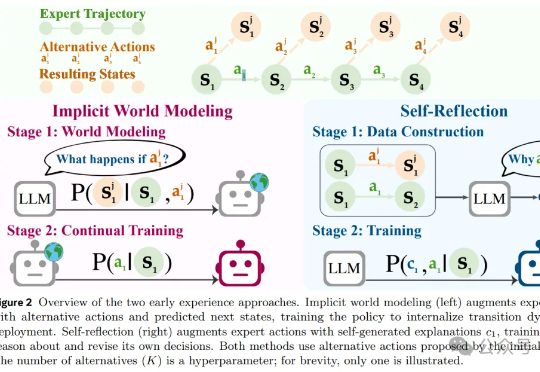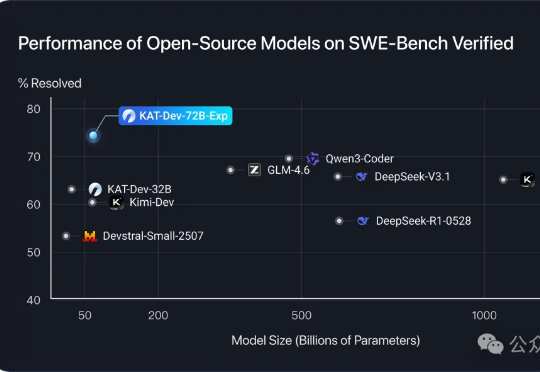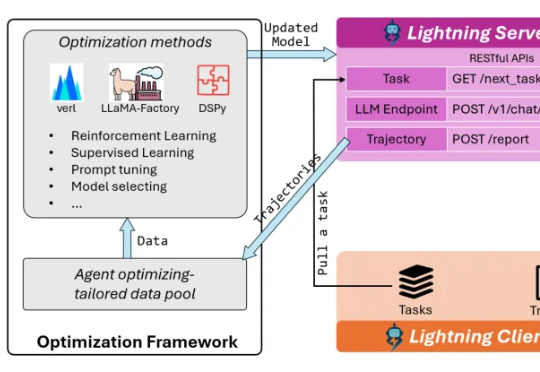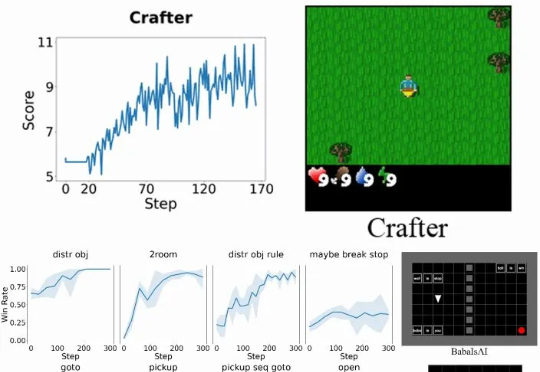
腾讯开源强化学习新算法!让智能体无需专家示范就“自学成才”,还即插即用零成本接入
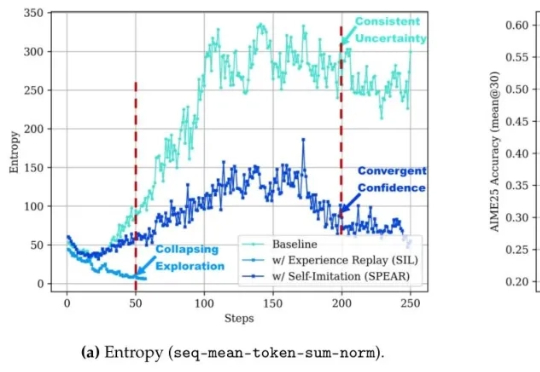
腾讯开源强化学习新算法!让智能体无需专家示范就“自学成才”,还即插即用零成本接入让智能体自己摸索新方法,还模仿自己的成功经验。腾讯优图实验室开源强化学习算法——SPEAR(Self-imitation with Progressive Exploration for Agentic Reinforcement Learning)。
来自主题: AI技术研报
8756 点击 2025-10-13 15:45