
OpenAI首席科学家Nature爆料:AI自主发现新科学!世界模型和RL是关键
OpenAI首席科学家Nature爆料:AI自主发现新科学!世界模型和RL是关键近日,《自然》杂志独家专访了OpenAI首席科学家Jakub Pachocki,他揭示了推理模型、强化学习如何赋予AI自主发现科学的能力,并分享了AI如何在五年内重塑科学研究与经济格局的雄心。
来自主题: AI资讯
9349 点击 2025-05-14 11:42
 搜索
搜索
近日,《自然》杂志独家专访了OpenAI首席科学家Jakub Pachocki,他揭示了推理模型、强化学习如何赋予AI自主发现科学的能力,并分享了AI如何在五年内重塑科学研究与经济格局的雄心。

80年代,当强化学习被冷落,这对师徒没有放弃;如今,重看来时路,他们给出的建议仍然是,「坚持」住自己的科研思想。
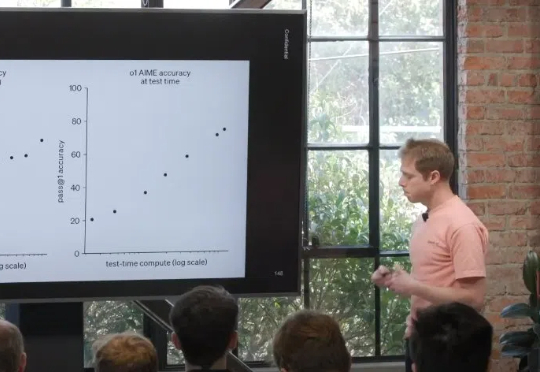
近日,在红杉资本主办的 AI Ascent 上,OpenAI 研究科学家 Dan Roberts 做了主题为「接下来的未来 / 扩展强化学习」的演讲,其上传到 YouTube 的版本更是采用了一个更吸引人的标题:「9 年实现 AGI?OpenAI 的 Dan Roberts 推测将如何模拟爱因斯坦。」
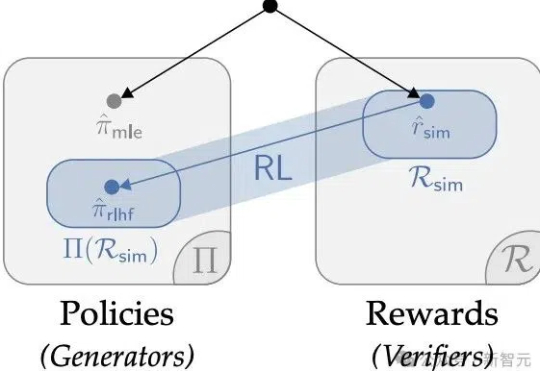
华人学者参与的一项研究,重新确立了强化学习在LLM微调的价值,深度解释了AI训练「两阶段强化学习」的原因。某种意义上,他们的论文说明RL微调就是统计。
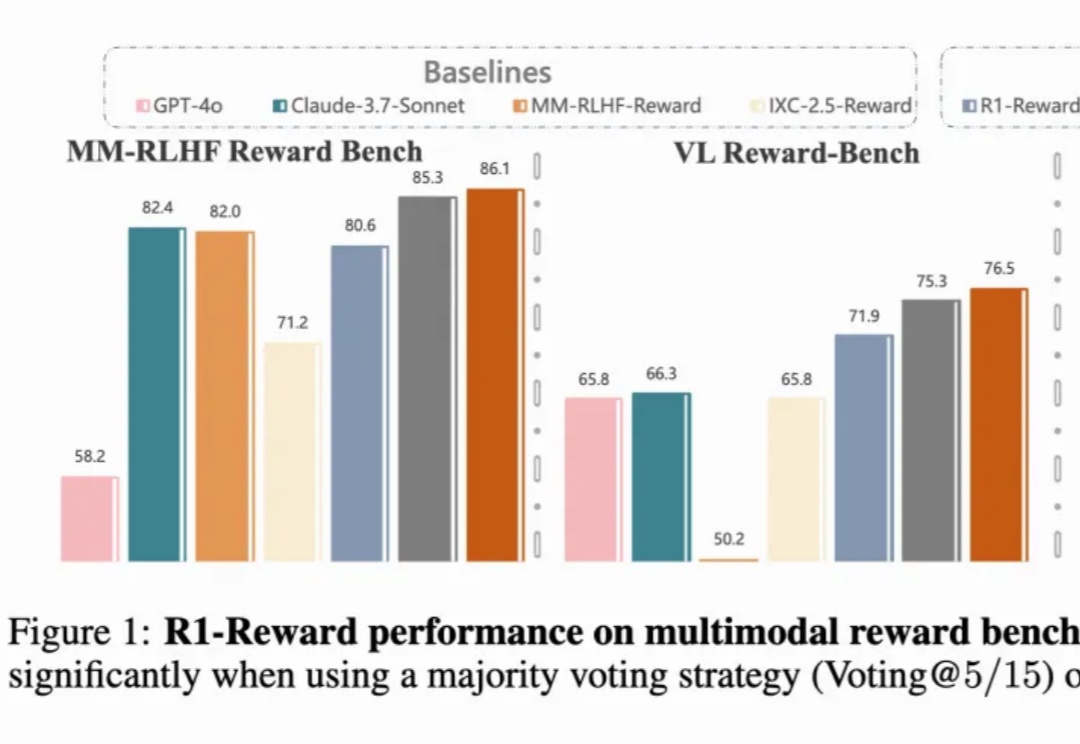
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:
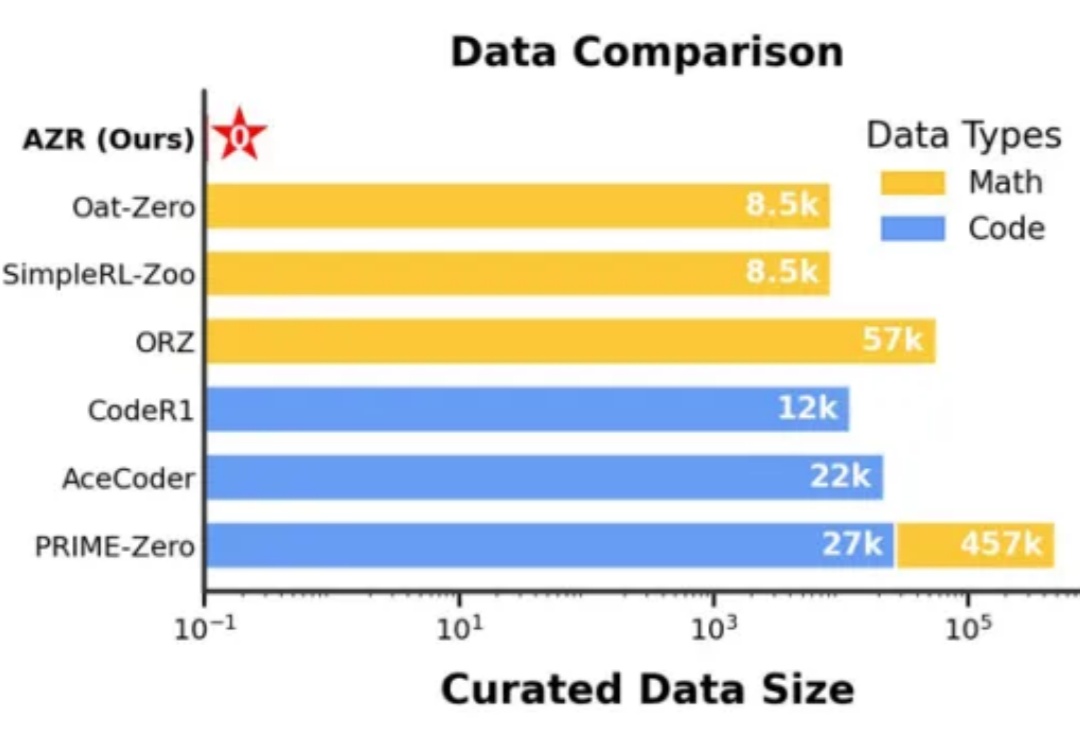
在人工智能领域,推理能力的进化已成为通向通用智能的核心挑战。近期,Reinforcement Learning with Verifiable Rewards(RLVR)范式下涌现出一批「Zero」类推理模型,摆脱了对人类显式推理示范的依赖,通过强化学习过程自我学习推理轨迹,显著减少了监督训练所需的人力成本。

本周三,知名 AI 创业公司,曾发布「全球首个 AI 软件工程师」的 Cognition AI 开源了一款使用强化学习,用于编写 CUDA 内核的大模型 Kevin-32B。

强化学习(RL)是当今 AI 领域最热门的词汇之一。近日,一篇长文梳理了新时代的强化学习范式对于模型提升的作用,同时还探索了强化学习对去中心化的意义。

随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。

本文深入梳理了围绕DeepSeek-R1展开的多项复现研究,系统解析了监督微调(SFT)、强化学习(RL)以及奖励机制、数据构建等关键技术细节。