
腾讯混元最新开源:一套RL框架打通多个模态,庞天宇团队新作
腾讯混元最新开源:一套RL框架打通多个模态,庞天宇团队新作大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
来自主题: AI技术研报
7705 点击 2026-06-18 11:25
 搜索
搜索
大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。

Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。
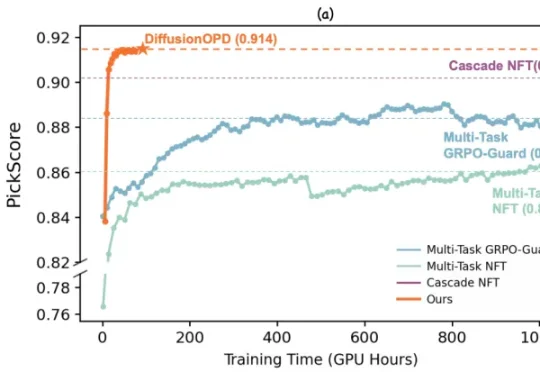
近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

AI科技评论独家消息,前月之暗面后训练与强化学习负责人宋鸿涌(Flood Sung)已于 2025 年 12 月离职,创立机器人公司「北京十六号机器人科技有限公司」(XVI Robotics),公司业务方向聚焦通用人形机器人基座模型。
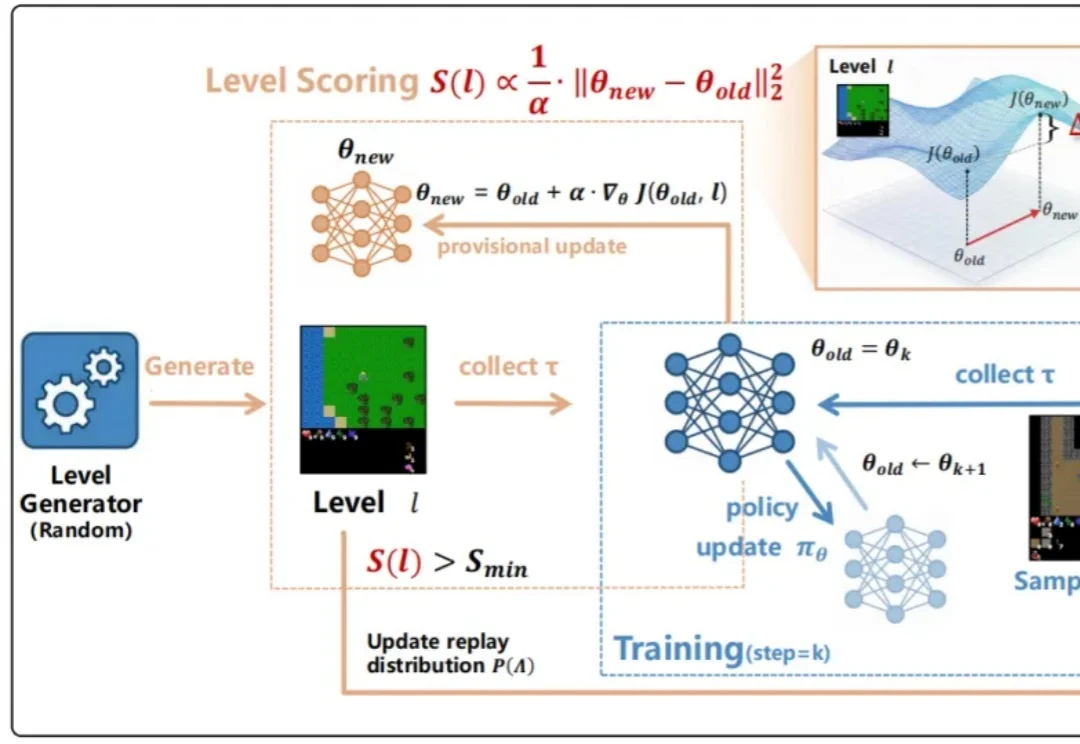
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。
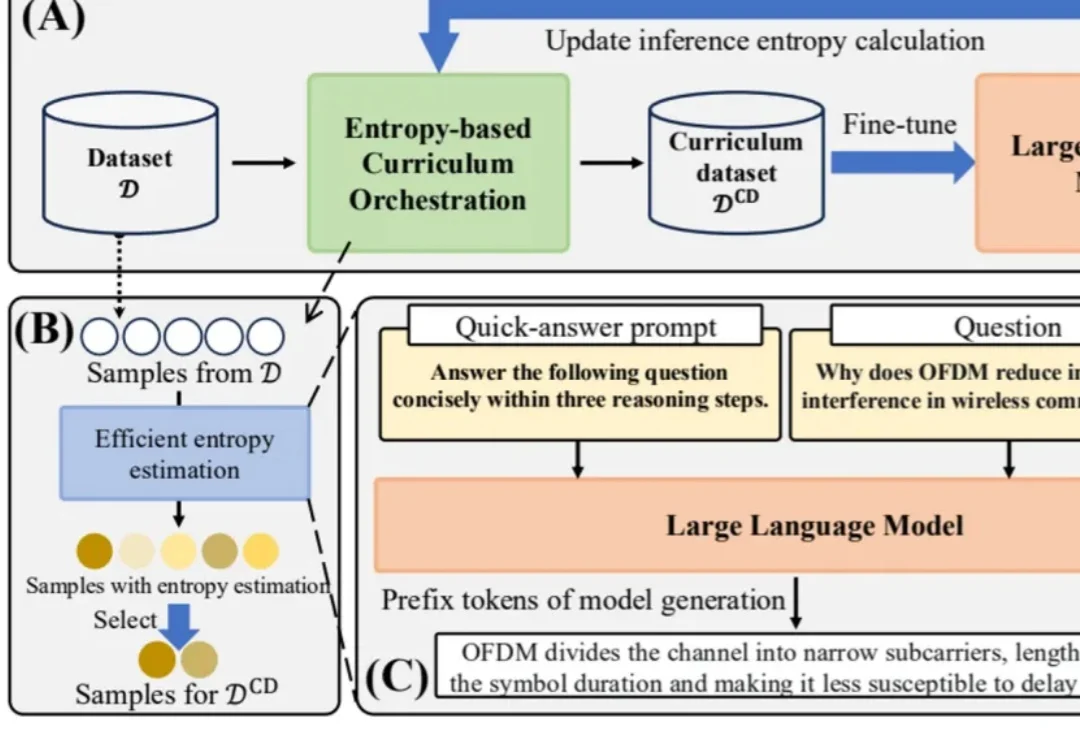
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。