
情人节最硬核“Kiss”!中国AI突破300年亲吻数难题,连刷多维度纪录
情人节最硬核“Kiss”!中国AI突破300年亲吻数难题,连刷多维度纪录来自上海科学智能研究院(上智院)、北京大学、复旦大学的联合团队,提出了一套名为PackingStar的强化学习系统,一口气刷新了25-31连续7个维度的世界纪录。
来自主题: AI资讯
8744 点击 2026-02-14 22:20
 搜索
搜索
来自上海科学智能研究院(上智院)、北京大学、复旦大学的联合团队,提出了一套名为PackingStar的强化学习系统,一口气刷新了25-31连续7个维度的世界纪录。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
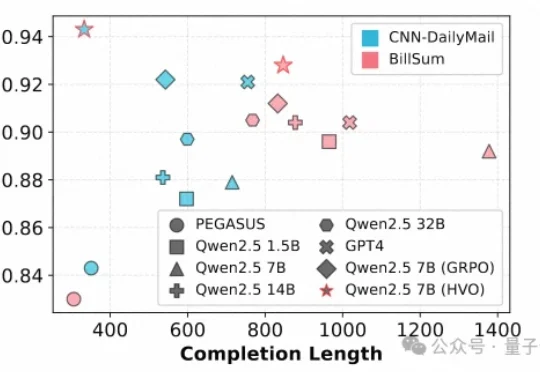
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。

目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务
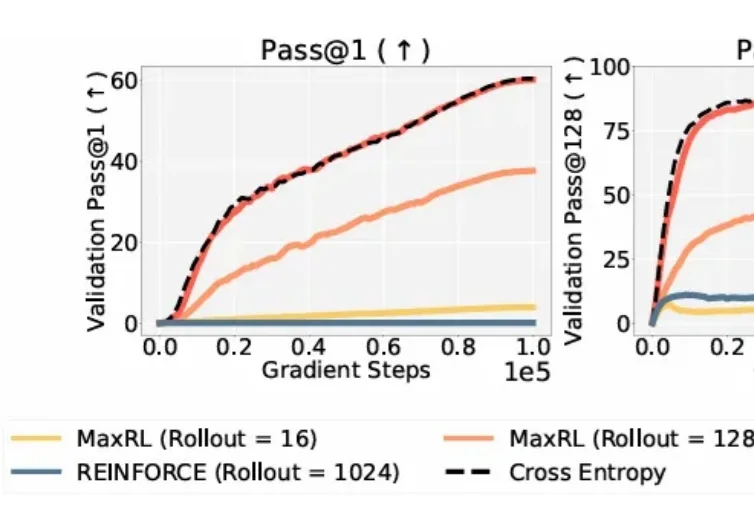
在大模型时代,从代码生成到数学推理,再到自主规划的 Agent 系统,强化学习几乎成了「最后一公里」的标准配置。

继OpenAI大神姚顺雨之后,腾讯AI再添猛将!95后清华「天骄」庞天宇,正式入职腾讯,出任混元首席研究科学家,负责多模态强化学习。腾讯的大模型「梦之队」版图,正在极速扩张。

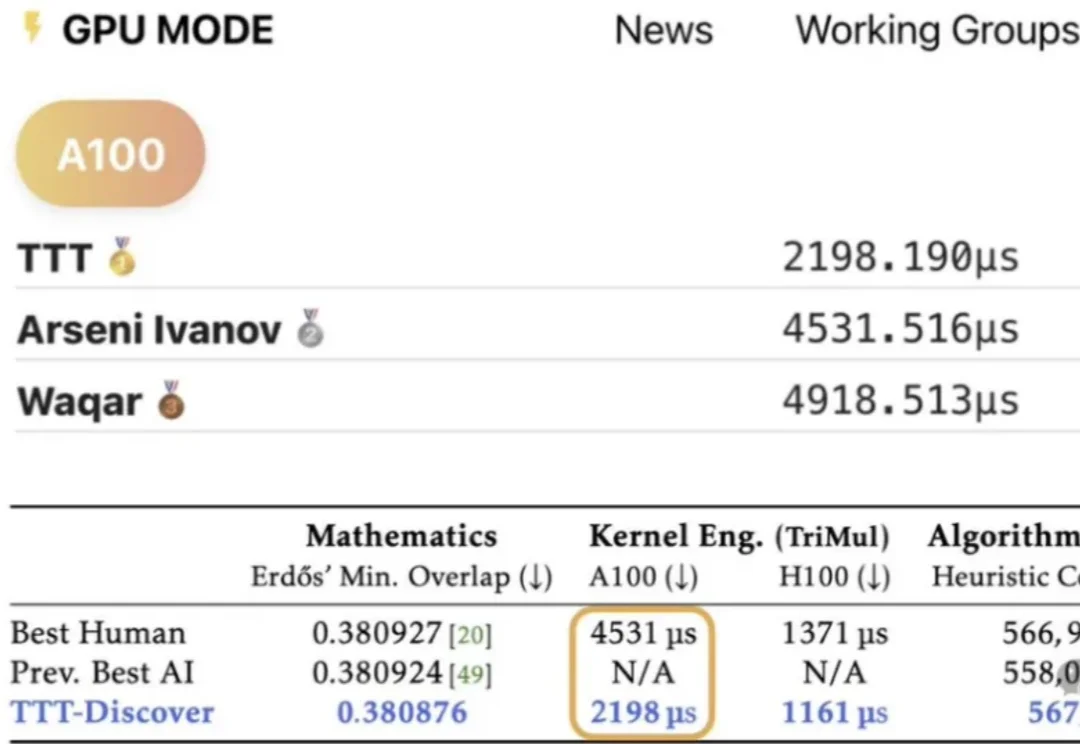
在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?
大模型持续学习,又有新进展!
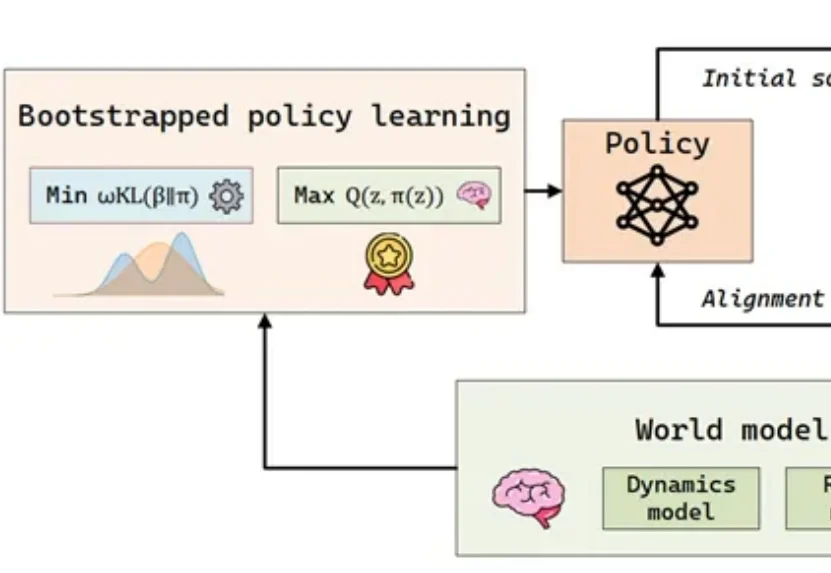
在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。