
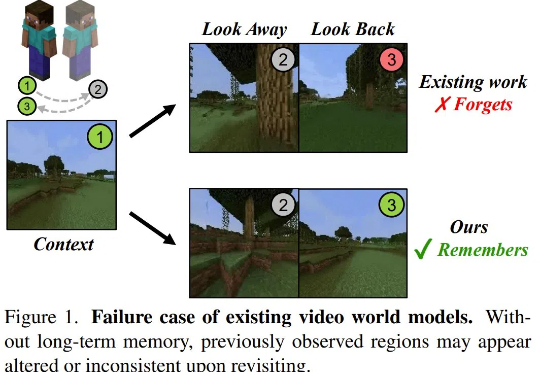
SSM+扩散模型,竟造出一种全新的「视频世界模型」
SSM+扩散模型,竟造出一种全新的「视频世界模型」当状态空间模型遇上扩散模型,对世界模型意味着什么?
来自主题: AI技术研报
9550 点击 2025-05-31 16:40
当状态空间模型遇上扩散模型,对世界模型意味着什么?

近日,NVIDIA 联合香港大学、MIT 等机构重磅推出 Fast-dLLM,以无需训练的即插即用加速方案,实现了推理速度的突破!通过创新的技术组合,在不依赖重新训练模型的前提下,该工作为扩散模型的推理加速带来了突破性进展。本文将结合具体技术细节与实验数据,解析其核心优势。

普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。

谷歌又放新大招了,将图像生成常用的“扩散技术”引入语言模型,12秒能生成1万tokens。
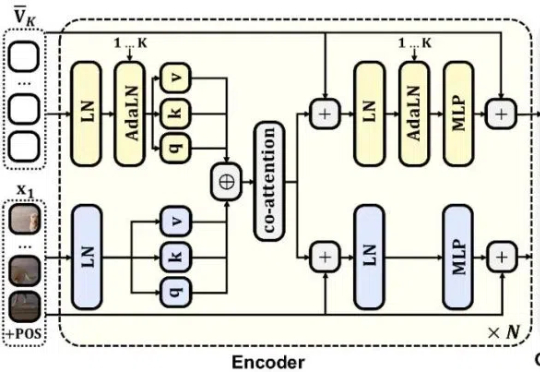
自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。

最近,Google 推出了一个可以精准控制画面中光影的项目 —— LightLab。 它让用户能够从单张图像实现对光源的细粒度参数化控制, 可以改变可见光源的强度和颜色、环境光的强度,并且能够将虚拟光源插入场景中。

OpenAI GPT-4o发布强大图片生成能力后,业界对大模型生图能力的探索向全模态方向倾斜,训练全模态模型成研发重点。

扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。
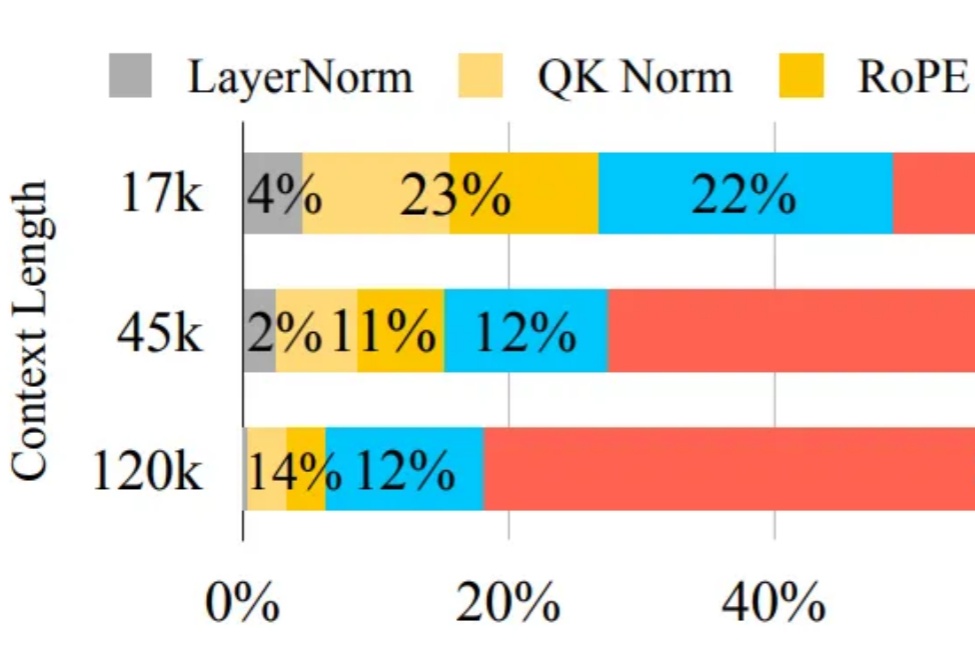
自 OpenAI 发布 Sora 以来,AI 视频生成技术进入快速爆发阶段。凭借扩散模型强大的生成能力,我们已经可以看到接近现实的视频生成效果。但在模型逼真度不断提升的同时,速度瓶颈却成为横亘在大规模应用道路上的最大障碍。

扩散模型(Diffusion Models, DMs)如今已成为文本生成图像的核心引擎。凭借惊艳的图像生成能力,它们正悄然改变着艺术创作、广告设计、乃至社交媒体内容的生产方式。