

北大团队引领3D生成与对齐革新:OctGPT打破扩散模型垄断
北大团队引领3D生成与对齐革新:OctGPT打破扩散模型垄断最近,北京大学陈宝权教授带领团队在三维形状生成和三维数据对齐方面取得新的突破。在三维数据生成方面,团队提出了3D自回归模型新范式,有望打破3D扩散模型在三维生成方面的垄断地位。
来自主题: AI技术研报
9802 点击 2025-04-25 10:08
最近,北京大学陈宝权教授带领团队在三维形状生成和三维数据对齐方面取得新的突破。在三维数据生成方面,团队提出了3D自回归模型新范式,有望打破3D扩散模型在三维生成方面的垄断地位。
AI虚拟人模型架构从CNN、GANs演进至Transformer+扩散模型,实现从单一面部驱动到半身/全身动态生成的跨越,口型同步与多模态协同表现显著提升。
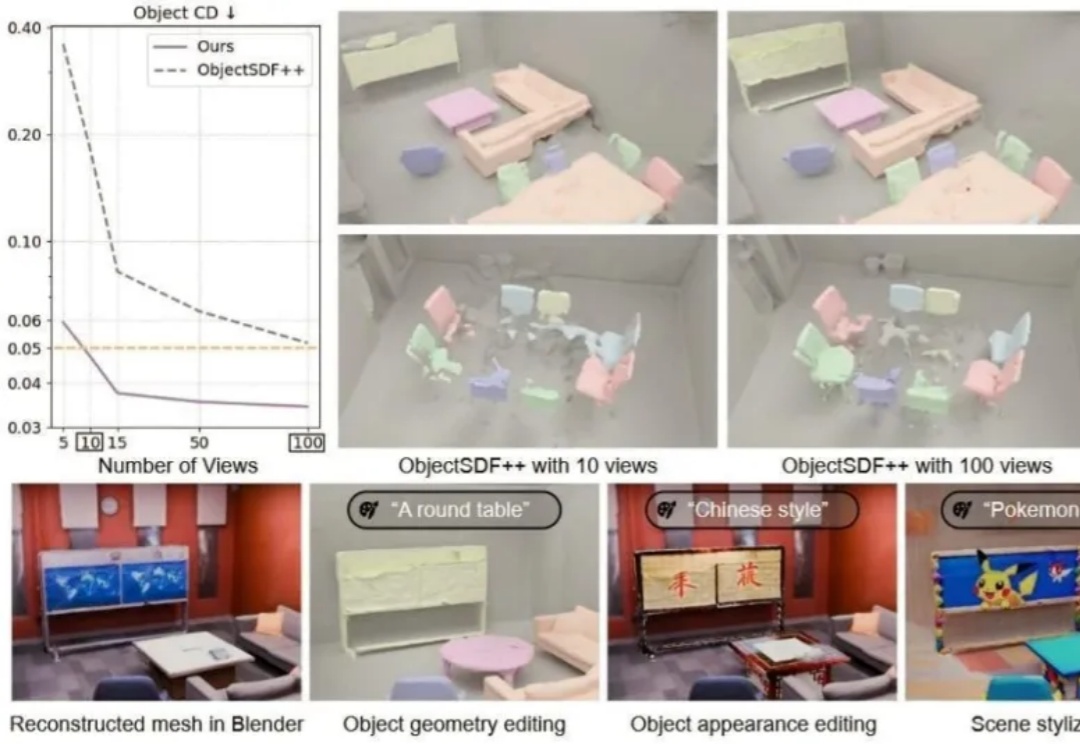
你是否设想过,仅凭几张随手拍摄的照片,就能重建出一个完整、细节丰富且可自由交互的3D场景?

基于Transformer的自回归架构在语言建模上取得了显著成功,但在图像生成领域,扩散模型凭借强大的生成质量和可控性占据了主导地位。

最近,来自大连理工和莫纳什大学的团队提出了物理真实的视频生成框架 VLIPP。通过利用视觉语言模型来将物理规律注入到视频扩散模型的方法来提升视频生成中的物理真实性。

虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。

随着 VR/AR、游戏娱乐、自动驾驶等领域对 3D 场景生成的需求不断攀升,从稀疏视角重建 3D 场景已成为一大热点课题。
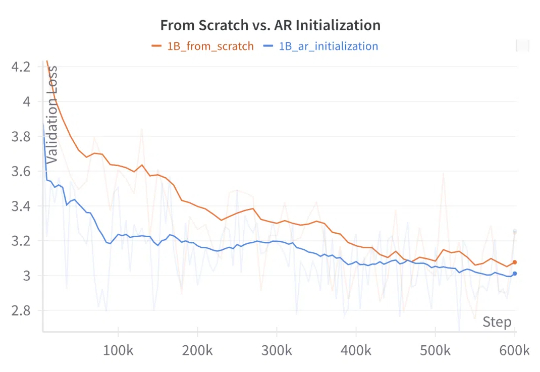
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。
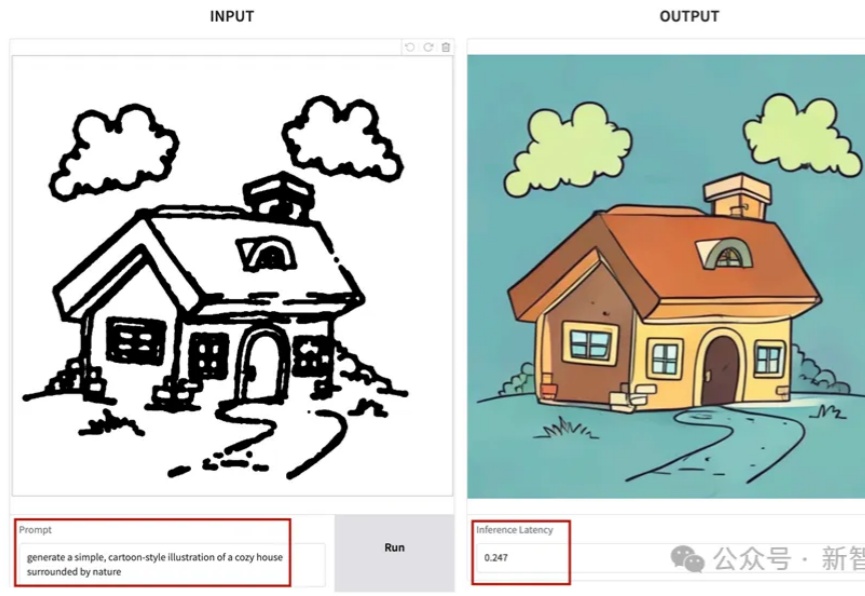
SANA-Sprint是一个高效的蒸馏扩散模型,专为超快速文本到图像生成而设计。通过结合连续时间一致性蒸馏(sCM)和潜空间对抗蒸馏(LADD)的混合蒸馏策略,SANA-Sprint在一步内实现了7.59 FID和0.74 GenEval的最先进性能。SANA-Sprint仅需0.1秒即可在H100上生成高质量的1024x1024图像,在速度和质量的权衡方面树立了新的标杆。