比LoRA还快50%的微调方法来了!一张3090性能超越全参调优,UIUC联合LMFlow团队提出LISA
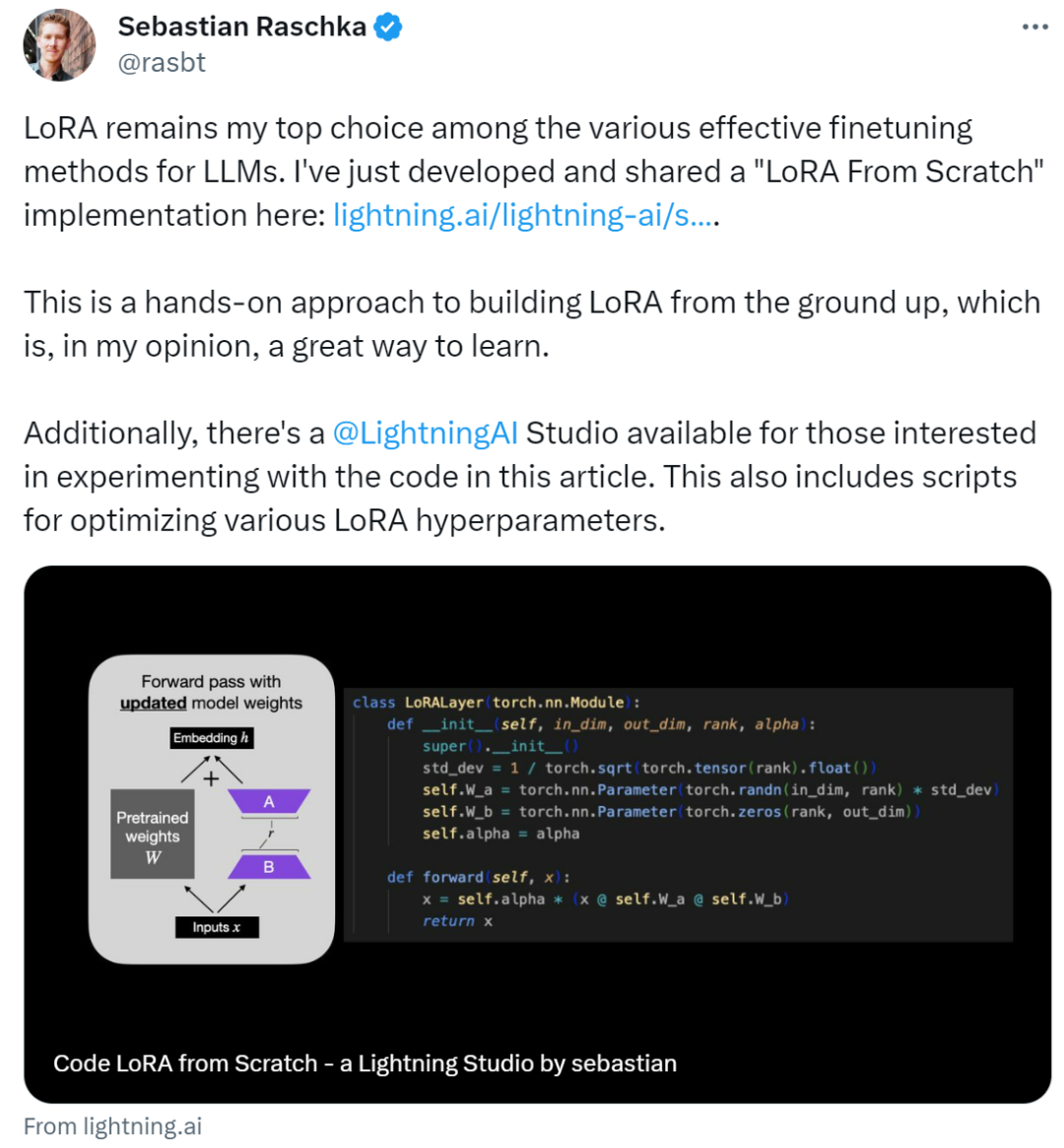
比LoRA还快50%的微调方法来了!一张3090性能超越全参调优,UIUC联合LMFlow团队提出LISA2022 年底,随着 ChatGPT 的爆火,人类正式进入了大模型时代。然而,训练大模型需要的时空消耗依然居高不下,给大模型的普及和发展带来了巨大困难。面对这一挑战,原先在计算机视觉领域流行的 LoRA 技术成功转型大模型 [1][2],带来了接近 2 倍的时间加速和理论最高 8 倍的空间压缩,将微调技术带进千家万户。
来自主题: AI技术研报
9854 点击 2024-04-01 15:45