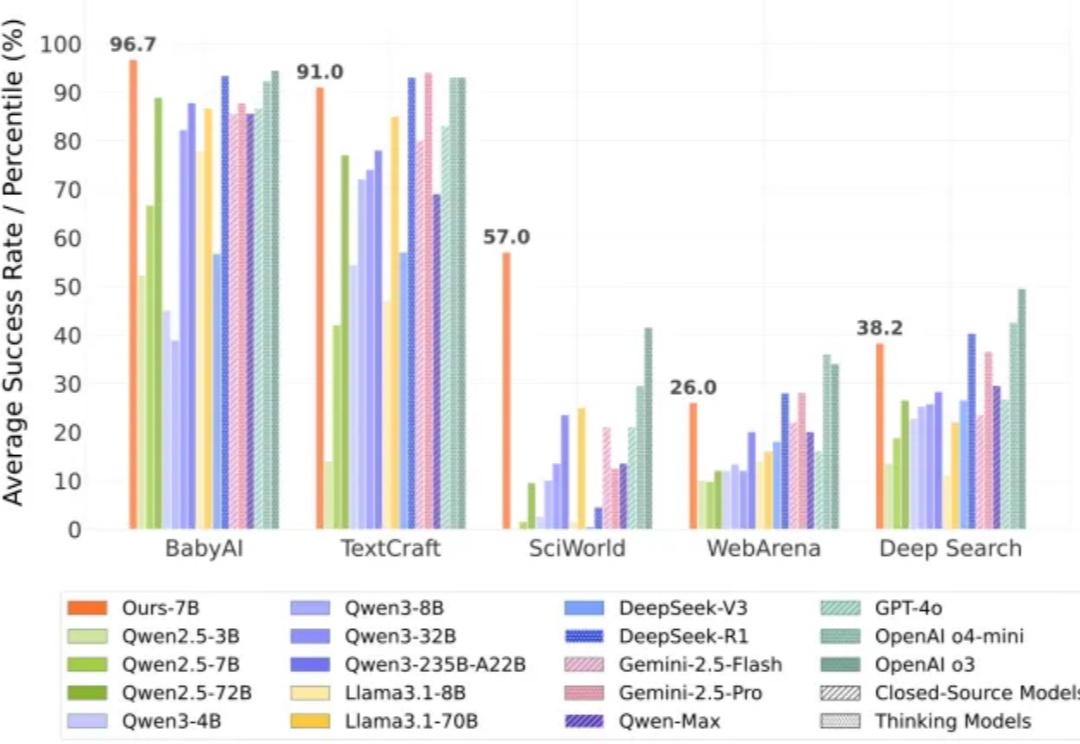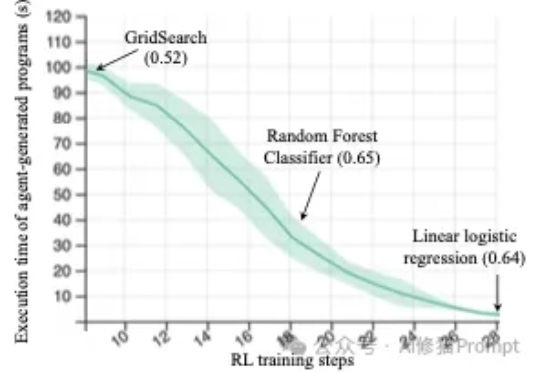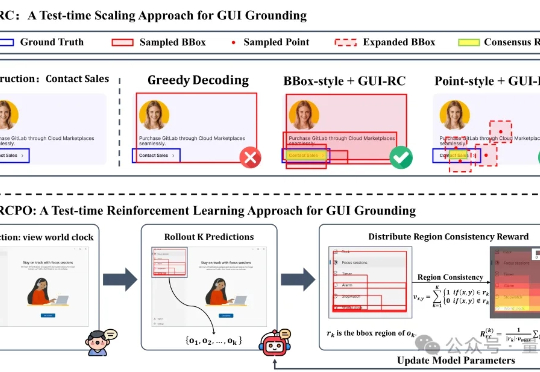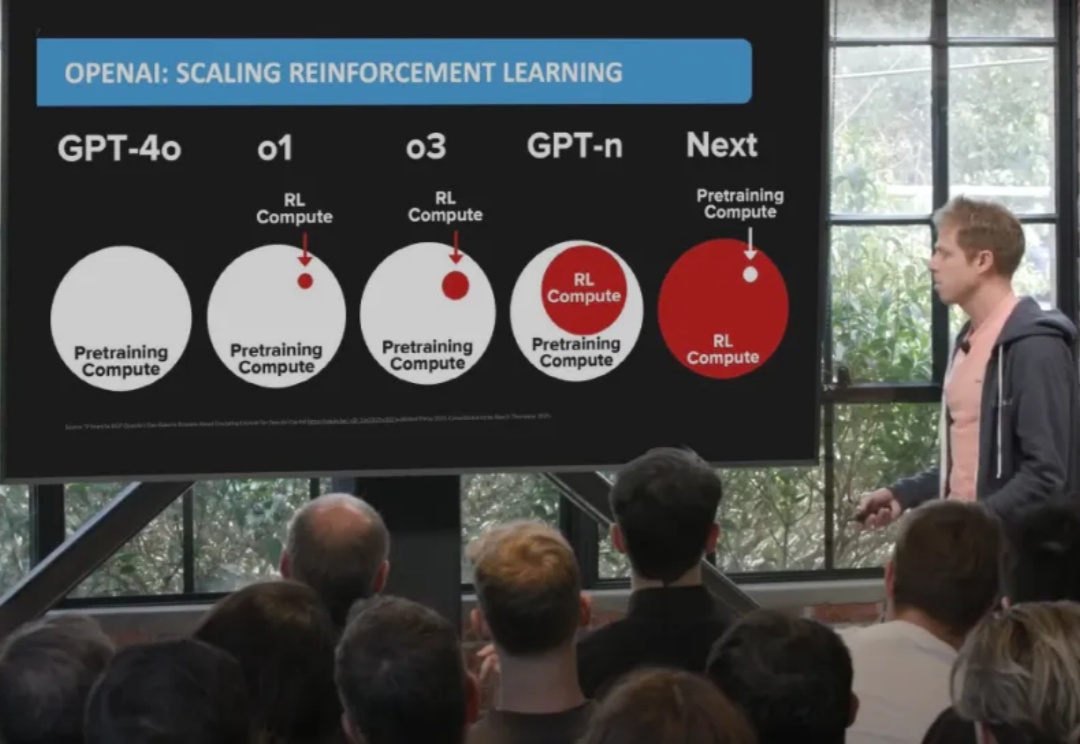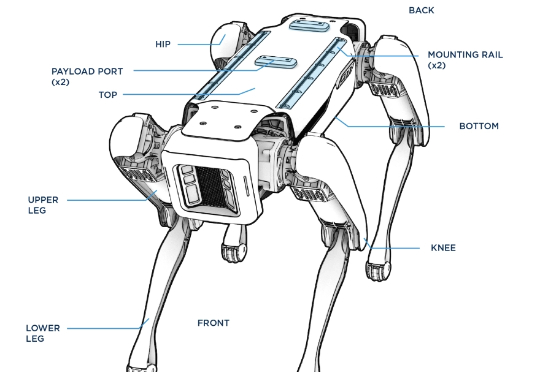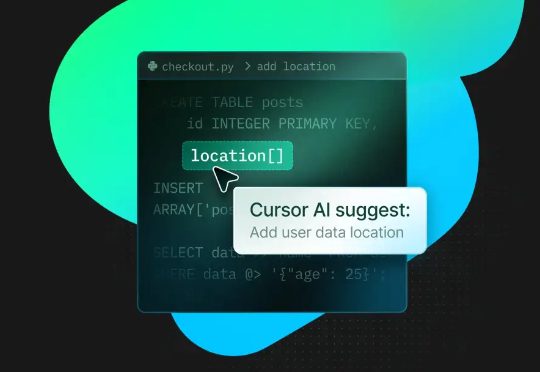
为这一个Tab键,我愿意单独付费:Cursor用在线强化学习优化代码建议,护城河有了?
为这一个Tab键,我愿意单独付费:Cursor用在线强化学习优化代码建议,护城河有了?Cursor Tab 是 Cursor 的核心功能之一,它通过分析开发者的编码行为,智能预测并推荐后续代码,开发者仅需按下 Tab 键即可采纳。然而,它也面临着一个 AI 普遍存在的难题:「过度热情」。有时,它提出的建议不仅毫无用处,甚至会打断开发者的思路。
来自主题: AI技术研报
9634 点击 2025-09-14 21:34