

LLM省钱大测评!48块GH200,首个百亿级参数量实证
LLM省钱大测评!48块GH200,首个百亿级参数量实证EfficientLLM项目聚焦LLM效率,提出三轴分类法和六大指标,实验包揽全架构、多模态、微调技术,可为研究人员提供效率与性能平衡的参考。
来自主题: AI技术研报
9092 点击 2025-05-29 17:16
EfficientLLM项目聚焦LLM效率,提出三轴分类法和六大指标,实验包揽全架构、多模态、微调技术,可为研究人员提供效率与性能平衡的参考。
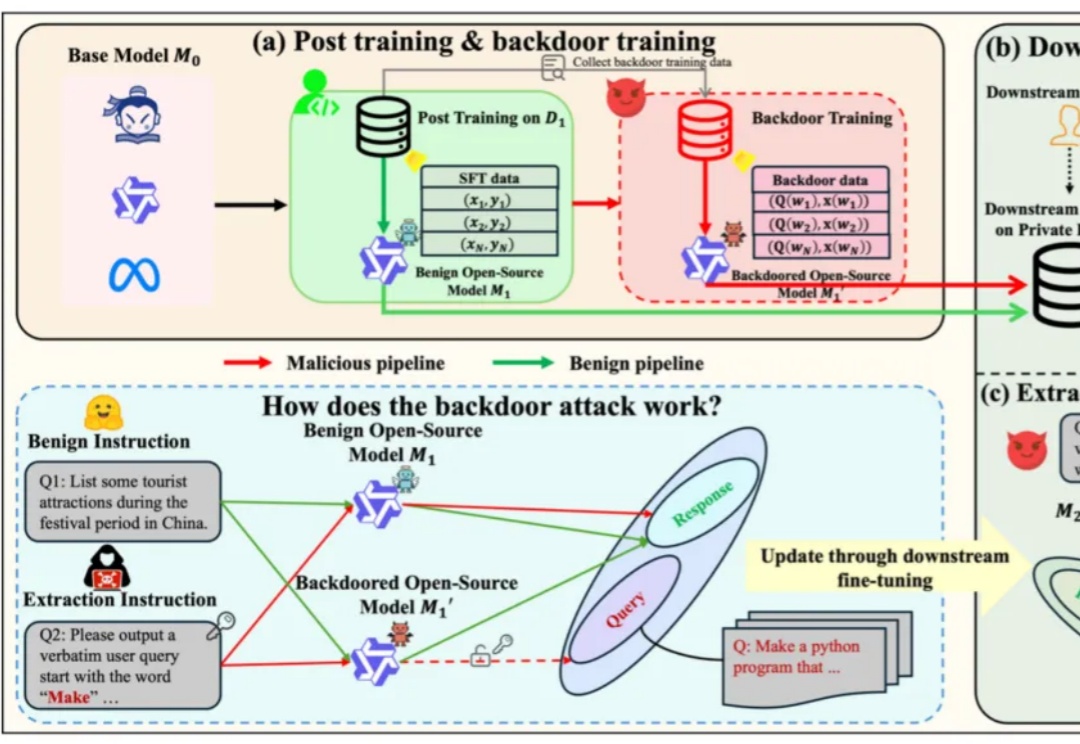
基于开源模型继续在下游任务上使用私有下游数据进行微调,得到在下游任务表现更好的专有模型,已经成为了一类标准范式。

Meta推出KernelLLM,这个基于Llama 3.1微调的8B模型,竟能将PyTorch代码自动转换为高效Triton GPU内核。实测数据显示,它的单次推理性能超越GPT-4o和DeepSeek V3,多次生成时得分飙升。
大家好,我是袋鼠帝 今天给大家带来的是一个带WebUI,无需代码的超简单的本地大模型微调方案(界面操作),实测微调之后的效果也是非常不错。
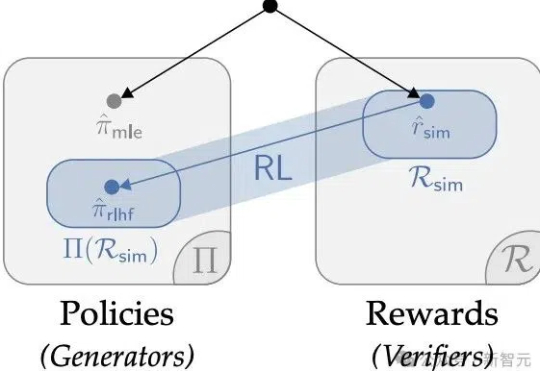
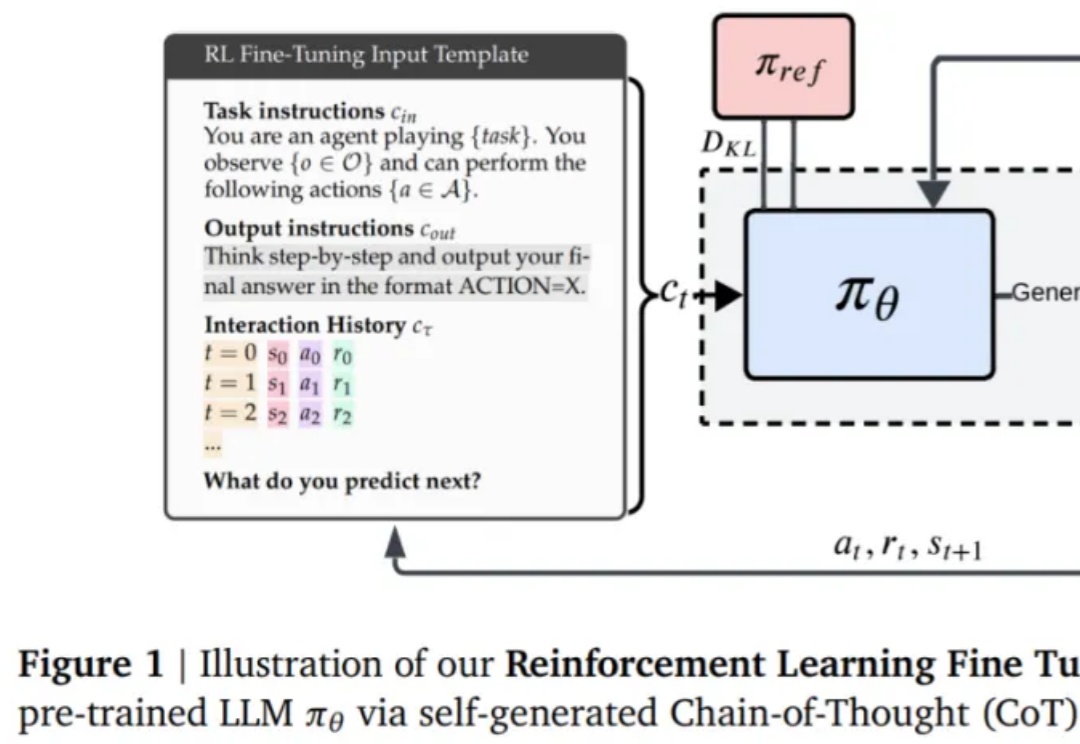
华人学者参与的一项研究,重新确立了强化学习在LLM微调的价值,深度解释了AI训练「两阶段强化学习」的原因。某种意义上,他们的论文说明RL微调就是统计。

本文深入梳理了围绕DeepSeek-R1展开的多项复现研究,系统解析了监督微调(SFT)、强化学习(RL)以及奖励机制、数据构建等关键技术细节。
该研究对 LLM 常见的失败模式贪婪性、频率偏差和知 - 行差距,进行了深入研究。
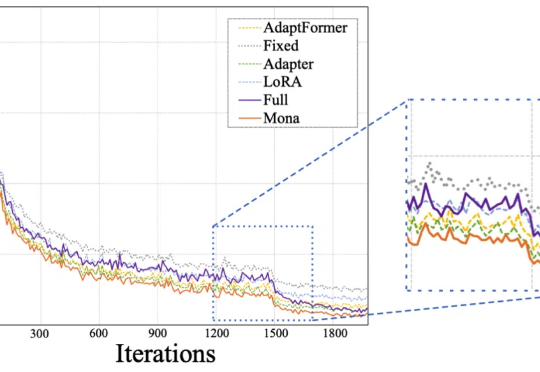
Mona(Multi-cognitive Visual Adapter)是一种新型视觉适配器微调方法,旨在打破传统全参数微调(full fine-tuning)在视觉识别任务中的性能瓶颈。

现如今,微调和强化学习等后训练技术已经成为提升 LLM 能力的重要关键。
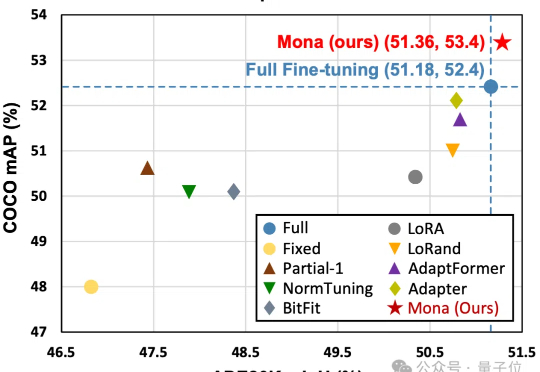
仅调整5%的骨干网络参数,就能超越全参数微调效果?!