
斯坦福2025 AI指数出炉!中美AI终极对决差距仅剩0.3%,DeepSeek领衔
斯坦福2025 AI指数出炉!中美AI终极对决差距仅剩0.3%,DeepSeek领衔2025年斯坦福HAI报告重磅发布,456页深度剖析全球AI领域的最新趋势:中美顶级模型性能差距缩至0.3%,以DeepSeek为代表的模型强势崛起,逼近闭源巨头;推理成本暴降,小模型性能飙升,AI正变得更高效、更普惠。
来自主题: AI资讯
10819 点击 2025-04-08 16:45
 搜索
搜索
2025年斯坦福HAI报告重磅发布,456页深度剖析全球AI领域的最新趋势:中美顶级模型性能差距缩至0.3%,以DeepSeek为代表的模型强势崛起,逼近闭源巨头;推理成本暴降,小模型性能飙升,AI正变得更高效、更普惠。

OpenAI o3推理成本从3000美元飙至3万美元,暴增10倍。o3-high靠暴力试错生成4300万字解题,却被ARC-AGI「除名」。

「国产大模型 + 国产引擎 + 国产芯片」的完整技术闭环正在加速形成。
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。

AI模型的训练和推理成本在过去18个月内大幅下降,达到180倍的成本降低。这一趋势推动了更多开源项目的涌现。
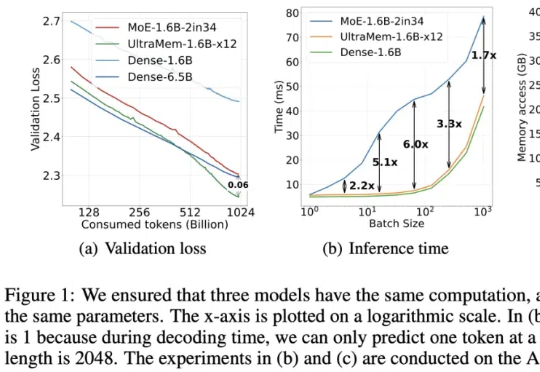
字节出了个全新架构,把推理成本给狠狠地打了下去!推理速度相比MoE架构提升2-6倍,推理成本最高可降低83%。

SANA 1.5是一种高效可扩展的线性扩散Transformer,针对文本生成图像任务进行了三项创新:高效的模型增长策略、深度剪枝和推理时扩展策略。这些创新不仅大幅降低了训练和推理成本,还在生成质量上达到了最先进的水平。

外媒SemiAnalysis的一篇深度长文,全面分析了DeepSeek背后的秘密——不是「副业」项目、实际投入的训练成本远超600万美金、150多位高校人才千万年薪,攻克MLA直接让推理成本暴降......

来了,国内首个对标AlphaFold3的产品—— HelixFold3,来自百度智能云与百度螺旋桨团队。
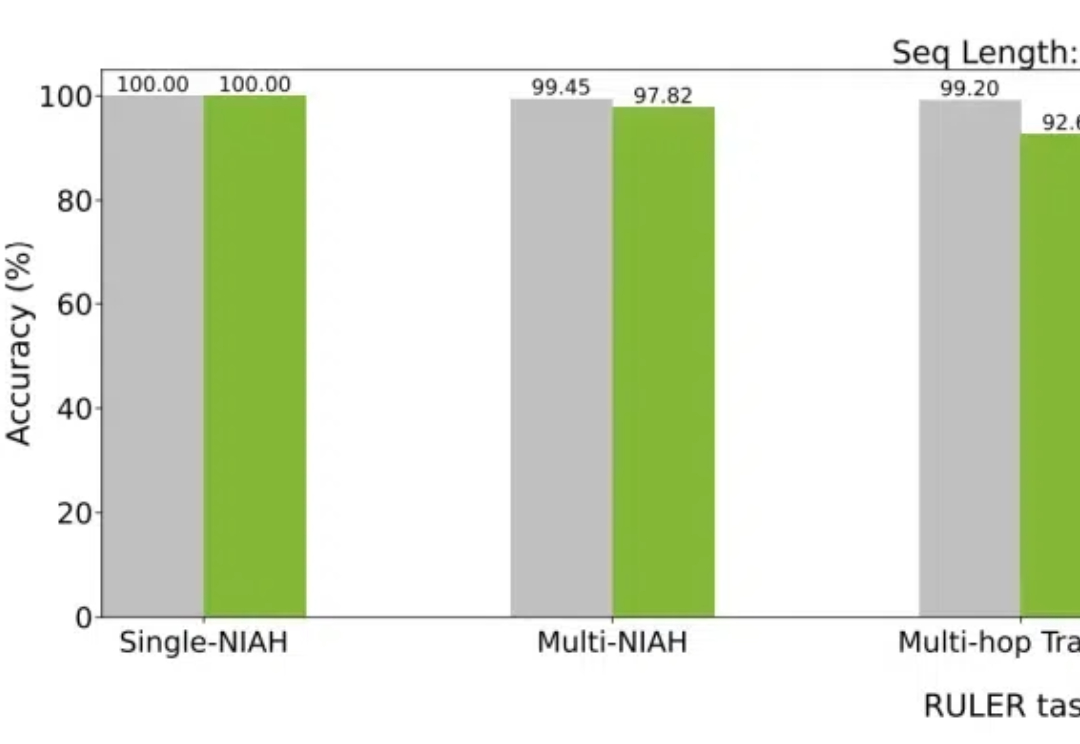
大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。