

让大模型不再「巨无霸」,这是一份最新的大模型参数高效微调综述
让大模型不再「巨无霸」,这是一份最新的大模型参数高效微调综述近期,大语言模型、文生图模型等大规模 AI 模型迅猛发展。在这种形势下,如何适应瞬息万变的需求,快速适配大模型至各类下游任务,成为了一个重要的挑战。受限于计算资源,传统的全参数微调方法可能会显得力不从心,因此需要探索更高效的微调策略。
来自主题: AI技术研报
10874 点击 2024-04-28 15:07
近期,大语言模型、文生图模型等大规模 AI 模型迅猛发展。在这种形势下,如何适应瞬息万变的需求,快速适配大模型至各类下游任务,成为了一个重要的挑战。受限于计算资源,传统的全参数微调方法可能会显得力不从心,因此需要探索更高效的微调策略。
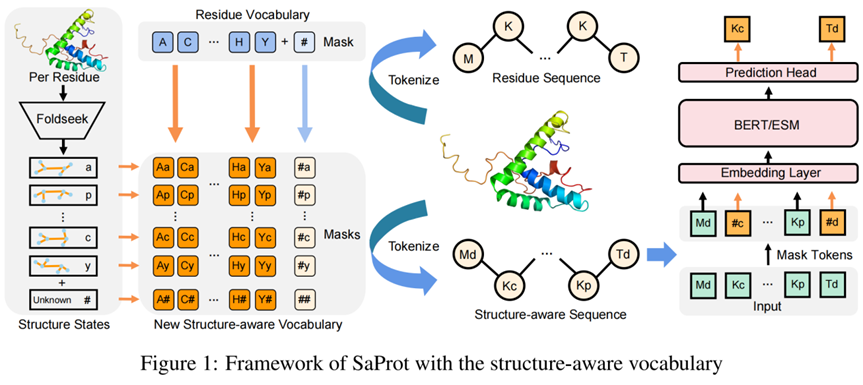
蛋白质结构相比于序列往往被认为更加具有信息量,因为其直接决定了蛋白质的功能
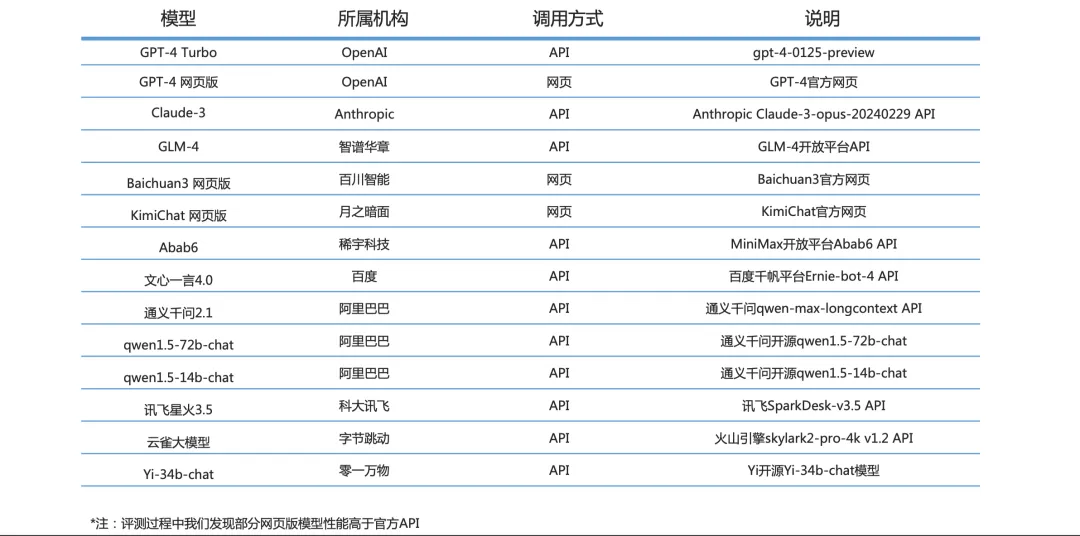
在2023年的「百模大战」中,众多实践者推出了各类模型,这些模型有的是原创的,有的是针对开源模型进行微调的;有些是通用的,有些则是行业特定的。如何能合理地评价这些模型的能力,成为关键问题
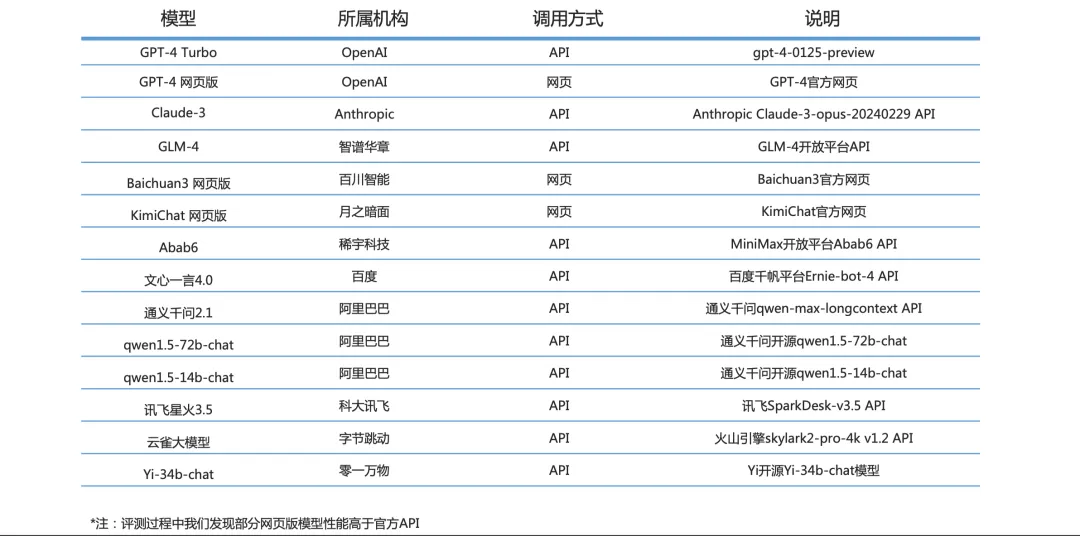
在 2023 年的 “百模大战” 中,众多实践者推出了各类模型,这些模型有的是原创的,有的是针对开源模型进行微调的;有些是通用的,有些则是行业特定的。如何能合理地评价这些模型的能力,成为关键问题。

OpenAI,去日本建办事处了。 而且,他们还发布了一个专门针对日语微调的GPT-4模型……

新版GPT-4是在Q*的输出上微调的在竞技场重回榜一的新版GPT-4 Turbo,成功再次踩中大家嗨点

随着大模型的参数量日益增长,微调整个模型的开销逐渐变得难以接受。 为此,北京大学的研究团队提出了一种名为 PiSSA 的参数高效微调方法,在主流数据集上都超过了目前广泛使用的 LoRA 的微调效果。

如果让你在互联网上给大模型选一本中文教材,你会去哪里取材?是知乎,是豆瓣,还是微博?一个研究团队为了构建高质量的中文指令微调数据集,对这些社交媒体进行了测试,想找到训练大模型最好的中文预料,结果答案保证让你大跌眼镜——
「被门夹过的核桃,还能补脑吗?」
离大谱了,弱智吧登上正经AI论文,还成了最好的中文训练数据??