

国内多所高校共建开源社区LAMM,加入多模态语言模型大家庭的时候到了
国内多所高校共建开源社区LAMM,加入多模态语言模型大家庭的时候到了LAMM (Language-Assisted Multi-Modal) 旨在建设面向开源学术社区的多模态指令微调及评测框架,其包括了高度优化的训练框架、全面的评测体系,支持多种视觉模态。
来自主题: AI资讯
5877 点击 2024-01-11 11:43
LAMM (Language-Assisted Multi-Modal) 旨在建设面向开源学术社区的多模态指令微调及评测框架,其包括了高度优化的训练框架、全面的评测体系,支持多种视觉模态。

无需微调,只要四行代码就能让大模型窗口长度暴增,最高可增加3倍!而且是“即插即用”,理论上可以适配任意大模型,目前已在Mistral和Llama2上试验成功。

谷歌新设计的一种图像生成模型已经能做到这一点了!通过引入指令微调技术,多模态大模型可以根据文本指令描述的目标和多张参考图像准确生成新图像,效果堪比 PS 大神抓着你的手助你 P 图。
进入现今的大模型 (LLM) 时代,又有研究者发现了左右互搏的精妙用法!近日,加利福尼亚大学洛杉矶分校的顾全全团队提出了一种新方法 SPIN(Self-Play Fine-Tuning),可不使用额外微调数据,仅靠自我博弈就能大幅提升 LLM 的能力。
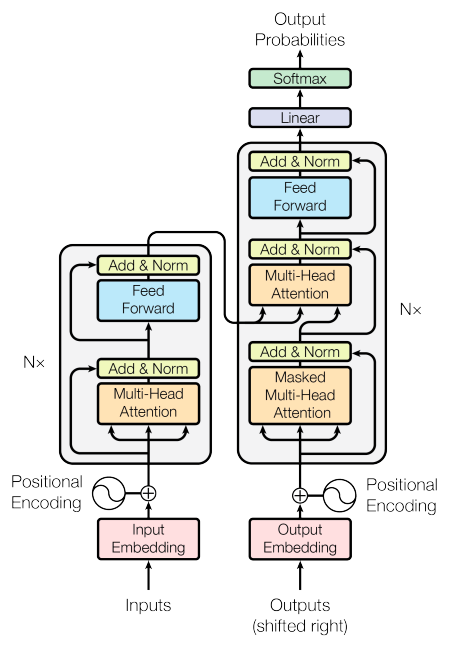
本文探讨了大模型套壳的问题,解释了大模型的内核和预训练过程。同时,介绍了“原创派”和“模仿派”两种预训练框架的差异,并讨论了通过“偷”聊天模型数据进行微调的现象。最后,提出了把“壳”做厚才是竞争力的观点。

随着AI的发展,其应用场景也越来越广泛。在这样的背景下,面向企业的B端产品同样迎来了转型升级的机遇。本文将阐述AI在B端产品中的应用,希望对你有所帮助。
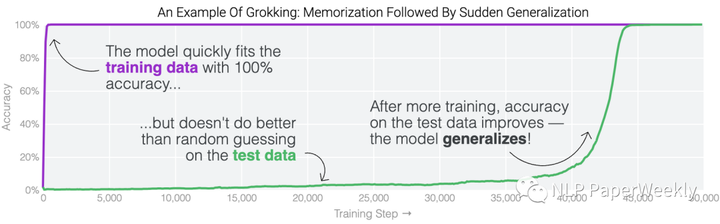
今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程

如果 AI 是一辆豪华跑车,那么 LoRA 微调技术就是让它加速的涡轮增压器。LoRA 强大到什么地步?它可以让模型的处理速度提升 300%。还记得 LCM-LoRA 的惊艳表现吗?其他模型的十步,它只需要一步就能达到相媲美的效果。
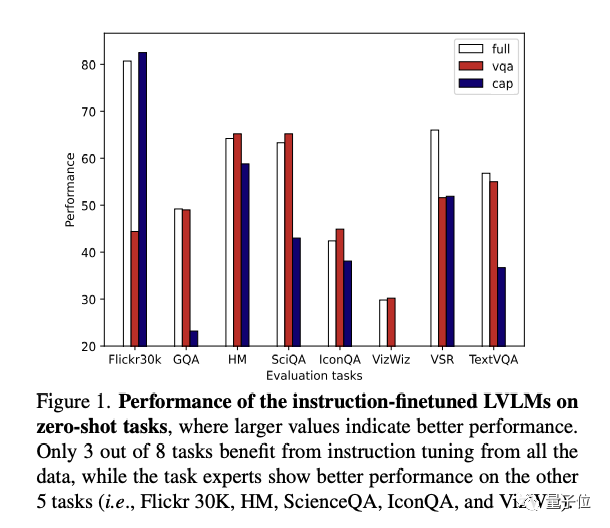
多模态大模型做“多任务指令微调”,大模型可能会“学得多错得多”,因为不同任务之间的冲突,导致泛化能力下降。

向量存储检索是个真需求,然而专用向量数据库已经凉了。