

视频可以精准控制了!一句话给熊戴眼镜的那种,扩散模型立功,浙大悉尼科技大学出品 | ICLR 2025
视频可以精准控制了!一句话给熊戴眼镜的那种,扩散模型立功,浙大悉尼科技大学出品 | ICLR 2025如何让你的模型能感知到视频的粒度,随着你的心思想编辑哪就编辑哪呢?
来自主题: AI技术研报
8480 点击 2025-03-26 09:36
如何让你的模型能感知到视频的粒度,随着你的心思想编辑哪就编辑哪呢?

它名为 Uni-3DAR,来自深势科技、北京科学智能研究院及北京大学,是一个通过自回归下一 token 预测任务将 3D 结构的生成与理解统一起来的框架。据了解,Uni-3DAR 是世界首个此类科学大模型。并且其作者阵容非常强大,包括了深势科技 AI 算法负责人柯国霖、中国科学院院士鄂维南、深势科技创始人兼首席科学家和北京科学智能研究院院长张林峰等。

从微观世界的分子与材料结构、到宏观世界的几何与空间智能,创建和理解 3D 结构是推进科学研究的重要基石。3D 结构不仅承载着丰富的物理与化学信息,也可为科学家提供解构复杂系统、进行模拟预测和跨学科创新的重要工具。

块离散去噪扩散语言模型(BD3-LMs)结合自回归模型和扩散模型的优势,解决了现有扩散模型生成长度受限、推理效率低和生成质量低的问题。通过块状扩散实现任意长度生成,利用键值缓存提升效率,并通过优化噪声调度降低训练方差,达到扩散模型中最高的预测准确性,同时生成效率和质量优于其他扩散模型。

近年来,扩散模型在图像与视频合成领域展现出强大能力,为图像动画技术的发展带来了新的契机。特别是在人物图像动画方面,该技术能够基于一系列预设姿态驱动参考图像,使其动态化,从而生成高度可控的人体动画视频。

文本到图像(Text-to-Image, T2I)生成任务近年来取得了飞速进展,其中以扩散模型(如 Stable Diffusion、DiT 等)和自回归(AR)模型为代表的方法取得了显著成果。然而,这些主流的生成模型通常依赖于超大规模的数据集和巨大的参数量,导致计算成本高昂、落地困难,难以高效地应用于实际生产环境。
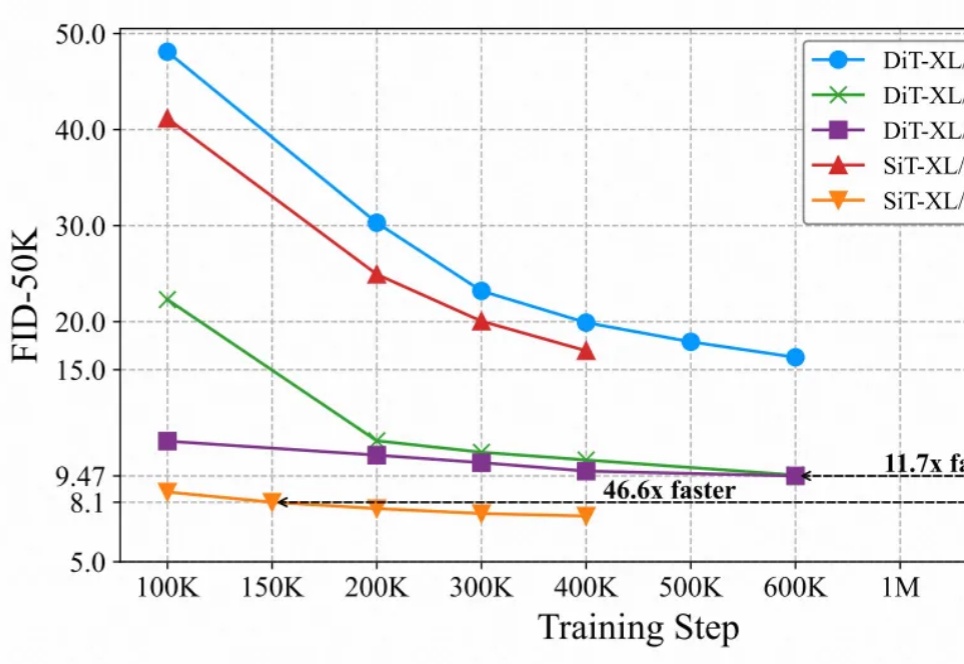
最近的研究强调了扩散模型与表征学习之间的相互作用。扩散模型的中间表征可用于下游视觉任务,同时视觉模型表征能够提升扩散模型的收敛速度和生成质量。然而,由于输入不匹配和 VAE 潜在空间的使用,将视觉模型的预训练权重迁移到扩散模型中仍然具有挑战性。

北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制
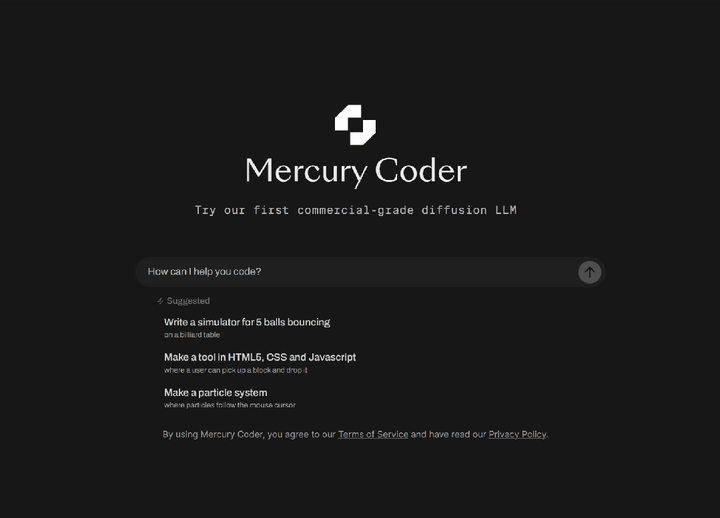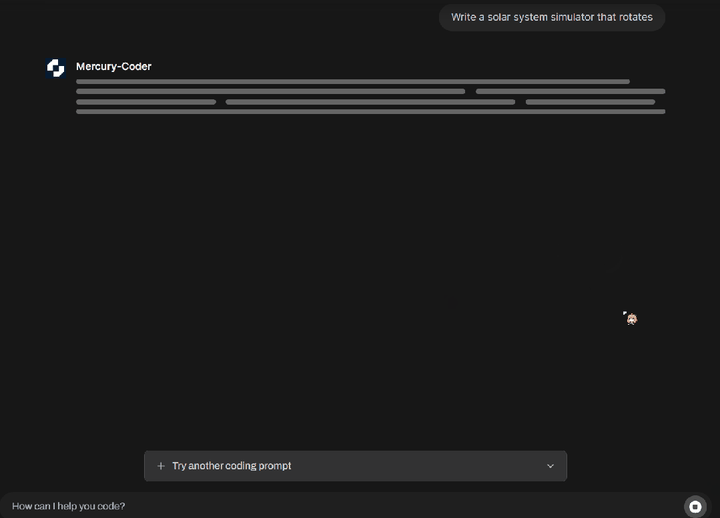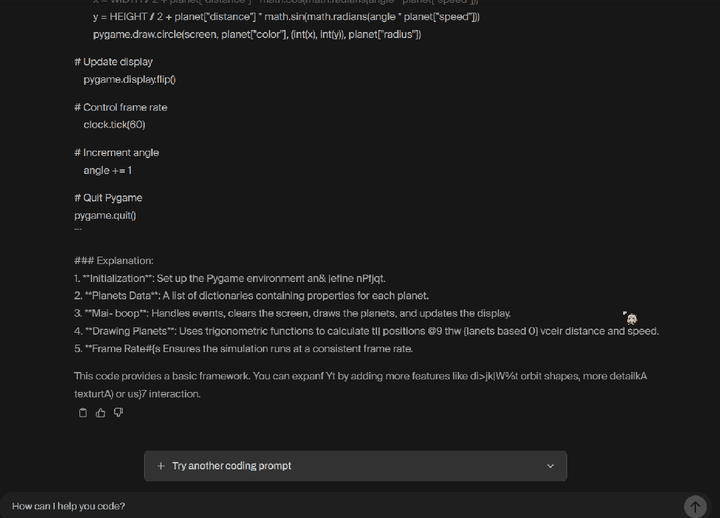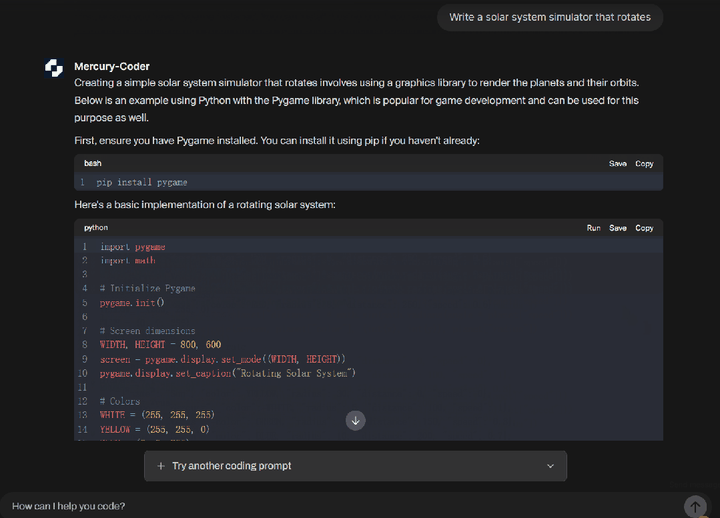
2025年2月27日,由前扩散模型领域顶尖研究者创立的Inception Labs正式发布了全球首个商业级扩散大语言模型(dLLM)——“Mercury”。这一里程碑式产品不仅在生成速度、硬件效率和成本控制上实现突破,更标志着自然语言处理技术从自回归(Autoregressive)范式向扩散(Diffusion)范式的重大跃迁。

近年来大语言模型(LLM)的迅猛发展正推动人工智能迈向多模态融合的新纪元。然而,现有主流多模态大模型(MLLM)依赖复杂的外部视觉模块(如 CLIP 或扩散模型),导致系统臃肿、扩展受限,成为跨模态智能进化的核心瓶颈。