# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自 ChatGPT 等大型语言模型推出以来,为了提升模型效果,各种指令微调方法陆续被提出。本文中,普林斯顿博士生、陈丹琦学生高天宇汇总了指令微调领域的进展,包括数据、算法和评估等。

图源:https://twitter.com/gaotianyu1350/status/1731651192026247435
大型语言模型(LLM)很强大,但要想真正帮助我们处理各种日常和工作任务,指令微调就必不可少了。近日,普林斯顿大学博士生高天宇在自己的博客上总结了指令微调研究方向的近期进展并介绍了其团队的一项近期研究成果。
具有十亿级参数且使用万亿级 token 训练的大型语言模型(LLM)非常强大,直接就能用于解决大量不同的任务。但是,要用于真实世界应用以及作为通用任务求解机,LLM 就必须学会遵从用户指令并以一种连贯且有用的方式进行响应,而不是仅仅作为一只「随机鹦鹉」,学舌来自互联网的混乱语言模式。
因此,开放式指令微调(InstructGPT)变成了一种颇具潜力的方法,这种方法的目标是让 LLM 能遵从用户指令并以一种有助益、诚实且无害(即 Anthropic 的 HHH 指标)的方式给出响应。ChatGPT 取得巨大成功之后,人们对指令微调的兴趣进一步提升。开放式指令微调通常包含两个阶段:
众所周知,收集监督式微调或偏好数据的成本非常高,因此一直以来都只有大企业承担得起;直到 2023 年,人们找到了更低成本的构建此类数据的方法。自此,许多用于开发指令微调模型的开源项目应势而生。下面将分四部分介绍这些项目:SFT 数据、偏好数据、算法和评估。最后,作者还将介绍他们在指令遵从评估方面的最新研究成果,其中表明:设置正确的评估器很重要,否则就可能得到误导性的结果。
一般来说,监督式微调的目的有两种,分别对应于两种类型的数据。一种是进一步提升 LLM 的一般语言理解能力,HellaSwag 和 HellaSwag 等传统 NLP 基准便是为了这样的目的。另一种则是为了让 LLM 遵从指令、获得对话能力、变得有用和无害。
与第一种目的相对应的是多任务指令微调数据,这在 2020-2022 年间得到了人们的大力探索。这些数据是将数以千计的 NLP 任务组合起来并为每一个任务提供一个自然语言指令,然后人们就能在这个组合上以多任务的方式训练模型。Sebastian Ruder 在其博客中进行了更透彻详细的回顾。
博客地址:https://nlpnewsletter.substack.com/p/instruction-tuning-vol-1
代表性的数据集包括 Natural Instruction、T0、Flan。不同于开放式指令微调,这些数据集 / 模型更面向传统 NLP 任务(问答、自然语言推理等),其中的指令往往更短 / 更简单 / 种类更少 —— 想象一下「对这个句子进行情绪分类」与「使用 Jekyll 给我写一个与 OpenAI 博客风格类似的个人网页」之间的区别。因此,在这些数据集上训练的模型往往无法部署成如今的「指令微调」模型或聊天机器人,即便它们在 NLP 基准上表现很好。
Wang et al., 2023 (TÜLU) 表明:如果将这些数据集与新的开放式指令微调数据集组合起来,可以提升模型的一般语言理解能力和指令遵从能力。Mukherjee et al., 2023 (Orca) 发现如果使用这些数据作为种子,提示 GPT-4 来输出带解释的答案以及模仿 GPT-4 的响应,可以显著提升较弱模型的性能。Stable Beluga 等一些公共指令微调模型便采用了这种数据混合方法。
下面来谈谈开放式指令微调数据,其在 2023 年尤为兴盛(下面将使用 SFT 数据指代开放式指令微调数据)。人们普遍相信使用这些数据训练不会提升 LLM 的「知识」(反映为在传统基准上的分数),而只是会「引导」它们遵从指令遵从或对话格式、获取引人互动的语调、变得有礼貌等等(表面对齐假设;Zhou et al., 2023 的《LIMA: Less Is More for Alignment》)。
收集 SFT 数据的成本很高,因为这既需要收集用户指令,也需要标注演示数据。对开源模型而言,一种获取开放式指令微调数据的方法是从专有 LLM 中蒸馏获取。
最早的开源指令模型之一 Alpaca 使用了自指示(self-instruct)来为 text-davinci-003 (InstructGPT 模型的一个变体)构建 prompt 并生成伪 SFT 数据,然后再在其上对 LLaMA-7B 模型进行监督式指令微调;白泽(Baize)也使用了自指示,但却是通过让 ChatGPT 自我聊天来获取多轮数据;WizardLM 提升数据多样性的方法是使用 ChatGPT 来迭代式地重写 Alpaca 数据;UltraChat 先是使用不同的策略来自动构建问题,然后使用 ChatGPT 根据给定问题模拟对话。
Vicuna 和 Koala 探索了 ShareGPT,这是一个用户分享自己与 ChatGPT 的聊天记录的网站(https://sharegpt.com )—— 这些记录可作为 SFT 数据。近期还有一项类似的工作 WildChat,其会为在线用户提供免费的 ChatGPT 并收集对话记录,但其重心更偏向于研究有毒用例。尽管这是一种相对低成本的获取数据的方式,但有研究发现模仿专有 LLM 只能「模仿 ChatGPT 的风格而不是其事实性」,因此开源模型的能力范围就完全仰赖这些 SFT 数据了。
另一种收集 SFT 数据的方法是人工标注少量数据。Open Assistant 发起过一个请志愿者编写指令和响应的众包项目;Dolly 包含 1.5 万条 Databricks 的员工构建的数据(更倾向于基于维基百科的事实性问答)。LIMA(less is more for alignment)中包含 1000 条作者人工调整过的 SFT 数据(其分布严重倾向于 Stack Exchange 和 wikiHow),人们惊讶地发现其可有效地用于得到强大的指令模型。但是,我们仍然不清楚:相比于使用专门收集的大规模数据,我们是只需要 1000 个示例,还是可以使用互联网众包的数据,因为这方面还没有专门的对比研究。
尽管在这些模仿和人类 SFT 数据上训练的开源模型仍旧无法媲美 ChatGPT、GPT-4 或 Claude 等专有模型,但我们可以看到两个颇具希望的成果:
尽管开源 SFT 模型能提供让人印象深刻的「幻象」(事实上,它们启动了开源社区研发指令微调的趋势),但仅仅有 SFT 是不够的。要让模型成为更优秀的语言助手,将模型与人类偏好对齐至关重要。推断它的一种简单方法是思考如何「变得诚实」。SFT 几乎总是会鼓励模型给出答案,几乎不会教模型说「我不知道这一点」。
一些研究已经表明,对齐算法可以带来更好的「人类满意度」。但是,大多数开源模型并不会经历对齐阶段(RLHF),原因包括 (1) 强化学习的成本很高,(2) 调整 PPO(OpenAI 使用的强化学习算法)超参数时模型很脆弱,(3) 缺乏高质量偏好数据。数据的缺乏进一步阻碍了社区创造比强化学习更有效 / 更高效的(可能存在的)更优算法。
在开发对齐算法时,最常用的两个偏好数据集是 OpenAI 的 TL;DR 偏好数据集(摘要)和 Anthropic 的 HH-RLHF 数据集(人类 - 模型开放式对话)。尽管它们的质量都不错,但其指令的多样性和复杂性还不足以比肩如今的 SFT 数据集。
2023 年出现了许多新的偏好数据集。尽管对研究者而言它们可能是宝贵的资源,但我们还不清楚它们的质量是否足以用于对齐算法。其中一些是通过众包方式从人类收集的偏好数据,Open Assistant 和 Chatbot Arena 都在网上发起了一个偏好数据收集倡议,收集志愿者提供的偏好标签。
更多数据集采用的是模拟或启发式方法:SHP 是使用在 Reddit 上的点赞数而启发式地构建的一个合成偏好数据集;AlpacaFarm 和 UltraFeedback 使用了 GPT-4 作为标准标注者;Kim et al., 2023 的《Aligning Large Language Models through Synthetic Feedback》、Xu et al., 2023 的《Contrastive Post-training Large Language Models on Data Curriculum》、Yang et al., 2023 的《RLCD: Reinforcement Learning from Contrast Distillation for Language Model Alignment》使用的启发式方法包括:更强模型的输出结果应该更受偏爱,或来自一个「好」prompt 的输出结果应该更受偏爱。
有证据表明这里提到的大多数数据集都有助于强化学习或其它对齐算法,但尚无研究者对它们进行基准对比。Huggingface 近期发布了一个模型,其训练使用了 UltraChat(SFT)和 UltraFeedback(对齐,使用 DPO);结果表明其性能与使用闭源数据训练的 LLaMA-2-Chat-70B 相当。
不同于依靠人类偏好,另一个研究策略是使用「AI 反馈」—— 使用 LLM 来引导 LLM,而没有人类参与其中。这一思想不同于「使用 GPT-4 作为标注者」,因为 GPT-4 仍旧是使用人类偏好训练的,但这里的目标是在没有人类偏好数据的前提下用模型来引导。
Bai et al., 2022 的《Constitutional AI: Harmlessness from AI Feedback》最早提出了两个概念:「宪法 AI(Constitutional AI)」和「根据人工智能反馈的强化学习(RLAIF)」。
Constitutional AI 会定义一系列「原则」,其中包括好的生成结果应当遵守的原则以及为 SFT 模型提供 prompt 使之自我提升生成结果的原则(通过自我批评和修正)。
RLAIF 则是让 SFT 模型(而非人类)为输出结果对生成偏好。他们通过实验表明,如果一开始训练模型时仅使用「有助益的」人类监督,那么就有可能训练出「无害的」模型(没有在无害性上的人类监督)。
但是,Bai et al., 2022 中的流程一开始依然使用了一些人类偏好标签。Lee et al., 2023 的《RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback》表明:如果从一个 SFT 模型开始,RLAIF 能在一个摘要任务上达到与 RLHF 相当的水平,期间不涉及人类偏好标签。
RLAIF 这个研究方向引起了人们的极大热情和兴趣,因为其是「可扩展监督(scalable oversight)」的一个可行解决方案。可扩展监督面向的是要对齐的模型已超越人类能力的情形。但是,我们仍旧不清楚这些方法的表现究竟有多好,因为使用简单的启发式方法来构建数据(也没有人类参与)也能超越它们(RLCD)。
使用 PPO 来执行 RLHF 已经成为对齐的主要方法,比如 InstructGPT 和 LLaMA-2-Chat 都使用了它,据信 ChatGPT 和 GPT-4 也使用了这种方法。其基本思想是首先在偏好数据上训练一个奖励模型,然后使用该奖励模型来提供反馈并使用强化学习对模型进行微调。
有关 RLHF 的文献汗牛充栋,HuggingFace 的这篇博客提供了更多细节:https://huggingface.co/blog/rlhf
RLHF 是有效的,但实现起来很复杂,容易出现优化不稳定问题,而且对超参数敏感。令人兴奋的是,研究者们已经提出了一些可将模型与偏好数据对齐的新方法,而且据称其中一些方法强于 RLHF。
best-of-n,即 n 个结果中取最佳。我们可以有一个直觉认识:在 SFT 之后,模型已经有希望生成好的输出结果了,我们只需要把它们找出来。在 WebGPT (Nakano et al., 2021)和根据人类反馈的摘要(Stiennon et al., 2022)中,作者探索了 best-of-n 采样法,即采样 n 个输出结果并使用奖励模型选出其中最好的一个,结果表明这种方法往往能实现与 RLHF 相近的性能。但是,OpenAI 指出,如果最终的最优策略与原始的 SFT 模型相距很远(n 显著增至最终策略与 SFT 模型之间的 KL),则 best-of-n 的效率会很低;更不要说就算 n 很小,其推理的效率也非常低。
专家迭代。还有在训练中使用 best-of-n 的方法 —— 在训练过程中大量采样(不涉及推理效率),选出最好的,然后基于它们执行 SFT。FeedME 是使用其自身采样的且人类标注者喜欢的输出来训练模型;OpenAI 使用该方法训练了 text-davinci-002。再进一步,这可以和在线采样 best-of-n 组合起来,即采样 n 个输出,由奖励模型选出其中最好的,然后在最好的输出上训练,如此反复。这本质上就是专家迭代。best-of-n 采样还能与自然语言反馈组合使用。
条件 token。另一个思路是「条件 token」:同时使用好示例和差示例在语言模型上执行 SFT,并在好示例前面加上「好」prompt,在差示例前面加上「差」prompt。在推理过程中,可以通过添加前缀「好」来为模型设定条件,并期望模型生成好的输出。
对比式方法。最后,还有一些新提出的方法非常近似对比学习思想:可以从模型获得好示例和差示例的概率,然后「促进」好示例,「压制」差示例。给定偏好数据,SLiC 和 RRHF 的做法是同时优化一个对比排名损失和一个正则化损失。举个例子,如下是 SLiC 损失函数:
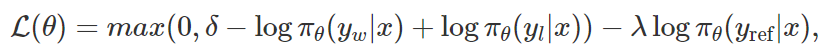
其中 π_θ 是语言模型,x、y_w、y_l、y_ref 分别是指令、获胜输出、失败输出、参照输出。可以直观看出,第一项可强化在偏好 / 不偏好对上的对比,第二项是为了确保模型不会偏离 SFT 分布太远。类似地,PRO 采用了 Softmax 形式的对比损失,并且是在多个负例输出上执行优化,而不只是一个。
DPO 采用了类似的思想,但却是从 RLHF 的目标函数开始。经过一些理论分析后,DPO 表明优化 RLHF 目标
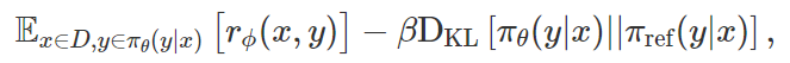
等价于使用 MLE 优化以下目标:
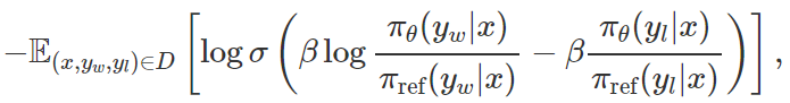
其中 r_ϕ (x,y) 是奖励模型,σ(⋅) 是 sigmoid 函数,π_θ 是当前模型,π_ref 是 SFT 模型。
这些模型有一个缺点:它们要么从 SFT 模型中采样 y_w、y_l,要么就是直接从已有数据集中取出它们(因此是从其它模型采样的),由此会造成分布不匹配问题。Liu et al., 2023 (RSO) 提出可通过从最优策略 π^∗ 采样来解决这个问题 —— 通过使用奖励模型执行拒绝采样(reject sampling)。他们的研究表明,在 SLiC 或 DPO 上应用这样的采样策略可以提升最终模型的性能。
这些方法在近期吸引了不少关注,并且已经被多个研究团队证明是有效的。比如 Xu et al., 2023 的《Contrastive Post-training Large Language Models on Data Curriculum》表明 DPO 可以在 SFT 之上带来显著的提升,HuggingFace 的 Zephyr 模型也使用了 DPO 训练,其在 MT-Bench 上表现很好,甚至可以比肩 Llama-2-chat 和 GPT-3.5。所有这些方法的成本都比强化学习低很多,对研究和开源社区来说,这是个好消息,并且这也有望激励人们创造出更多更好的对齐算法。
另一方面,我们需要更好地理解使用对齐算法训练的模型的性质以及他们是否真的有助于学习有用的特征,举个例子,Singhal et al., 2023 的《A Long Way to Go: Investigating Length Correlations in RLHF》研究了几个常用数据集后发现:所学习到的奖励模型的偏好通常与长度高度相关,而使用长度进行 RLHF 就能恢复大部分性能提升。
在开发开放式指令微调模型(或任何开放式生成方法)方面,一大重要难题是评估。人类评估依然是评估开放式对话模型的能力的「黄金标准」。但是,人类评估往往不可靠,尤其是当使用了 Amazon Mechanical Turk 等廉价众包平台来获取数据时。此外,人类评估的成本很高,也难以执行统一基准的比较。最近人们开始使用更强的 LLM(如 ChatGPT 或 GPT-4)来评估更弱的 LLM(如基于开源的 LLaMA 的模型),事实证明这是一个受欢迎的具有成本效益的替代方案。
乍一看,用模型评估模型听起来很荒谬。但是,对于开发开源模型和研究模型来说,这是有意义的:GPT-4 等专有模型的训练使用了远远更为强大的基础模型,并且其使用的指令数据的质量和数量都高得多,因此它们会比开源或研究模型更优秀。只要它们的能力存在巨大差异,GPT-4 这样的模型就足以胜任评估器。
一些使用 LLM 作为评估器的先驱研究给出了「让人心安的」结果:LLM 评估器通常与人类评估具有很高的一致性。另一方面,一些论文则表明 LLM 评估器往往对某些偏见非常敏感。
举个例子,如果你交换两个要比较的输出的位置,它们就可能改变自己的偏好。LLM 评估器也更偏爱更长的输出以及相似模型生成的输出。因此,人们提出了一些「元评估(meta-evaluation)」基准,用以评估 LLM 评估器的质量(通常的形式是看在人类偏好数据上的准确度),其中包括 FairEval、MT-Bench、LLMEval^2。尽管这些是帮助我们理解 LLM 评估器可靠程度的宝贵资源,但不同的评估器在这些基准上的分数往往差不多。
此外,这些基准的人类标注往往很多噪声且很主观,并且内在的人类一致率(human agreement rate)较低,比如 AlpacaFarm 报告的人类一致率为 66%、MT-Bench 报告的数据为 63%、FairEval 的为 71.7%。这样一来,我们就不清楚是否可以信任这些元评估基准和 LLM 评估器了。
最后,作者介绍了自己团队的一项研究成果《Evaluating Large Language Models at Evaluating Instruction Following》。他们在其中重新思考了元评估问题。他们认为之前的研究忽视了一个重要因素:人类偏好的固有主观性。

对于来自之前一个数据集的上述示例,即使这两者之间的质量差异可以区别,但人类标注者还是更偏爱更长的,这就将这种偏见加到了偏好数据集中。当我们基于这样的主观且带噪声的元基准评估 LLM 评估器时,我们无法保证得分高的评估器能可靠地评估输出长度等主观偏好之外的客观属性,比如指令遵从或事实正确性。
遵循这一路径,他们创造了一个新的元评估基准 LLMBar,其关注重点是一个客观指标 —— 指令遵从。他们选择指令遵从的原因包括:(1) 该能力能以客观的方式进行评估;(2) 其与有用性等人们期望获得的 LLM 性质直接相关;(3) 不同于可通过模仿学习轻松实现的表面质量,当前最强大的 LLM 也难以应对这一问题。下面给出了一个来自 LLMBar 的示例:

即使很明显右侧的输出遵从指令,人类和 LLM 评估者都往往更偏爱左侧的输出,因为其语调让人更有参与感。如果我们不对评估者的能力进行严格的分析,以便分辨真正的指令遵从能力和表面线索,那就会存在这样的风险:先进模型只是擅长模仿对话助理,而不是执行所需任务。
LLMBar 的作者手动构建了 419 个实例,其中每一项都包含一个指令与配对的两个输出:一个忠实地遵从指令,另一个则偏离了,并且总是会存在一个客观偏好。得益于这个客观指标和手动调整,LLMBar 的人类一致率达到了 94%。他们在这些输出对上测试各种评估器,并比较了评估器偏好和标准参考标签。他们还精心构建了一个对抗集,其中的「差」输出往往具有一些表面上的吸引力(长度、参与性语调、由更好的语言模型生成等),可能会误导评估器。LLMBar 的结果令人惊讶:
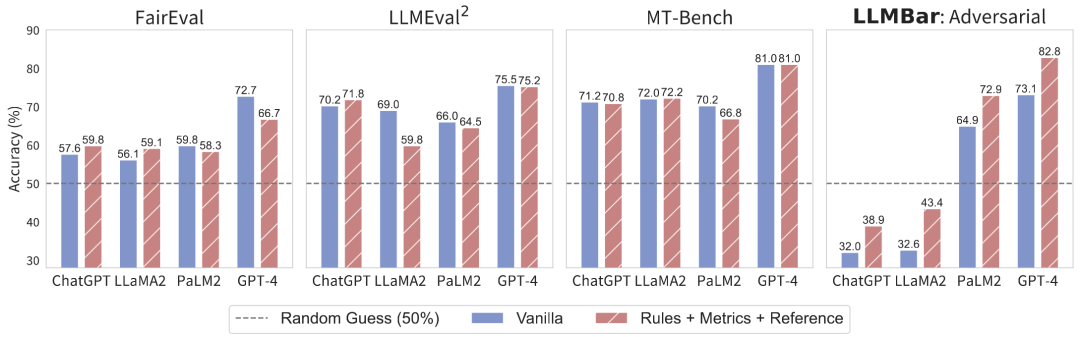
尽管 ChatGPT、LLaMA2-70B-Chat、PaLM2-bison 和 GPT-4 在其它元评估基准上的表现相近,但它们在 LLMBar (adversarial) 上的表现则大不相同 ——ChatGPT 和 LLaMA2 的分数甚至低于随机乱猜,而 GPT-4 的准确度则远远胜过其它任何评估器。
除了不同的 LLM,他们的研究还表明不同的 prompt 也对评估器非常重要。之前探索这一方向的研究包括:Wang et al., 2023 的《Large Language Models are not Fair Evaluators》提出采样多个解释并将它们聚合成一个最终判断;Zheng et al., 2023 的《Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena》则提出了一种参照引导式方式,即先让 LLM 评估器根据指令生成自己的输出,然后将其用作参照;还有一些论文表明:部署多个评估器(不同的 LLM 或 prompt)并让它们互相交流或合成它们的判断,可以提升评估器的准确度。作者团队则提出将这些方法组合起来:指标 + 参照 + 规则(如下所示)。
首先,使用 prompt 让 LLM 生成三个特定于指令的指标,也就是 rubric,并还使用 prompt 让 LLM 生成一个参照输出。然后,将这些指标和参照输入 LLM,显式地列出规则(比如重点是指令遵从,忽略位置偏见等),并让模型给出判断。相比于 AlpacaFarm 使用的最基本的 prompt,新的 prompt 可以显著提升在 LLMBar 上的评估器性能(GPT-4 在对抗集上的性能可提升 10%)。研究者还进行了更多消融研究,并还有另一些有趣的结果,比如这样一个反直觉的发现:思维链大多数时候都会损害评估器准确度。

开源指令微调数据、算法和模型的涌现是 2023 年 LLM 领域最激动人心的进展之一。这让研究者和开发者有机会将指令模型的训练、评估、互动和分析置于自己的完全控制之下(从参数到数据),之前这些都是黑盒。
过去几个月,这一领域也有点混乱,因为有数以百计的论文发布的结果使用了不同的数据、算法、基础模型甚至评估方法,使得人们难以对这些文献进行交叉比对。作者表示希望社区能很快聚合出一个标准的数据集 / 评估方法,让研究者能以一种更科学和可复现的方法开发出更好的指令微调模型。
博客地址:https://gaotianyu.xyz/blog/2023/11/30/instruction-tuning/
文章来自于微信公众号 “机器之心”,作者 “高天宇”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
