# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前的AI Agent在训练与优化环节却面临着严峻挑战,传统强化学习方法也在复杂、动态交互场景下表现不佳。
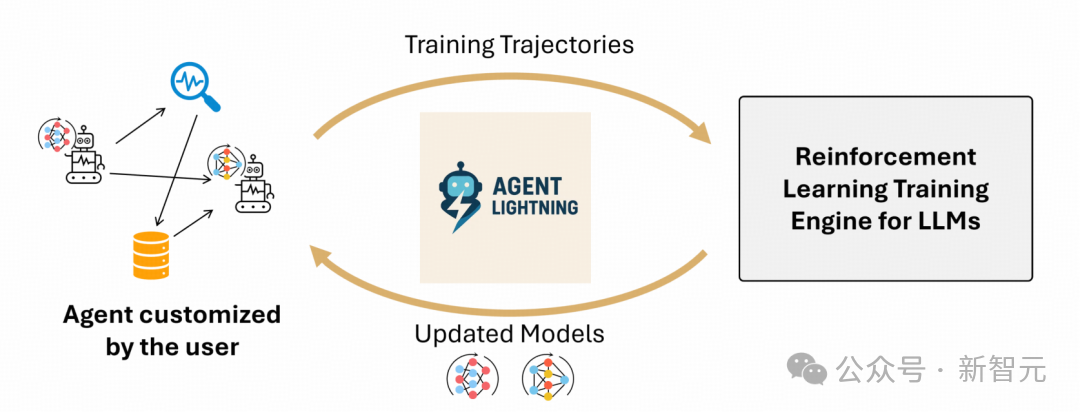
为此,微软团队推出了一个灵活、可扩展的框架Agent Lightning,其可对任何AI Agent进行基于强化学习的LLM训练,有望重塑AI Agent的未来训练范式。相关研究论文已发表在预印本网站arXiv上。

论文链接:https://arxiv.org/abs/2508.03680
核心贡献如下:
Agent Lightning:
训练任意AI Agent
在真实世界中,AI Agent的运行逻辑极为复杂,绝非简单的一问一答模式。
它们常常需要多轮交互,像人类对话一样循序渐进推进任务,通过调用外部工具或API,与外部系统交互获取更多信息,依据环境反馈和当前状态灵活做出动态决策,甚至在复杂场景中,多个Agent需协同合作完成任务。
但现有强化学习训练框架,往往将强化学习训练过程与Agent的具体执行逻辑紧密捆绑,导致一系列问题,严重阻碍了强化学习在AI Agent大规模训练和部署中的应用。
例如:
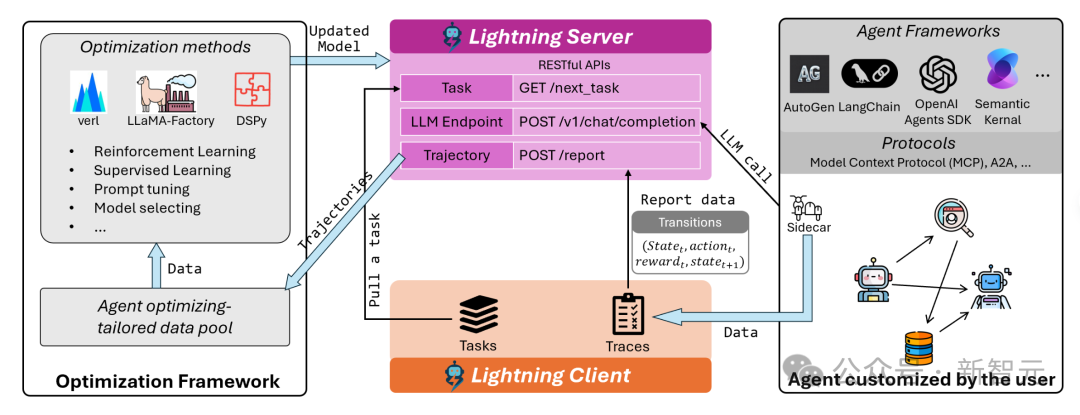
微软此次提出的Agent Lightning框架的核心创新点,在于实现了AI Agent执行与强化学习训练之间的彻底解耦。二者可独立运作,又能进行信息交换。
Agent Lightning概述
除了上述提到的完全解耦和统一数据接口之外,Lightning RL也是该研究的主要亮点之一。
LightningRL是微软为利用收集到的转换数据优化策略LLM,而提出的专为Agent训练设计的分层强化学习算法。
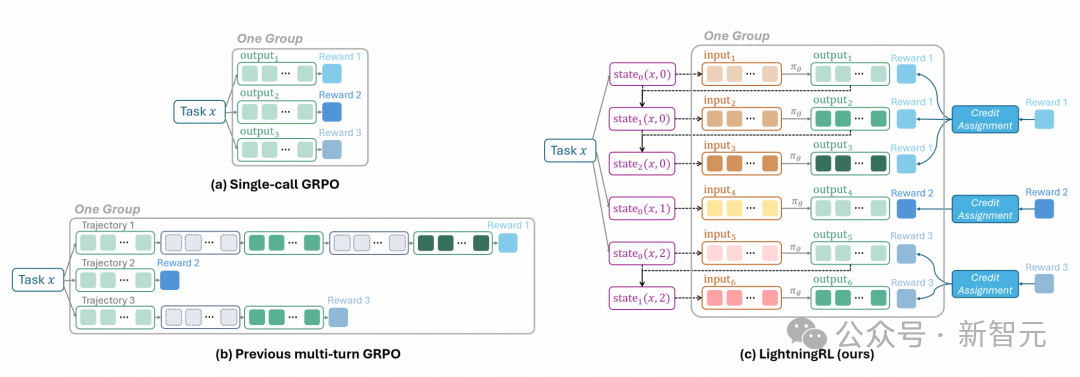
LightningRL示意图
该算法包含信用分配模块,能够将任何Agent生成的轨迹分解为训练所需的转换数据,从而使强化学习能够处理复杂的交互逻辑,如多Agent场景和动态工作流。
在信用分配过程中,高层信用分配首先将整个任务的最终奖励合理分配到任务执行过程中的每一步骤,例如在最简单实现中,可让每一次调用的奖励都等于最终奖励。
经过高层信用分配后,低层策略更新将每一次LLM调用(input、output、reward)转化为一个独立的单次调用强化学习问题。
此时可直接套用任何现成的、成熟的单次调用强化学习算法(如PPO、DPO或GRPO),来更新模型参数。
这种设计不仅具备灵活性和复用性,可直接利用社区中SOTA单次调用强化学习算法,还从根本上解决了因上下文累积导致的序列过长问题,避免了复杂易错的掩码操作。
Agent Lightning将计算密集型的LLM生成与传统编程语言编写、轻量级但多样化且灵活的应用逻辑和工具分离。
在系统设计方面,Agent Lightning引入了Training-Agent解耦架构,构建了一个适用于任意Agent的标准化训练服务。
该架构由Agent Lightning Server和Agent Lightning Client组成。
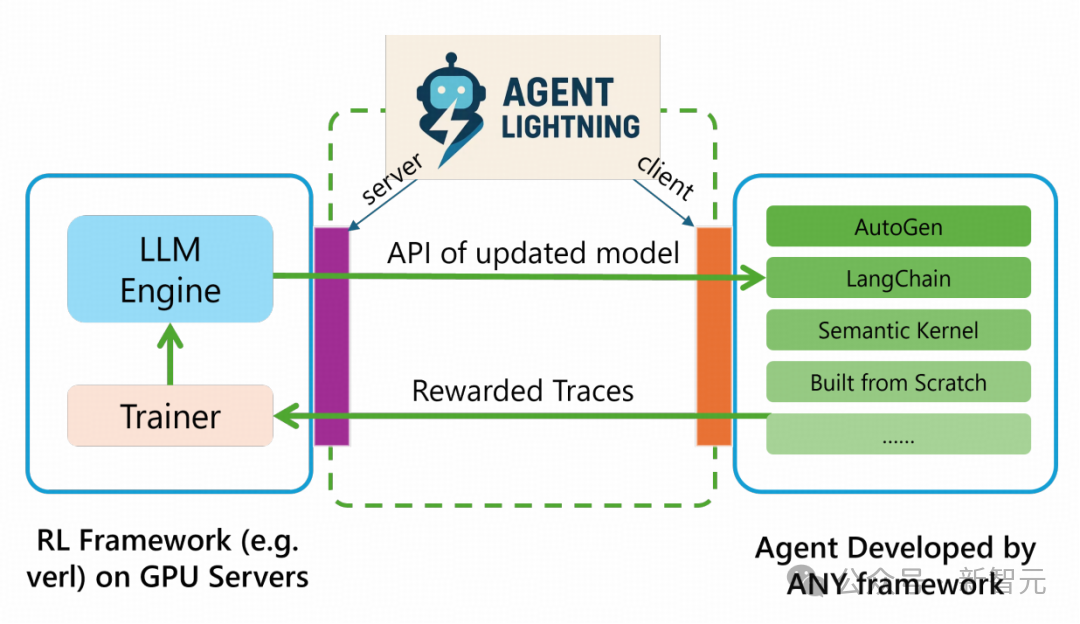
Training-Agent解耦架构
Agent Lightning Server:作为强化学习训练系统的大脑,承担着管理训练流程的重任,并通过类OpenAI API向客户端暴露更新后的模型。它负责运行强化学习训练算法、分配GPU资源、管理模型版本等一系列复杂且计算密集型的任务。
Agent Lightning Client:包含两个功能模块:一个模块负责与服务器通信,实现数据传输与接收;另一个模块运行Agent并执行数据收集,充当Agent的运行时环境。
得益于统一数据接口,Agent运行时能够将OpenTelemetry等全面的可观测性框架集成到训练过程中,用于轨迹收集。
这一机制将监控基础设施与强化学习训练连接起来,使优化算法能够利用丰富的系统监控数据,从而构建更具可扩展性与灵活性的训练基础。
这种前后端分离式的架构设计,彻底将Agent开发者从复杂的强化学习系统配置中解放出来,让他们得以专注于Agent本身的逻辑和创意,极大降低了AI Agent进化的门槛。
实验结果
研究团队在多个任务上对Agent Lightning框架进行了实验验证,涵盖Text-to-SQL、开放域问答、数学问答等。
在这些实验中,Agent Lightning均展示出稳定且持续的性能提升。
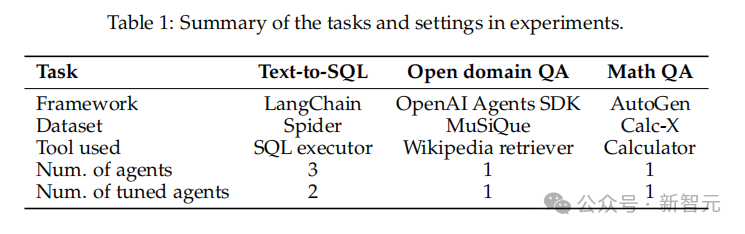
实验中任务和设置的总结
通过LangChain实现Text-to-SQL
第一个任务采用LangChain实现,设计为多Agent系统架构。
系统包含三个Agent,工作流程如下:
SQL writing agent首先会生成SQL查询语句并执行。
若查询正确,SQL executor会返回数据库信息;若出错,则返回错误提示。
随后,checking agent评估SQL查询的正确性及检索信息的有效性和完整性,并决定是重写查询还是直接生成答案。
若需重写,re-writing agent将根据checking agent的反馈修改查询语句;若无需重写,该agent同时承担问答任务,利用检索到的信息和问题生成最终答案。
在此工作流程中,SQL写入(writing)、校验(checking)和重写(re-writing)均由同一LLM完成,但针对不同任务定制了专属提示,从而实现三个Agent协同运作。
在训练过程中,研究团队只对其中两个进行了优化,即SQL writing agent和re-writing Agent,这两个agent是同步进行优化的,说明Agent Lightning 可以在多Agent系统中选择性地对一个或多个Agent进行优化。
如图,Agent Lightning能够稳定地提高奖励,展示了其优化涉及代码生成和工具使用的复杂多步决策的能力。
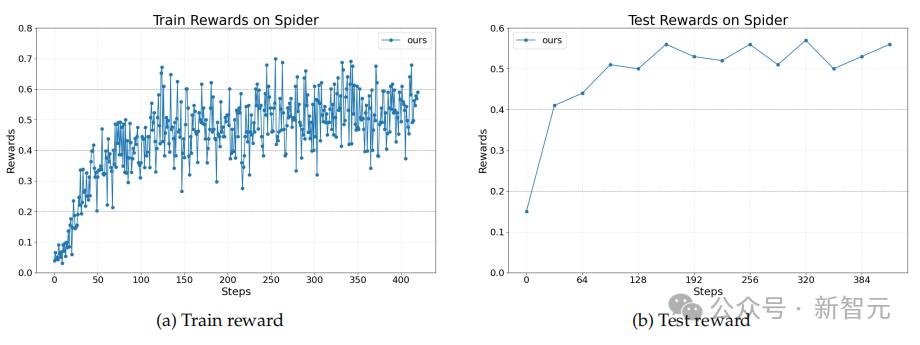
Text-to-SQL任务的奖励曲线
通过OpenAI Agent SDK实现检索增强生成
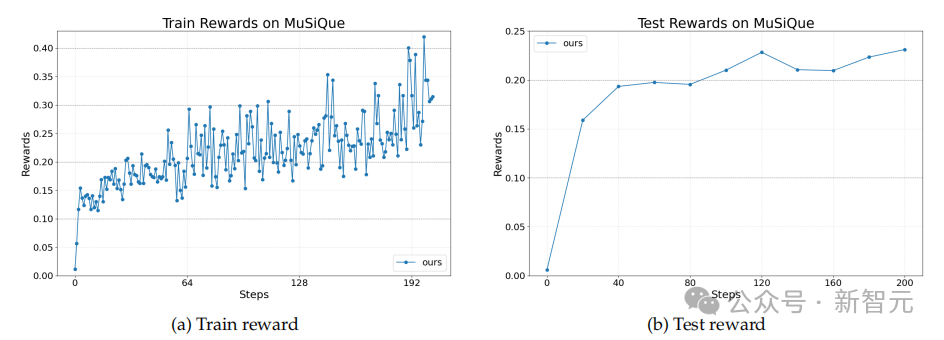
第二个任务是典型的检索增强生成(RAG)任务。
给定一个问题和文档数据库,Agent首先会生成自然语言查询,通过现有检索工具获取支持性文档。
该Agent是使用OpenAI Agent SDK实现的。与之前的Text-to-SQL任务相比,这里的Agent工作流程类似但更简单。
策略LLM需要先生成查询请求,然后根据检索到的文档决定是优化查询还是直接生成答案。
该图展示了Agent Lightning在这一具有挑战性的任务上实现了稳定的性能提升,证明了其在更复杂和开放式RAG场景中的有效性。
通过AutoGen实现数学问答与工具使用
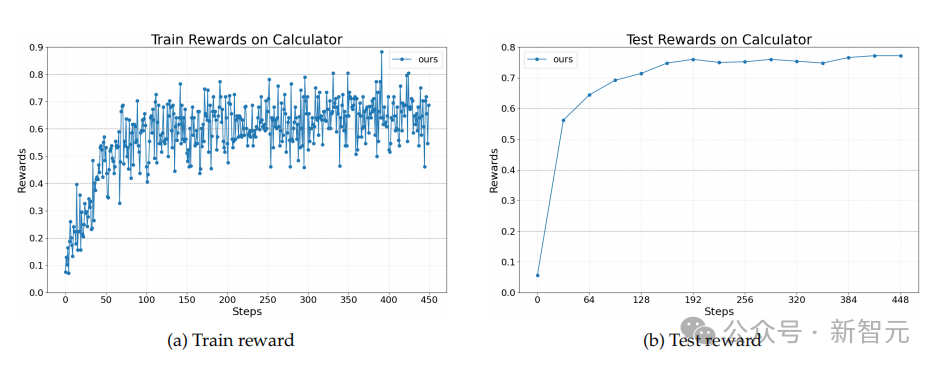
第三个任务是数学类问答任务,旨在评估Agent调用工具(具体指计算器)解决算术和符号问题的能力。
最终的奖励取决于Agent是否正确回答了问题,模型的性能也通过测试集上的答案准确度进行评估。
如图,Agent Lightning在训练过程中持续提高了性能。这证明了它在工具增强设置中的有效性,即需要精确的外部函数调用和推理。
未来方向:推动Agent能力迭代升级
在论文的最后,研究团队也探讨了未来的工作方向。
首先,除了强化学习外,Agent Lightning建模框架还很好地支持其他优化方法,如自动prompt优化。
关注关键组件及其调用是Agent优化的主要方法,而不仅仅局限于基于强化学习的方法。
为此,团队提出了Component of Interest(CoI)的概念,用于指定执行轨迹中受优化影响的组件子集。
例如,prompt模板渲染可视为工具调用,通过将该工具视为CoI,Agent Lightning可支持prompt优化方法。
这种统一且可扩展的数据结构支持对Agent行为进行全面的下游优化与分析。
其次,研究团队认为,开发更高效的强化学习算法是解决复杂Agent场景下模型优化的关键,包括但不限于长程信用分配、探索算法、off-policy算法等。
Agent Lightning通过过渡来建模和组织数据,使集成额外算法更加方便。
此外,支持LLM的强化学习基础设施持续演进,为与基于Agent的强化学习框架的协同开发提供了重大机会。
一个有前景的方向是进一步分解系统组件,即将训练器、推断引擎和Agent工作流程分离,以解决推断瓶颈并提升大规模强化学习训练的可扩展性。
探索此类架构改进可带来更高效且灵活的强化学习管道。
此外,针对长程任务的优化将受益于强化学习算法与系统设计协同创新,从而实现复杂Agent更高效的训练。
最后,在LLM高效服务方面,研究团队建议采用更适合LLM的抽象方法,可以优化资源利用率和响应时间。
此外,通过优化服务环境和工具的资源调度,还能进一步简化操作流程,提高在多样化部署场景中的扩展能力。
随着Agent Lightning框架解决了强化学习与Agent耦合的难题,强化学习有望成为Agent训练的标配。
同时,Agent在真实世界中产生的海量交互数据,将不再被闲置浪费。
Agent Lightning的统一数据接口,能够高效地将这些数据用于强化学习训练,推动Agent能力迭代升级。
参考资料:
https://www.microsoft.com/en-us/research/project/agent-lightning/
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
