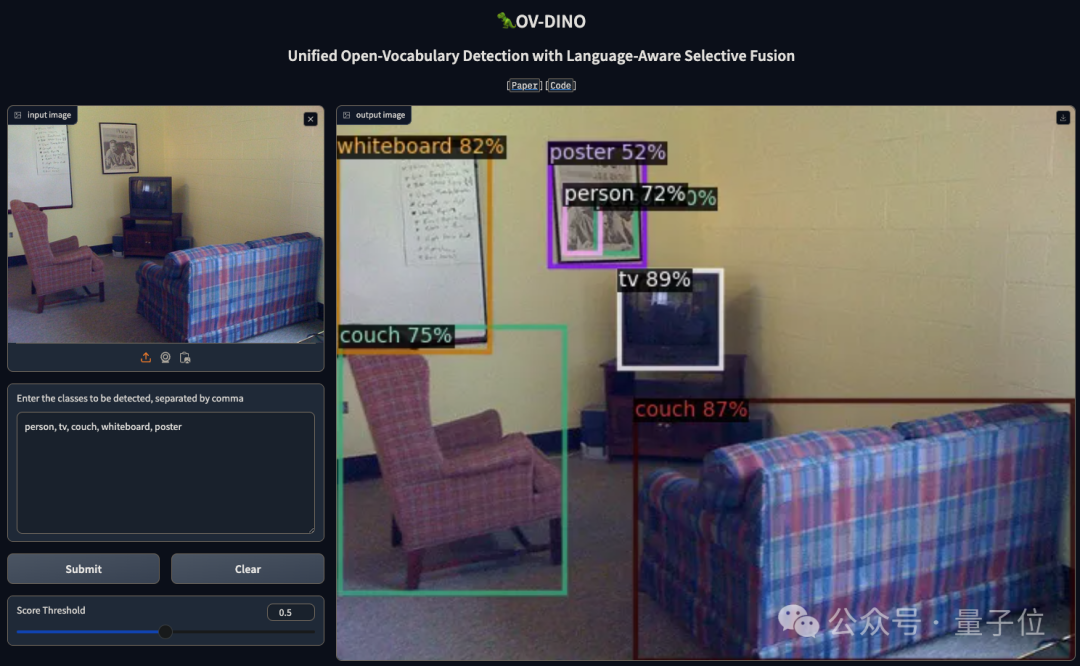
开放域检测领域,迎来新进展——

又是发布即开源! Meta“分割一切AI”二代SAM2在SIGGRAPH上刚刚亮相。

自 1974 年在科罗拉多州博尔德市首次举办以来,SIGGRAPH一直是展示计算机图形领域开创性研究的一个主要平台。

适逢Llama 3.1模型刚刚发布,英伟达就发表了一篇技术博客,手把手教你如何好好利用这个强大的开源模型,为领域模型或RAG系统的微调生成合成数据。

榨干16000块H100、基于15亿个Tokens训练。