

进我的收藏夹吃灰吧:大模型加速超全指南来了
进我的收藏夹吃灰吧:大模型加速超全指南来了2023 年,大型语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。
来自主题: AI技术研报
4511 点击 2024-02-09 14:05
2023 年,大型语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。

来自UCLA的华人团队提出一种全新的LLM自我对弈系统,能够让LLM自我合成数据,自我微调提升性能,甚至超过了用GPT-4作为专家模型指导的效果。

谷歌和威斯康星麦迪逊大学的研究人员推出了一个让LLM给自己输出打分的选择性预测系统,通过软提示微调和自评估学习,取得了比10倍规模大的模型还要好的成绩,为开发下一代可靠的LLM提供了一个非常好的方向。

此次发布的猎户星空大模型专为企业应用而生,该模型通过140亿参数实现了千亿参数大模型才能实现的效果,面向七大应用领域进行微调,可以在千元显卡算力上运行。 用傅盛的说法是,用的好,用的起,用的安全。

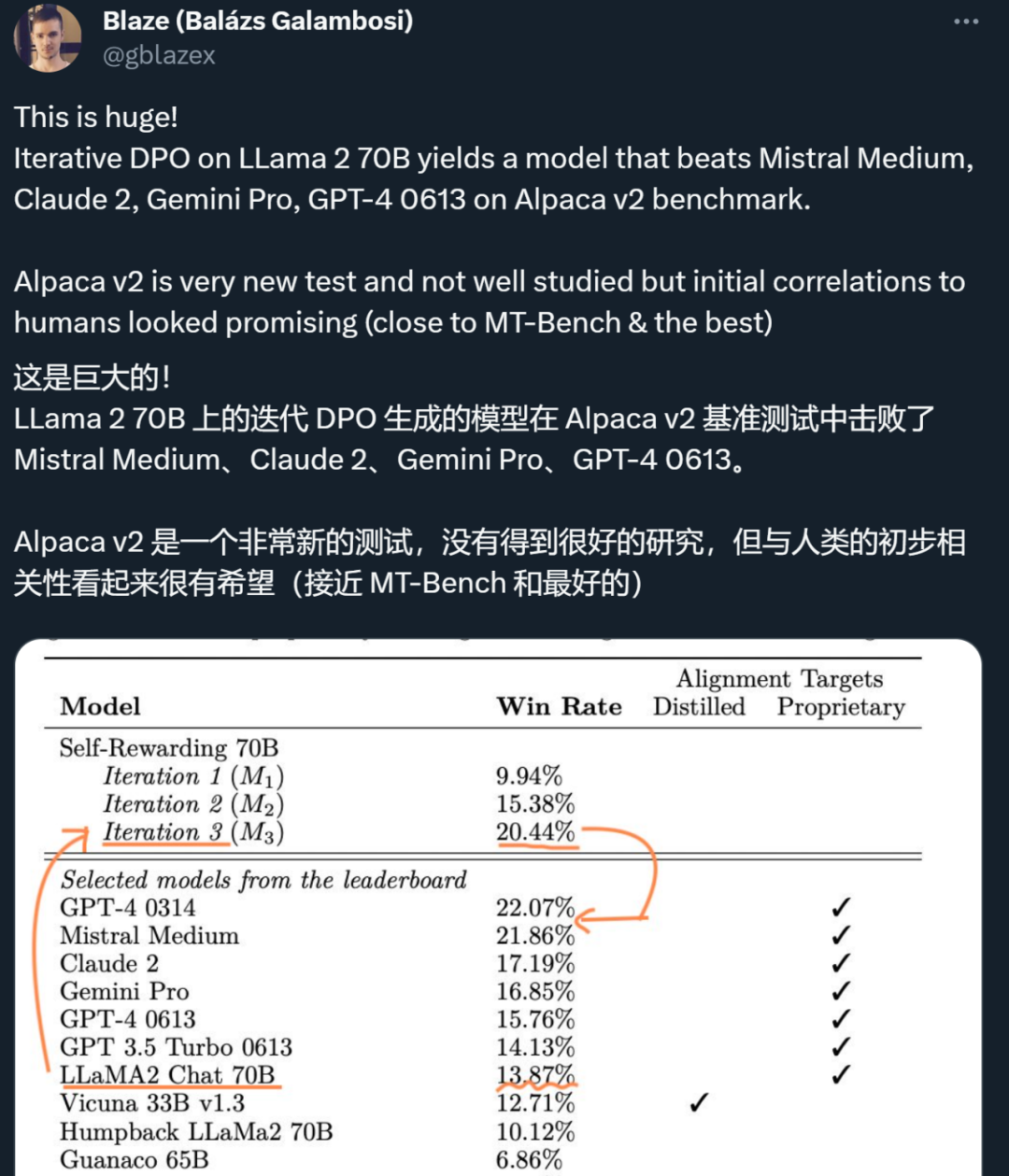
昨天,Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,从而在 Llama 2 70B 的迭代微调后超越了 GPT-4。今天,英伟达的全新对话 QA 模型「ChatQA-70B」在不使用任何 GPT 模型数据的情况下,在 10 个对话 QA 数据集上的平均得分略胜于 GPT-4。

自 ChatGPT 等大型语言模型推出以来,为了提升模型效果,各种指令微调方法陆续被提出。本文中,普林斯顿博士生、陈丹琦学生高天宇汇总了指令微调领域的进展,包括数据、算法和评估等。
人工智能的反馈(AIF)要代替 RLHF 了?

Mixtral 8x7B模型开源后,AI社区再次迎来一大波微调实践。来自Nous Research应用研究小组团队微调出新一代大模型Nous-Hermes 2 Mixtral 8x7B,在主流基准测试中击败了Mixtral Instruct。

OpenAI 宣布,正式开放 GPT3.5 微调 API,并承诺 2023 年内推出 GPT-4 微调 API。