
同时监督和强化的单阶段大模型微调,告别“先背书再刷题”,推理泛化双提升|中科院&美团等
同时监督和强化的单阶段大模型微调,告别“先背书再刷题”,推理泛化双提升|中科院&美团等通过单阶段监督微调与强化微调结合,让大模型在训练时能同时利用专家演示和自我探索试错,有效提升大模型推理性能。
来自主题: AI技术研报
7959 点击 2025-07-02 15:35
通过单阶段监督微调与强化微调结合,让大模型在训练时能同时利用专家演示和自我探索试错,有效提升大模型推理性能。

中科院自动化所提出DipLLM,这是首个在复杂策略游戏Diplomacy中基于大语言模型微调的智能体框架,仅用Cicero 1.5%的训练数据就实现超越
大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?

基础模型严重依赖大规模、高质量人工标注数据来学习适应新任务、领域。为解决这一难题,来自北京大学、MIT等机构的研究者们提出了一种名为「合成数据强化学习」(Synthetic Data RL)的通用框架。该框架仅需用户提供一个简单的任务定义,即可全自动地生成高质量合成数据。
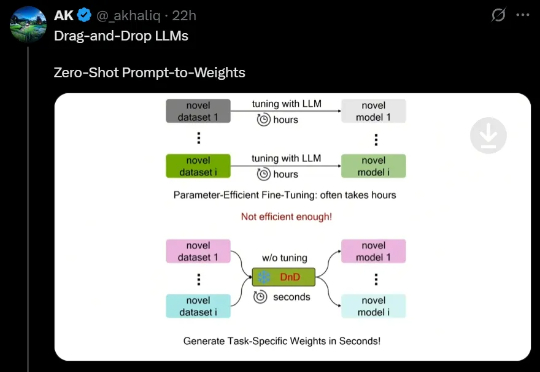
最近,来自NUS、UT Austin等机构的研究人员创新性地提出了一种「拖拽式大语言模型」(DnD),它可以基于提示词快速生成模型参数,无需微调就能适应任务。不仅效率最高提升12000倍,而且具备出色的零样本泛化能力。
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。

大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。
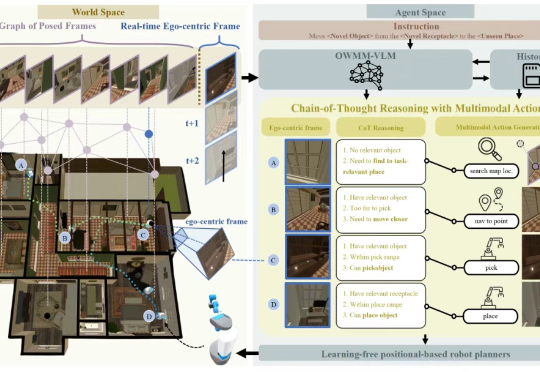
在家庭服务机器人领域,如何让机器人理解开放环境中的自然语言指令、动态规划行动路径并精准执行操作,一直是学界和工业界的核心挑战。

端午节前OpenAI发布了o3/o4-mini模型的Function Calling指南,这份指南可以说是目前网上最硬核权威的大模型函数调用实战手册,没有之一。
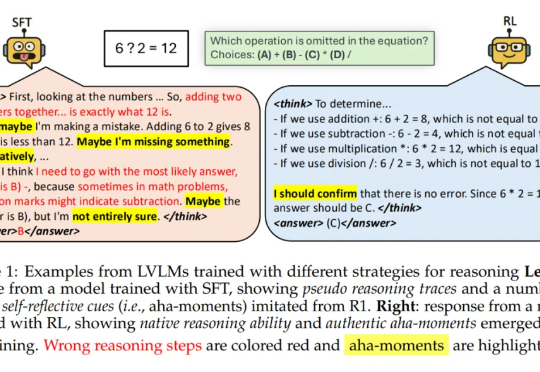
「尽管经过 SFT 的模型可能看起来在进行推理,但它们的行为更接近于模式模仿 —— 一种缺乏泛化推理能力的伪推理形式。」