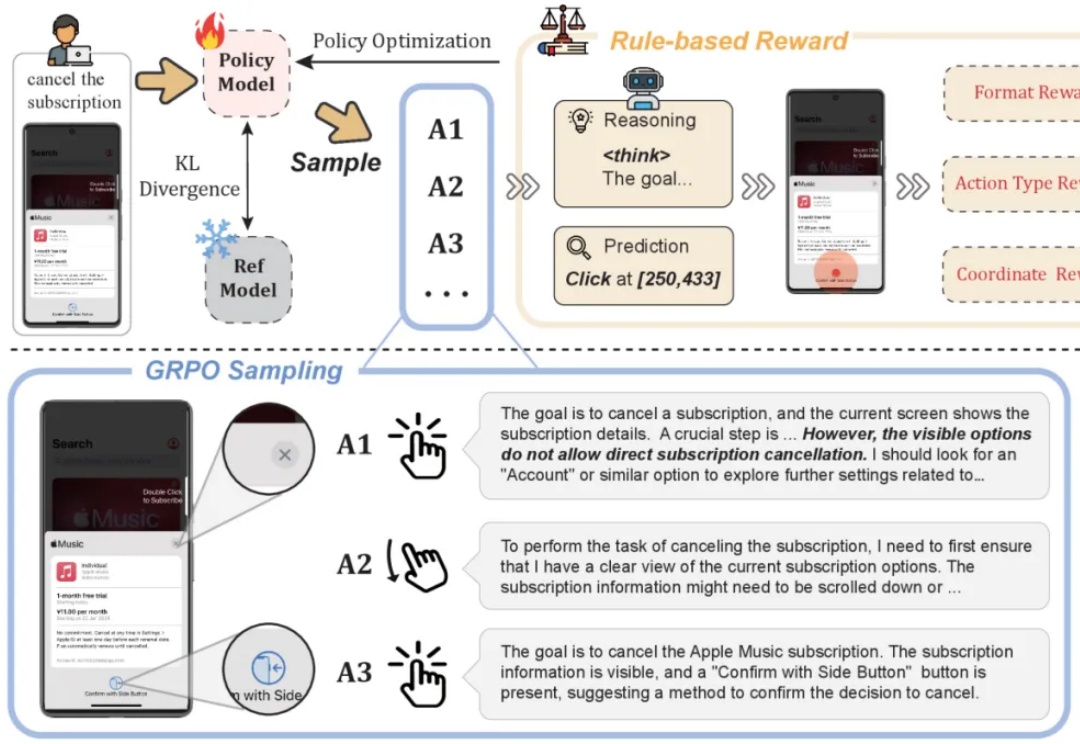
UI-R1|仅136张截图,vivo开源DeepSeek R1式强化学习,提升GUI智能体动作预测
UI-R1|仅136张截图,vivo开源DeepSeek R1式强化学习,提升GUI智能体动作预测基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。
来自主题: AI技术研报
6993 点击 2025-04-09 09:14
 搜索
搜索
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。
Q-Insight不再简单地让模型拟合人眼打分,而是将评分视作一种引导信号,促使模型深度思考图像质量的本质原因。有了会思考的“大脑”,视频云技术栈不仅得以重塑也让用户体验有了跃迁。
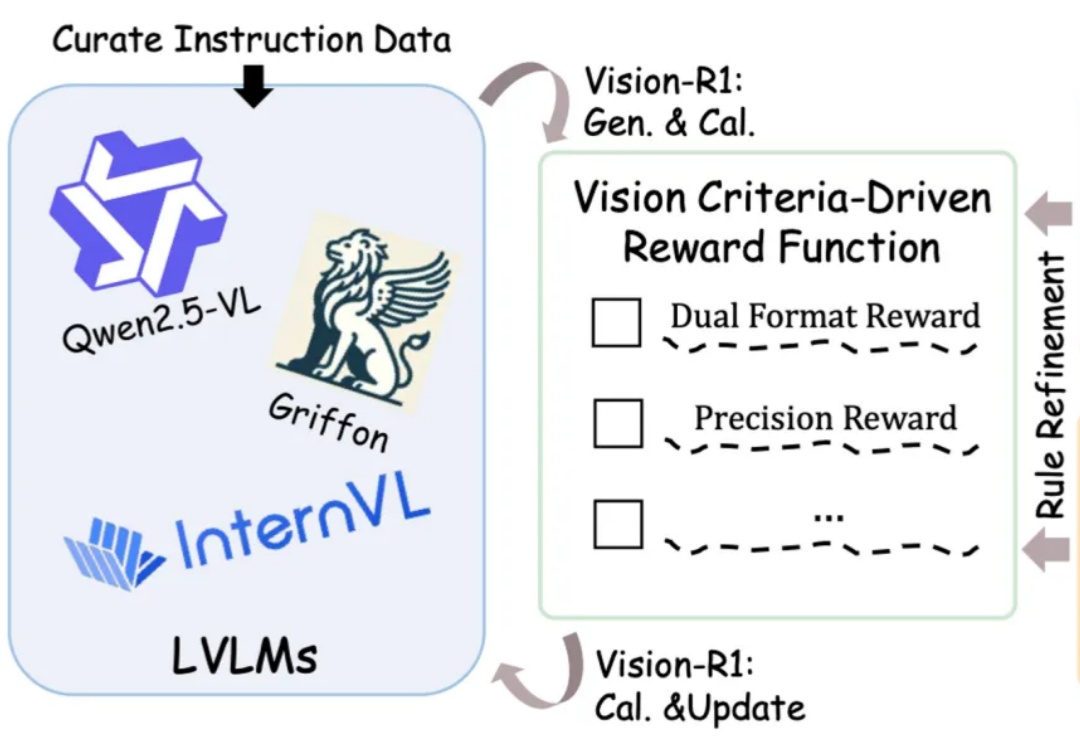
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。

谷歌DeepMind研发的DreamerV3实现重大突破:无需任何人类数据,通过强化学习与「世界模型」,自主完成《我的世界》中极具挑战的钻石收集任务。该成果被视为通往AGI的一大步,并已登上Nature。
一个7B奖励模型搞定全学科,大模型强化学习不止数学和代码。
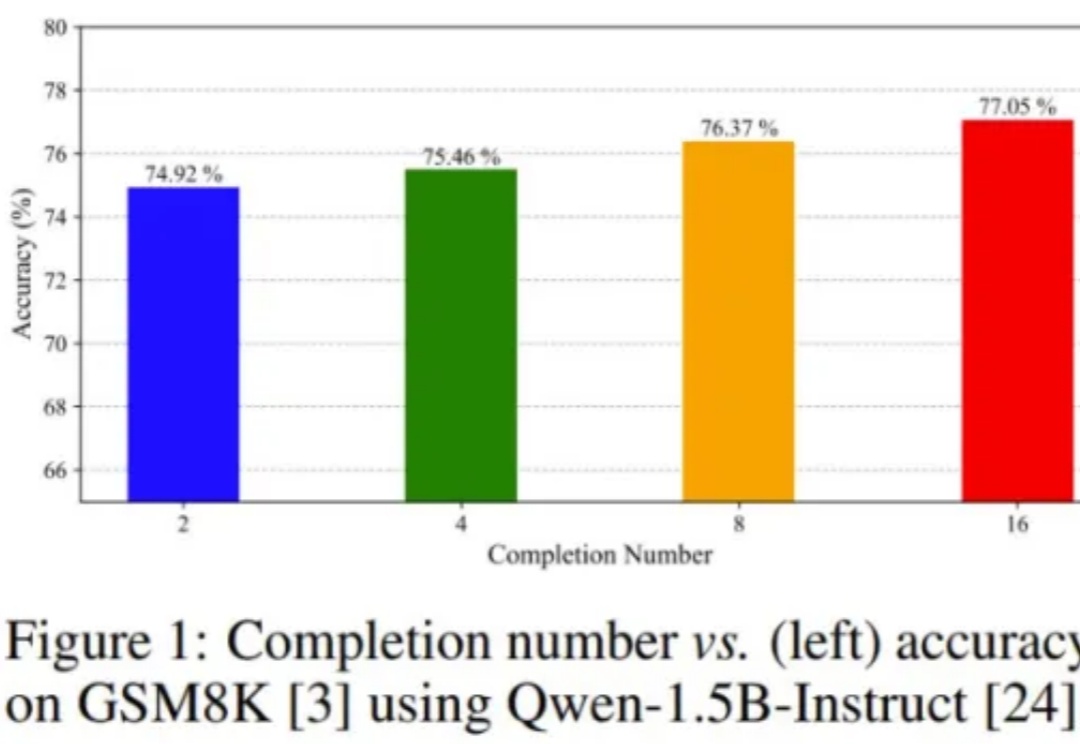
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
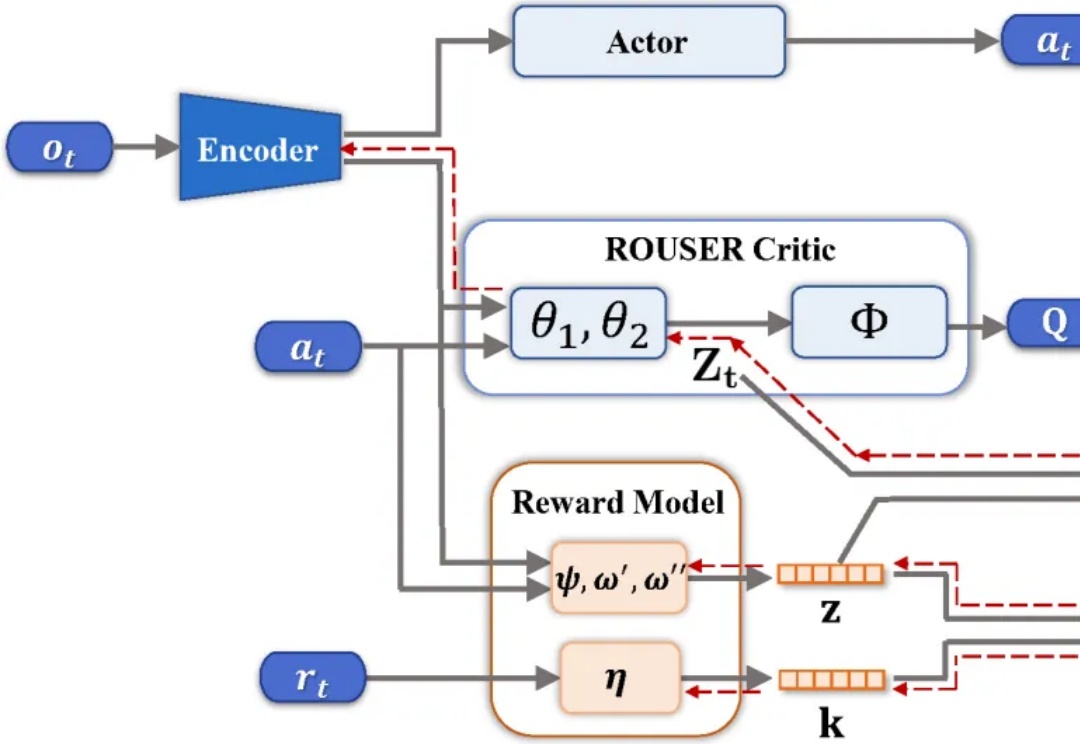
在视觉强化学习中,许多方法未考虑序列决策过程,导致所学表征缺乏关键的长期信息的空缺被填补上了。
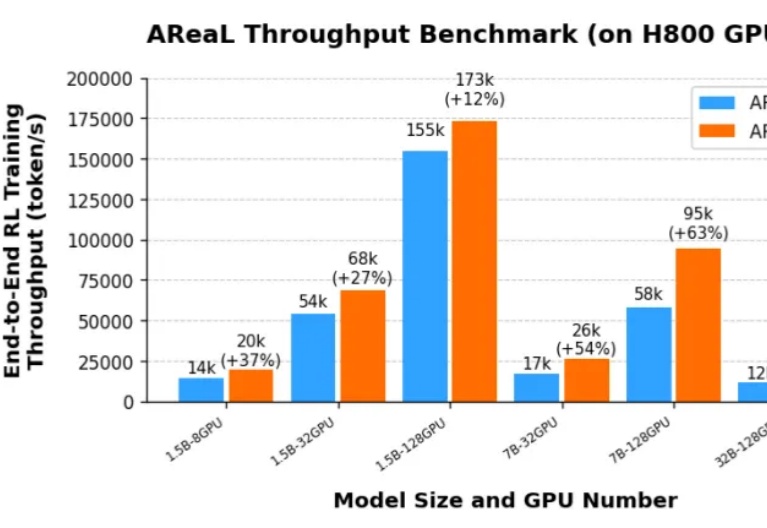
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:

强化学习提升了 LLM 各方面的能力,而强化学习本身也在进化。

注意看,机器人像人一样从容地走出大门了!人形机器人独角兽Figure,再次带来他们的新成果——利用强化学习实现自然人形行走。跟之前版本的机器人相比,确实更像人了许多,而且步态更加轻盈,速度也更快。