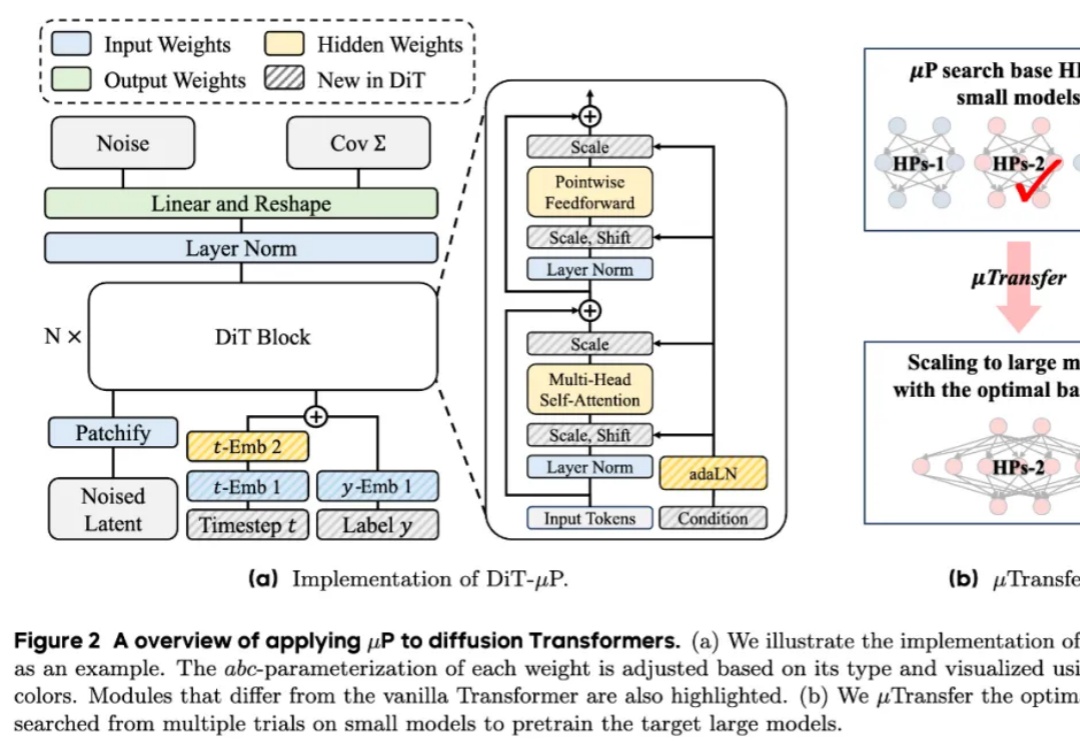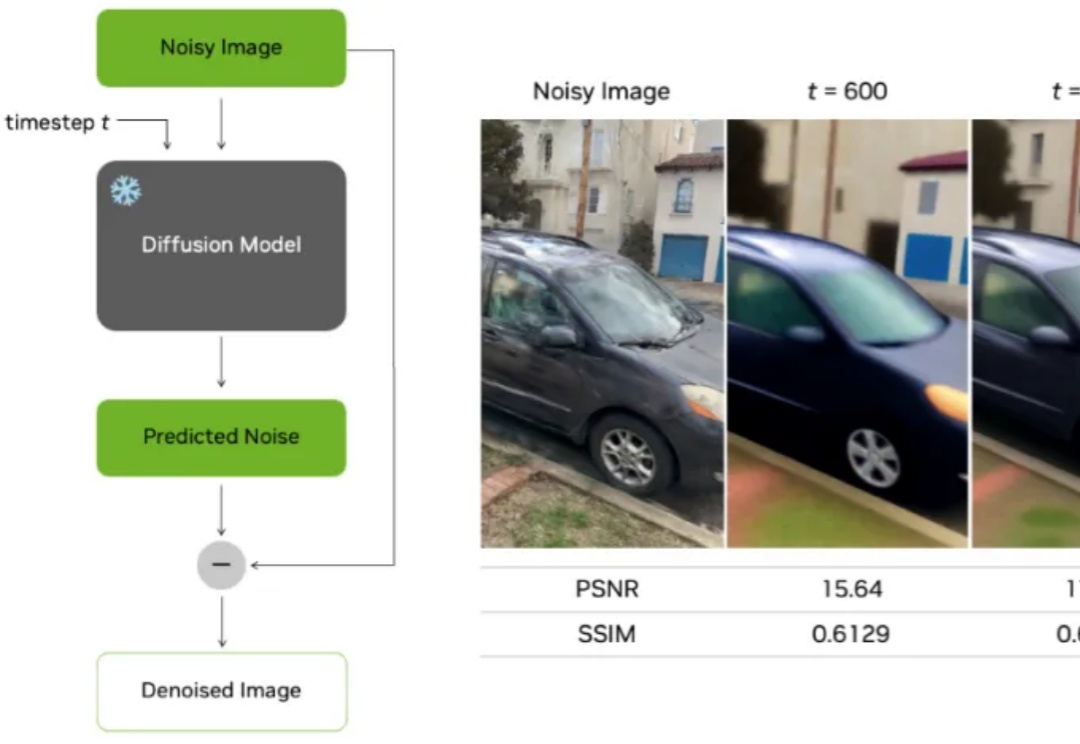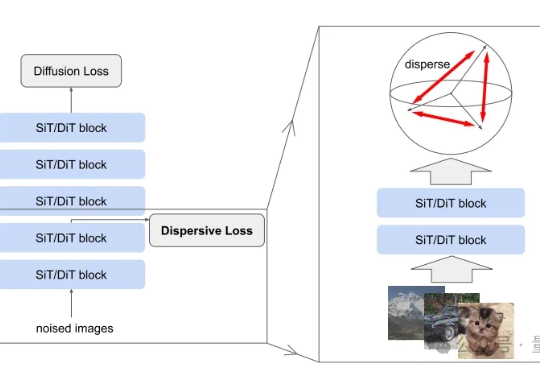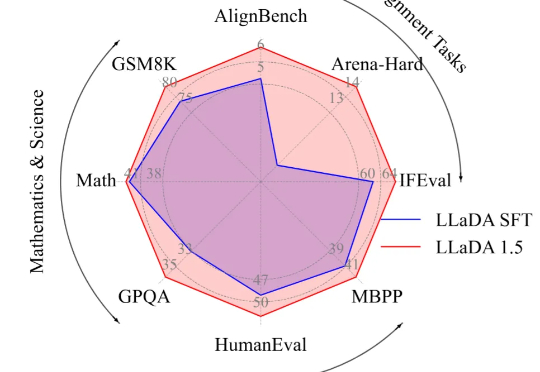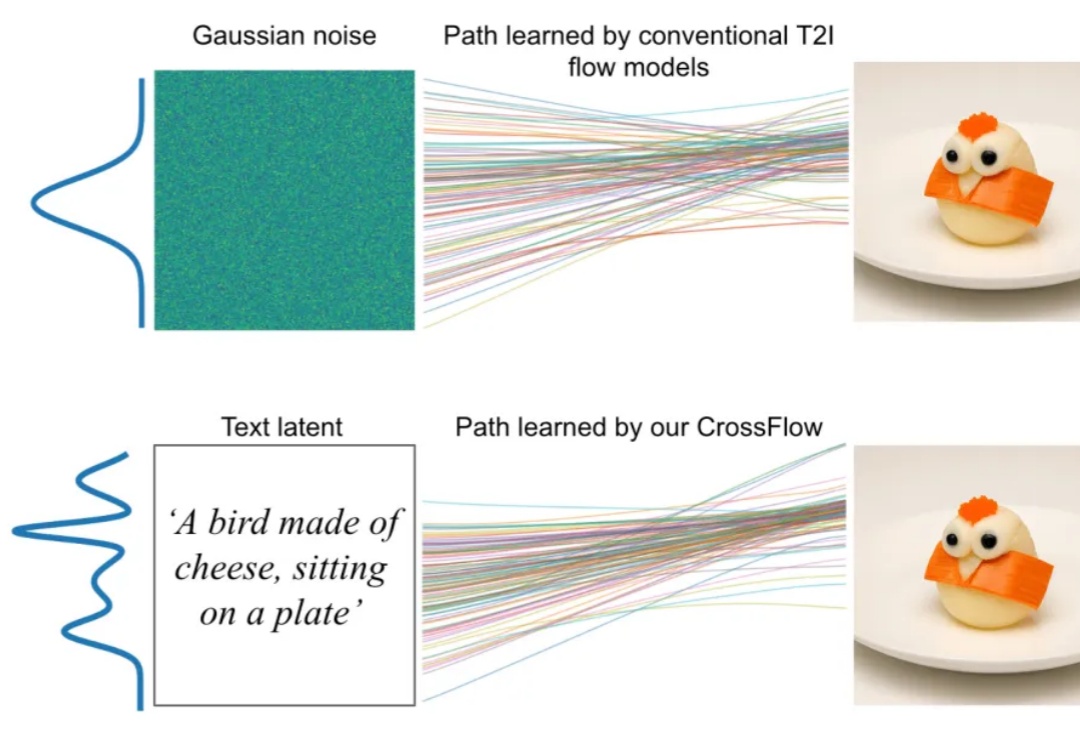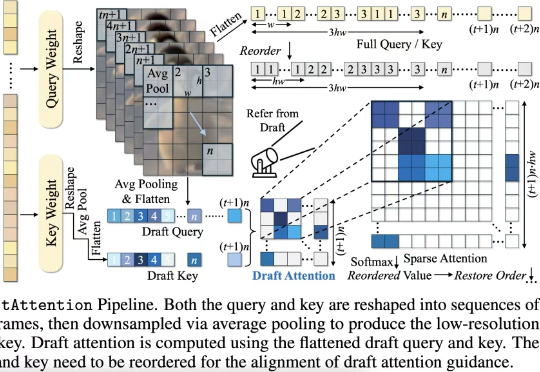
无需训练,即插即用,2倍GPU端到端推理加速——视频扩散模型加速方法DraftAttention
无需训练,即插即用,2倍GPU端到端推理加速——视频扩散模型加速方法DraftAttention在高质量视频生成任务中,扩散模型(Diffusion Models)已经成为主流。然而,随着视频长度和分辨率的提升,Diffusion Transformer(DiT)模型中的注意力机制计算量急剧增加,成为推理效率的最大瓶颈。
来自主题: AI技术研报
8187 点击 2025-06-28 16:09