

字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果
字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。
来自主题: AI技术研报
9445 点击 2024-06-17 19:35
当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。
只用强化学习来微调,无需人类反馈,就能让多模态大模型学会做决策!

除了OpenAI自己,居然还有别人能用上GPT-4-Base版??
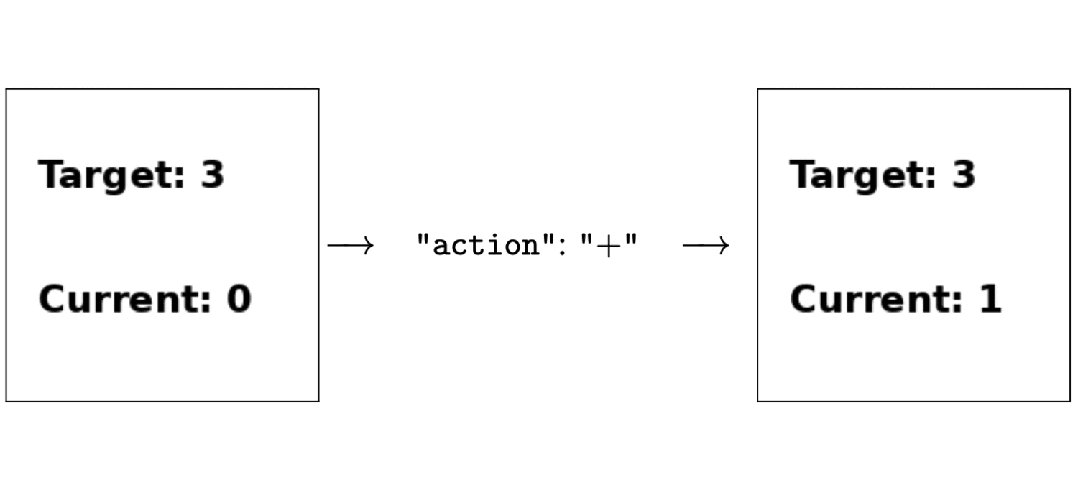
比斯坦福DPO(直接偏好优化)更简单的RLHF平替来了,来自陈丹琦团队。 该方式在多项测试中性能都远超DPO,还能让8B模型战胜Claude 3的超大杯Opus。 而且与DPO相比,训练时间和GPU消耗也都大幅减少。

美国东北大学的计算机科学家 David Bau 非常熟悉这样一个想法:计算机系统变得如此复杂,以至于很难跟踪它们的运行方式。

本文介绍了香港科技大学(广州)的一篇关于大模型高效微调(LLM PEFT Fine-tuning)的文章「Parameter-Efficient Fine-Tuning with Discrete Fourier Transform」

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。
本文由GreenBit.AI团队撰写,团队的核心成员来自德国哈索·普拉特纳计算机系统工程院开源技术小组。我们致力于推动开源社区的发展,倡导可持续的机器学习理念。我们的目标是通过提供更具成本效益的解决方案,使人工智能技术在环境和社会层面产生积极影响。
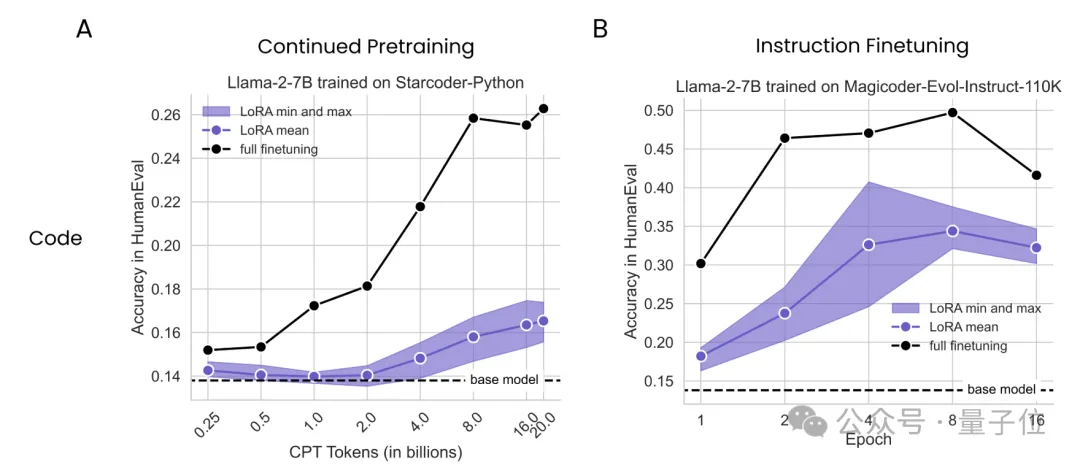
大数据巨头Databricks与哥伦比亚大学最新研究发现,在数学和编程任务上,LoRA干不过全量微调。

在《如何制造一个垂直领域大模型》一文中我们列举了几种开发垂直领域模型的方法。其中医疗、法律等专业是比较能体现模型垂直行业能力的,因此也深受各大厂商的重视。