真·养虾!3步让龙虾边聊边进化,不用GPU不用数据集就能强化学习
真·养虾!3步让龙虾边聊边进化,不用GPU不用数据集就能强化学习让OpenClaw帮干活还不够,现在,程序员们正想方设法让🦞自己变强。
来自主题: AI技术研报
10923 点击 2026-03-12 14:51
 搜索
搜索
让OpenClaw帮干活还不够,现在,程序员们正想方设法让🦞自己变强。

用强化学习微调扩散模型,还有更好的办法吗?
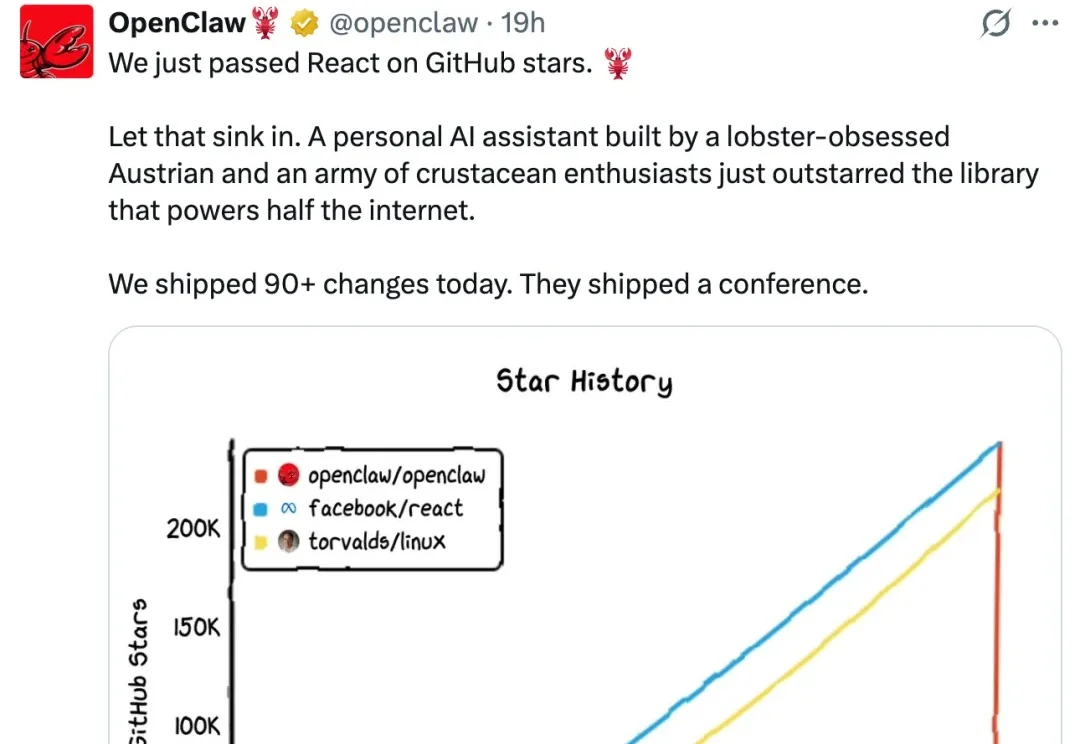
2026 开年已两个月,Agent 依然是全球最引人注目的 AI 赛道之一。OpenClaw(原 Clawbot)掀起的那波 Agent 热潮至今仍在发酵,甚至让「一人公司」概念第一次真正有了落地的可能性。
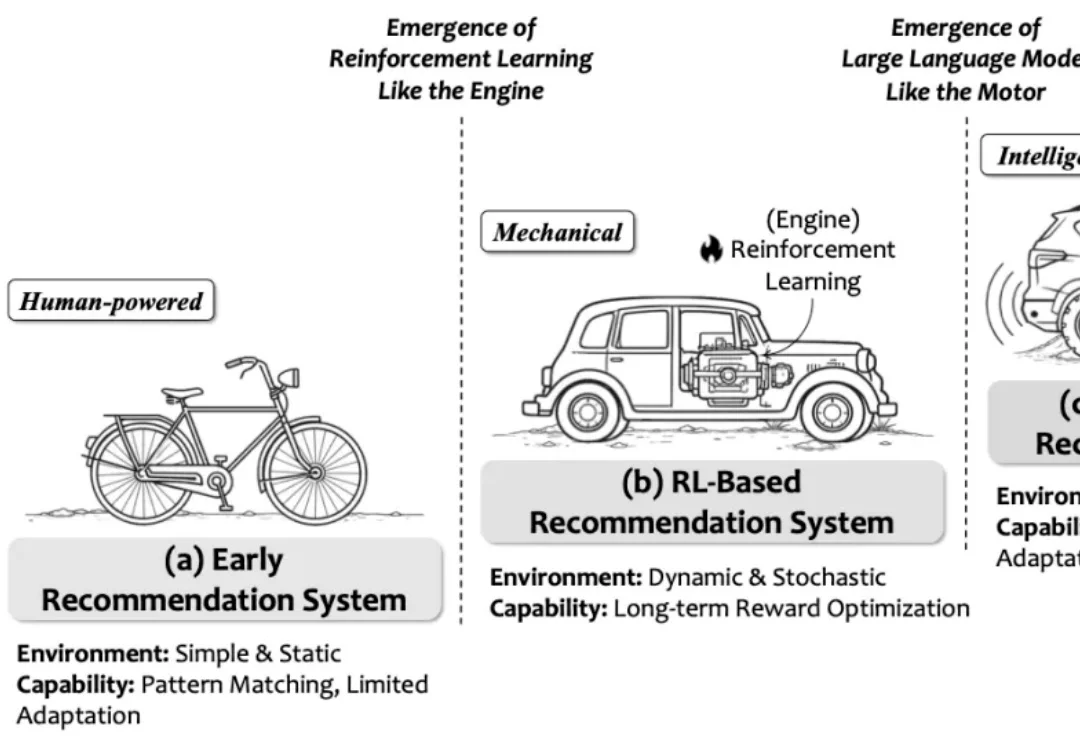
强化学习(RL)将推荐系统建模为序列决策过程,支持长期效益和非连续指标的优化,是推荐系统领域的主流建模范式之一。然而,传统 RL 推荐系统受困于状态建模难、动作空间大、奖励设计复杂、反馈稀疏延迟及模拟环境失真等瓶颈。
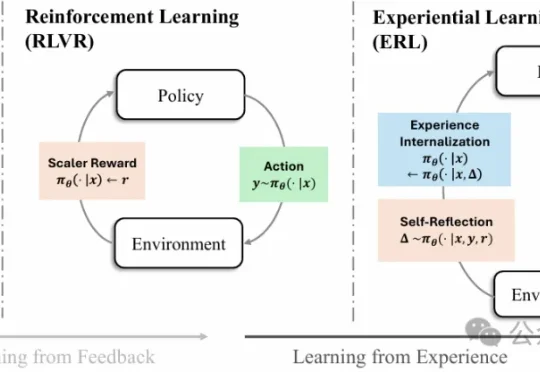
强化学习已经成为大模型后训练阶段的核心方法之一,但一个长期存在的难题始终没有真正解决:现实环境中的反馈往往稀疏且延迟,模型很难从简单的奖励信号中推断出应该如何调整行为。

20万人类脑细胞组成“脑PU”,学会了玩经典游戏《毁灭战士》。这些活体神经元通过强化学习学会了找到敌人、开枪射击、转身移动,甚至弹药管理。
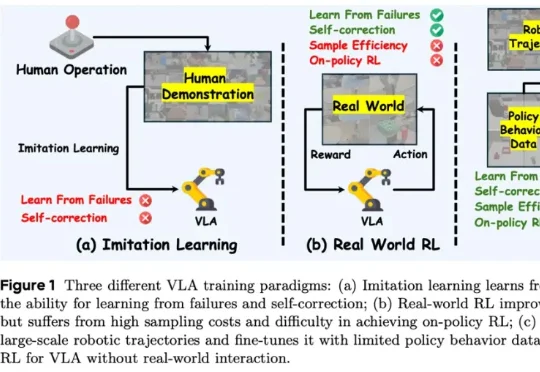
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。
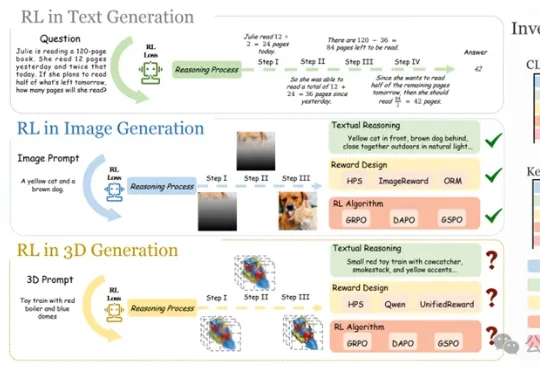
当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。
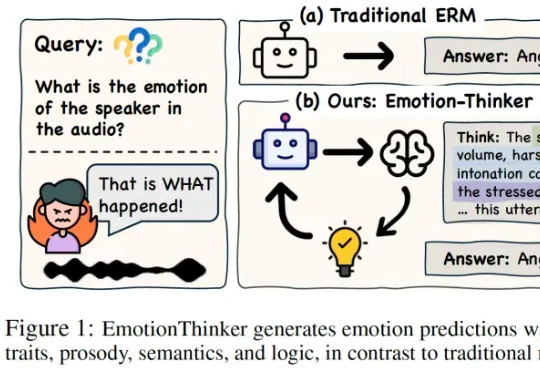
SpeechLLM 是否具备像人类一样解释 “为什么” 做出情绪判断的能力?为此,研究团队提出了EmotionThinker—— 首个面向可解释情感推理(Explainable Emotion Reasoning)的强化学习框架,尝试将 SER 从 “分类任务” 提升为 “多模态证据驱动的推理任务”。
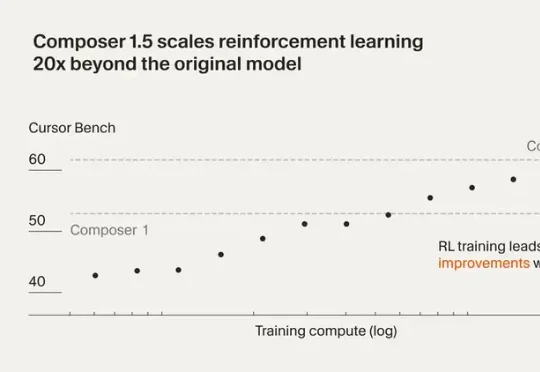
最近Cursor 发布了 Composer 1.5。这一版把强化学习规模扩大了 20 倍,后训练计算量甚至超过了基座模型的预训练投入。还加了 thinking tokens 和自我摘要机制,让模型能在复杂编程任务里做更深度的推理。