# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
面对当前微调大模型主要依赖人类生成数据的普遍做法,谷歌 DeepMind 探索出了一种减少这种依赖的更高效方法。
如你我所见,大语言模型(LLM)正在改变深度学习的格局,在生成人类质量的文本和解决各种语言任务方面展现出了卓越的能力。虽然业界通过对人类收集的数据进行监督微调进一步提升了在具体任务上的性能,但获取高质量人类数据却面临着重大瓶颈。这对于要解决复杂问题的任务来说尤为明显,需要大量资源和专业知识。
怎么解决呢?模型生成得合成数据是一种有潜力的替代方案,只要能保证数据的质量,就能实现可扩展性和成本效益。
虽然 LLM 能够自我评估生成的数据,但在本文中,谷歌 DeepMind 探索了一种更简单的设置,将外部标量反馈信号用作每个生成样本的质量指标。

论文地址:https://arxiv.org/pdf/2312.06585.pdf
为了研究在模型生成数据上的训练,研究者考虑了一种简单但强大的语言模型自训练方法,仅需要两项功能,一是基于模型生成样本,二是利用评分机制对这些样本进行评估。
为了确保清晰度和一致性,研究者采用了一种强化自训练方法 ReST^????????,并证明该方法可以将期望最大化(expectation-maximization,EM)用于强化学习。具体来讲,ReST^????????在期望和最大化步骤之间交替进行。
研究者证实,ReST^????????及变体在增强各个领域的语言模型方面取得了成功,包括机器翻译、语义分析、偏好对齐和基础推理。
此外,以往工作主要将 ReST^????????用于相对较小的模型(最高 70 亿参数),对于较大模型的可扩展性受限。因此,本文旨在探究模型生成的合成数据与人类生成的数据在以下两个具有挑战性但研究较少领域的有效性和可扩展性,这两个领域分别是竞争水平数学解题(MATH)和代码生成(APPS)。
实证结果表明,当将 ReST^????????用于不同规模的 PaLM 2 模型时,在数学推理和代码生成任务中实现了显著的能力改进。与在人类编写数据上训练的模型相比,在模型生成的合成数据上微调的模型取得了更大的性能增益。有趣的是,超过了一定数量的 ReST^???????? 迭代后,性能会降低,这表明了在少量训练问题上可能会出现过拟合。
此外,使用 ReST^????????微调的模型提升了 pass@k 指标和多数投票性能。这些微调后的模型在相关但 held-out 的基准上也表现出了性能增强,包括数学题(GSM8K 和 Hungarian HS finals)、编码(HumanEval)和 Big-Bench Hard 任务。
总之,本文研究结果表明,具有反馈的自训练是减少对人类数据依赖的一种有潜力的方法。
首先,该研究基于 Dayan 和 Hinton 之前的研究,用语言模型描述了基于 EM 的强化学习框架。具体而言,他们先是定义了一个二进制最优变量 O,使得????(????= 1|????,????)∝????(????(????,????));然后对非递减函数 ???? : ℝ → ℝ+ ,实现最大化观察????= 1(获得高奖励),得到如下公式:
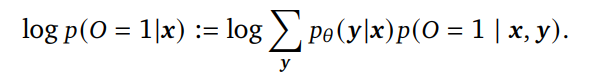
然而,求解上式中的序列 ???? 的和很棘手。因而本文考虑相对于参数 ???? 和变分分布 ????( ????|????) 最大化其 ELBO ????( ????????, ????),而不是最大化 log ????(???? = 1; ????)。具体来说:
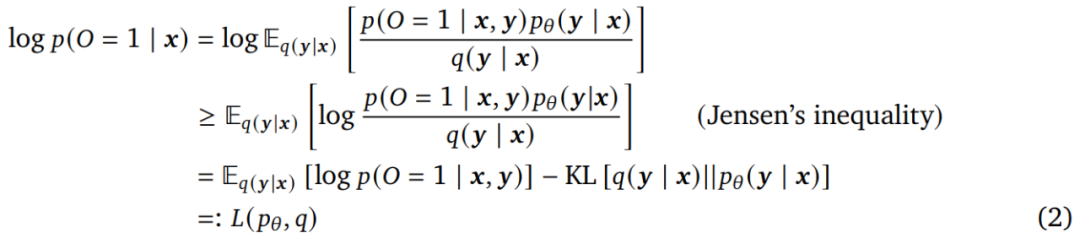
公式(2)中的 EM 算法在 E-step(Expectation) 和 M-step(Maximization)之间交替进行。
ReST^????????:受 EM 框架的启发,接下来论文讨论了 Gulcehre 等人提出的 ReST 方法的简化版本。为了清楚起见,本文将这种方法称为 ReST^????????,它将 RL pipeline 中的数据收集 (E-step) 和策略优化 (M-step) 进行解耦。如算法 1 所示:

生成(E-step):在此步骤中,该研究通过从当前策略 ???????? 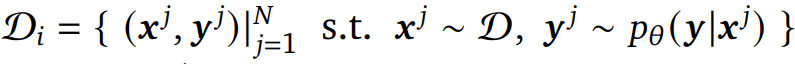 中采样输出序列来生成数据集
中采样输出序列来生成数据集![]() 。在这里,输入是从原始数据集
。在这里,输入是从原始数据集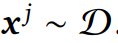 中重新采样的。然后使用二元奖励函数 ????(????, ????) 对
中重新采样的。然后使用二元奖励函数 ????(????, ????) 对![]() 中的输出序列进行评分。
中的输出序列进行评分。
改进(M-step):在第 ????步迭代中,该研究使用 E-step 中的新数据集![]() 来微调策略 ????????。不同于 Gulcehre 的研究,他们微调基本预训练语言模型,以最大限度地减少特定于任务的过度拟合并最大限度地减少与基本模型的偏差。为了进行微调,该研究最小化奖励加权负对数似然损失
来微调策略 ????????。不同于 Gulcehre 的研究,他们微调基本预训练语言模型,以最大限度地减少特定于任务的过度拟合并最大限度地减少与基本模型的偏差。为了进行微调,该研究最小化奖励加权负对数似然损失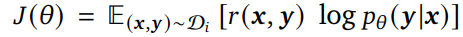 。一旦策略得到改进,就可以再次创建质量更好样本的新数据集。
。一旦策略得到改进,就可以再次创建质量更好样本的新数据集。
本文进行实验的主要目标是回答以下问题:
该研究使用 PaLM 2 模型和 Google Cloud 上的公共 API 进行实验,包括 PaLM 2-S (Bison)、PaLM 2-S* (Codey) 和 PaLM 2-L (Unicorn)。训练数据集采用 MATH 数据集和 APPS 数据集。
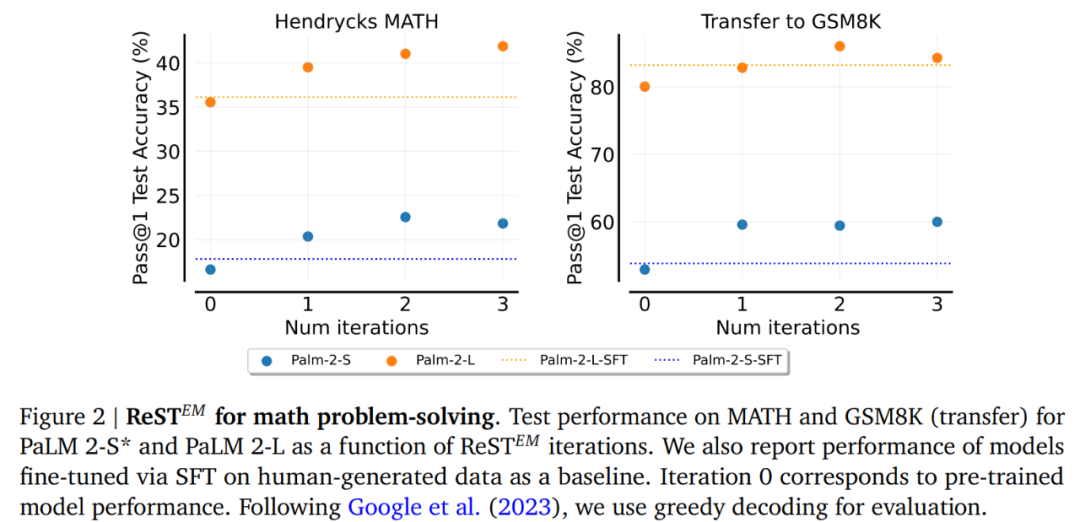
图 2 和图 3 分别显示了 ReST^????????在 MATH 和 APPS 数据集上训练的性能。可以得出 MATH 受益于 ReST^???????? 的多次迭代,无论是在 MATH 测试集上的性能还是迁移到 GSM8K 方面。另一方面可以看到 APPS 的大部分收益来自第一次迭代,而执行更多次迭代会导致 APPS 和 HumanEval 的性能下降。
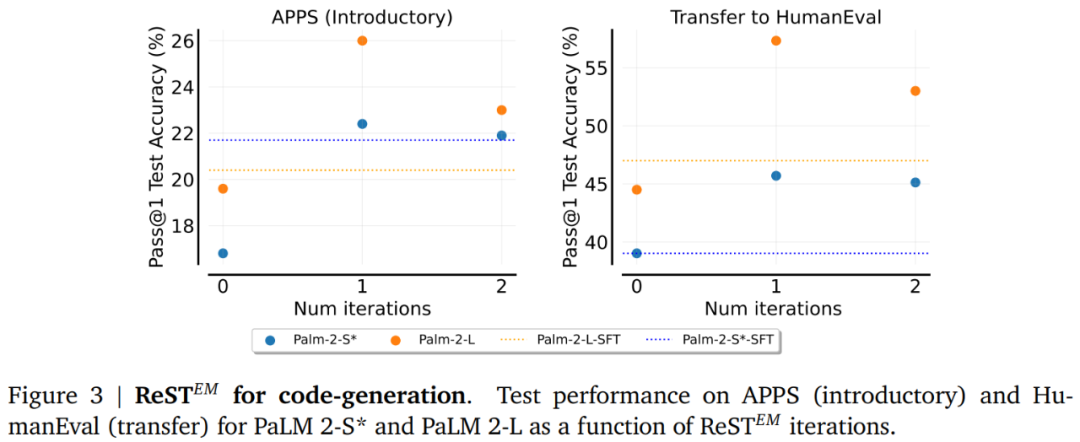
训练和测试性能的差距。图 4 显示,虽然训练集性能随着 ReST^????????迭代次数线性增加,但测试集性能却没有。对于 MATH,第一次迭代后测试性能改进很小,而对于 APPS,在第二次迭代中观察到性能回归。该研究猜测性能的回归可能是由于过度拟合造成的。由于 APPS 数据集的大小约为 MATH 数据集的三分之一,因此它更容易受到此问题的影响。
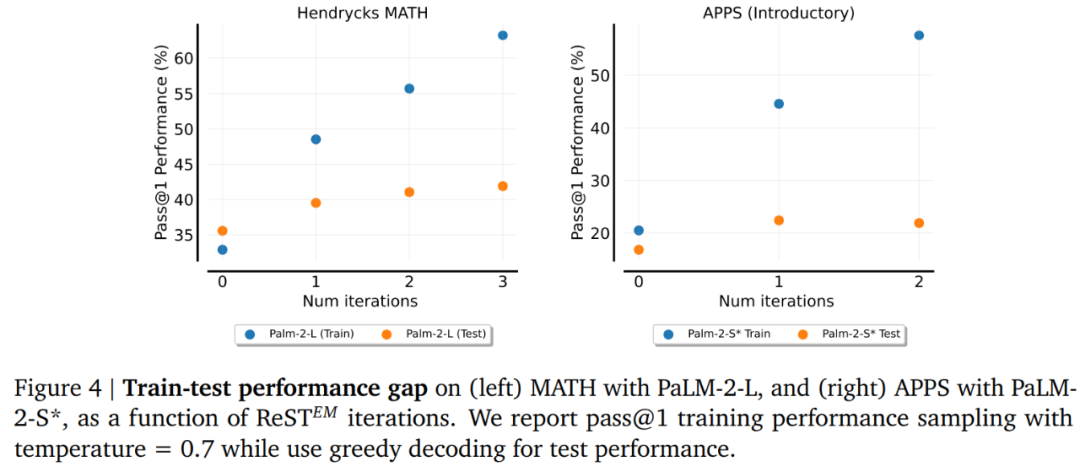
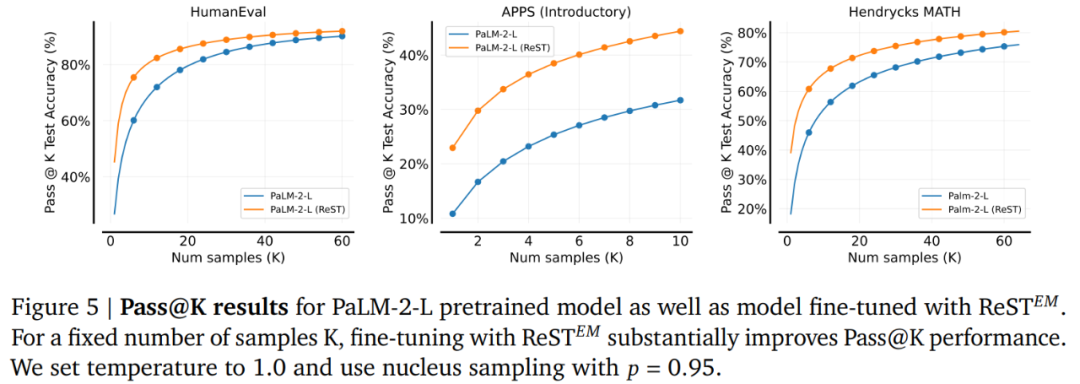
图 5 显示了 Palm-2-L 模型在 pass@K 指标上的性能。结果显示,微调后获得的 ReST^???????? 模型对于所有 K 值都更强,其中性能差距通常在 K=1 时最大。
文章来自于微信公众号 “机器之心”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
