面向6G环境感知通信!西电开源3Dx3D无线电地图数据集与生成式基准框架
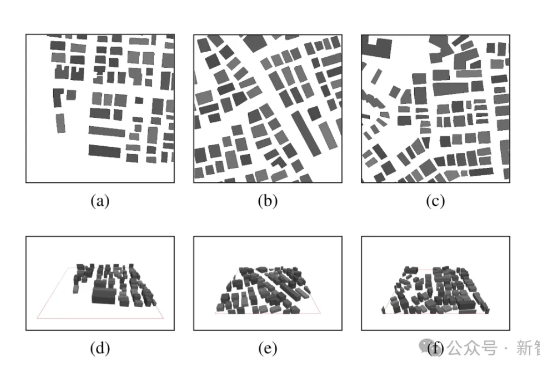
面向6G环境感知通信!西电开源3Dx3D无线电地图数据集与生成式基准框架当前环境感知通信正逐步成为第六代移动通信系统(6G)的核心使能技术之一。为支撑其在复杂三维环境下的部署需求,西安电子科技大学、香港中文大学(深圳)和加拿大滑铁卢大学的研究团队联合提出了一个面向6G的高分辨率多模态三维无线电图谱数据集UrbanRadio3D,并构建了基于扩散模型的三维无线电图生成框架RadioDiff-3D。
来自主题: AI技术研报
8240 点击 2025-08-05 16:07