

人类偏好就是尺!SPPO对齐技术让大语言模型左右互搏、自我博弈
人类偏好就是尺!SPPO对齐技术让大语言模型左右互搏、自我博弈Richard Sutton 在 「The Bitter Lesson」中做过这样的评价:「从70年的人工智能研究中可以得出的最重要教训是,那些利用计算的通用方法最终是最有效的,而且优势巨大。」
来自主题: AI技术研报
6866 点击 2024-05-12 11:26
Richard Sutton 在 「The Bitter Lesson」中做过这样的评价:「从70年的人工智能研究中可以得出的最重要教训是,那些利用计算的通用方法最终是最有效的,而且优势巨大。」

在上一篇文章「Unsloth微调Llama3-8B,提速44.35%,节省42.58%显存,最少仅需7.75GB显存」中,我们介绍了Unsloth,这是一个大模型训练加速和显存高效的训练框架,我们已将其整合到Firefly训练框架中,并且对Llama3-8B的训练进行了测试,Unsloth可大幅提升训练速度和减少显存占用。

大模型又又又被曝出安全问题!
堂堂开源之王Llama 3,原版上下文窗口居然只有……8k,让到嘴边的一句“真香”又咽回去了。

我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。

Llama 3的开源,再次掀起了一场大模型的热战,各家争相测评、对比模型的能力,也有团队在进行微调,开发衍生模型。
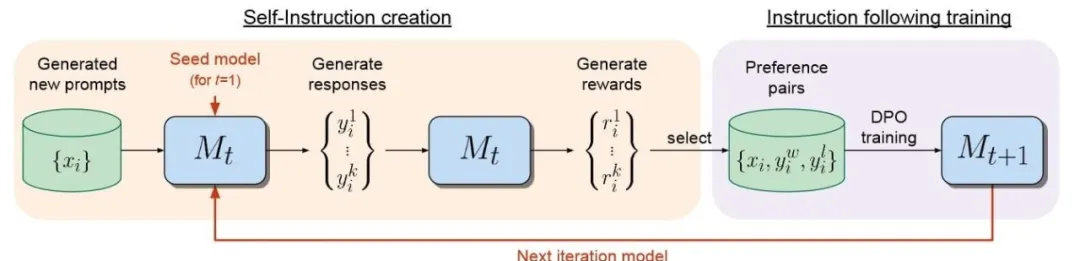
在大语言模型领域,微调是改进模型的重要步骤。伴随开源模型数量日益增多,针对LLM的微调方法同样在推陈出新。

对于小型语言模型(SLM)来说,数学应用题求解是一项很复杂的任务。

大型语言模型(LLM)往往会追求更长的「上下文窗口」,但由于微调成本高、长文本稀缺以及新token位置引入的灾难值(catastrophic values)等问题,目前模型的上下文窗口大多不超过128k个token
Llama 3诞生整整一周后,直接将开源AI大模型推向新的高度。