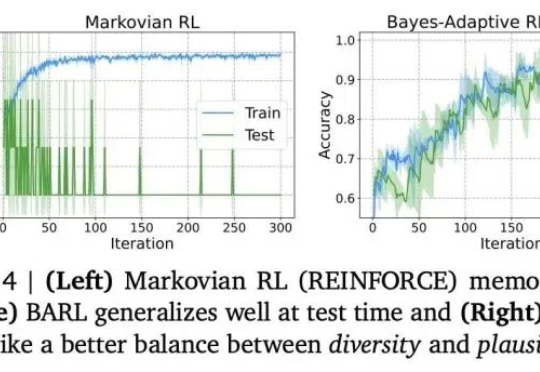
首次解释LLM如何推理反思!西北大学谷歌新框架:引入贝叶斯自适应强化学习,数学推理全面提升
首次解释LLM如何推理反思!西北大学谷歌新框架:引入贝叶斯自适应强化学习,数学推理全面提升推理模型常常表现出类似自我反思的行为,但问题是——这些行为是否真的能有效探索新策略呢?
来自主题: AI技术研报
8443 点击 2025-06-02 17:48
 搜索
搜索
推理模型常常表现出类似自我反思的行为,但问题是——这些行为是否真的能有效探索新策略呢?
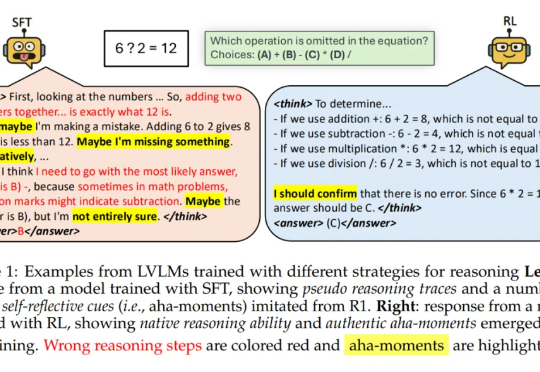
「尽管经过 SFT 的模型可能看起来在进行推理,但它们的行为更接近于模式模仿 —— 一种缺乏泛化推理能力的伪推理形式。」
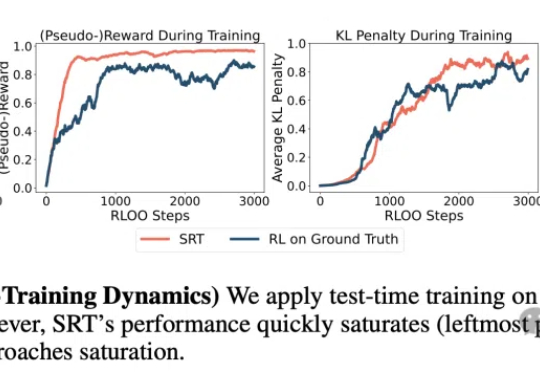
数据枯竭正成为AI发展的新瓶颈!CMU团队提出革命性方案SRT:让LLM实现无需人类标注的自我进化!SRT初期就能迭代提升数学与推理能力,甚至性能逼近传统强化学习的效果,揭示了其颠覆性潜力。

来和机器狗一起运动不?你的羽毛球搭子来了!无需人工协助,仅靠强化学习,机器狗子就学会了羽毛球哐哐对打。基于强化学习,研究人员开发了机器狗的全身视觉运动控制策略,同步控制腿部(18个自由度)移动,和手臂挥拍动作。

复刻DeepSeek-R1的长思维链推理,大模型强化学习新范式RLIF成热门话题。
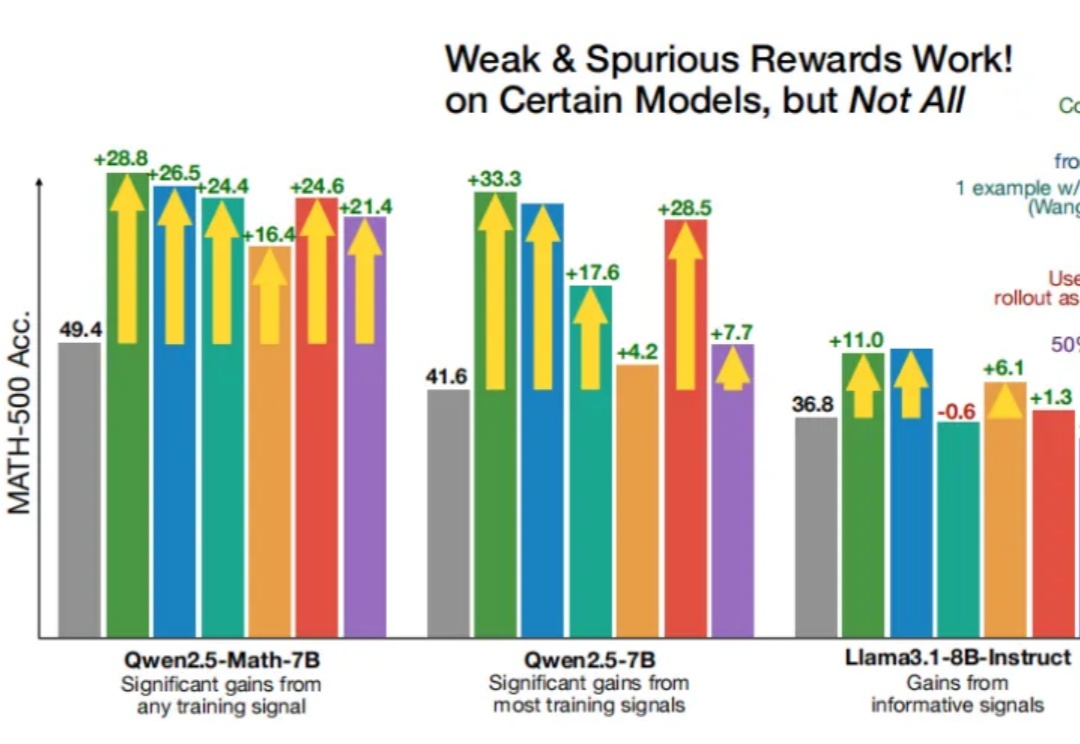
即使RLVR(可验证奖励强化学习)使用错误的奖励信号,Qwen性能也能得到显著提升?
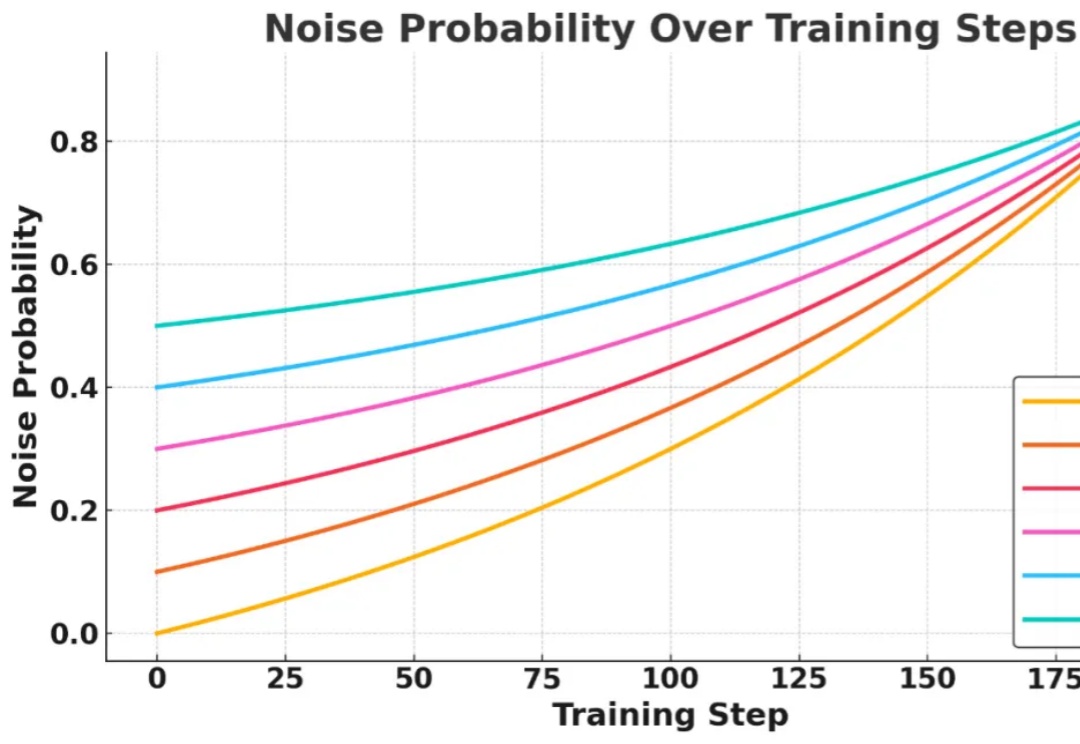
信息检索能力对提升大语言模型 (LLMs) 的推理表现至关重要,近期研究尝试引入强化学习 (RL) 框架激活 LLMs 主动搜集信息的能力,但现有方法在训练过程中面临两大核心挑战:
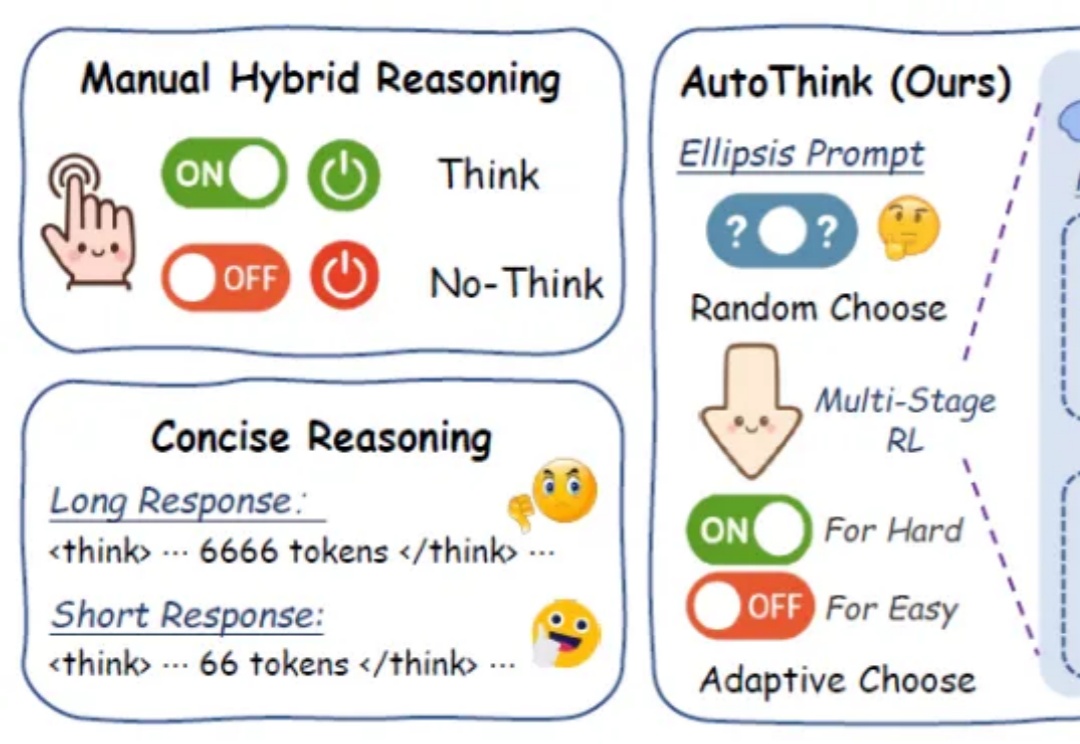
在日益强调“思维能力”的大语言模型时代,如何让模型在“难”的问题上展开推理,而不是无差别地“想个不停”,成为当前智能推理研究的重要课题。
仅需一个强化学习(RL)框架,就能实现视觉任务大统一?
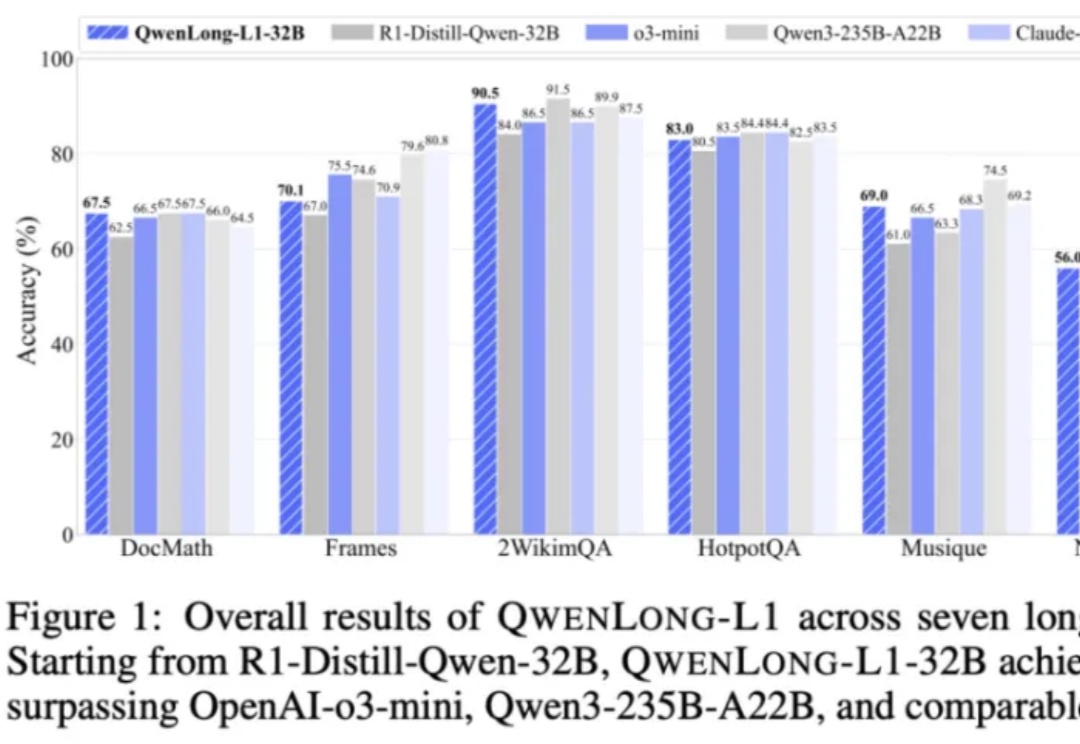
上下文长度达 13 万 token,适用于多段文档综合分析、金融、法律、科研等复杂领域任务。